
The end of dramatic exponential growth in single-processor performance marks the end of the dominance of the single microprocessor in computing. The era of sequential computing must give way to a new era in which parallelism is at the forefront. Although important scientific and engineering challenges lie ahead, this is an opportune time for innovation in programming systems and computing architectures. We have already begun to see diversity in computer designs to optimize for such considerations as power and throughput. The next generation of discoveries is likely to require advances at both the hardware and software levels of computing systems.
There is no guarantee that we can make parallel computing as common and easy to use as yesterday’s sequential single-processor computer systems, but unless we aggressively pursue efforts suggested by the recommendations below, it will be “game over” for growth in computing performance. If parallel programming and related software efforts fail to become widespread, the development of exciting new applications that drive the computer industry will stall; if such innovation stalls, many other parts of the economy will follow suit.
This report of the Committee on Sustaining Growth in Computing Performance describes the factors that have led to the future limitations on growth for single processors based on complementary metal oxide semiconductor (CMOS) technology. The recommendations that follow are aimed at supporting and focusing research, development, and educa-
tion in parallel computing, architectures, and power to sustain growth in computer performance and enjoy the next level of benefits to society.
SOCIETAL DEPENDENCE ON GROWTH IN COMPUTING PERFORMANCE
Information technology (IT) has transformed how we work and live—and has the potential to continue to do so. IT helps to bring distant people together, coordinate disaster response, enhance economic productivity, enable new medical diagnoses and treatments, add new efficiencies to our economy, improve weather prediction and climate modeling, broaden educational access, strengthen national defense, advance science, and produce and deliver content for education and entertainment.
Those transformations have been made possible by sustained improvements in the performance of computers. We have been living in a world where the cost of information processing has been decreasing exponentially year after year. The term Moore’s law, which originally referred to an empirical observation about the most economically favorable rate for industry to increase the number of transistors on a chip, has come to be associated, at least popularly, with the expectation that microprocessors will become faster, that communication bandwidth will increase, that storage will become less expensive, and, more broadly, that computers will become faster. Most notably, the performance of individual computer processors increased on the order of 10,000 times over the last 2 decades of the 20th century without substantial increases in cost or power consumption.
Although some might say that they do not want or need a faster computer, computer users as well as the computer industry have in reality become dependent on the continuation of that performance growth. U.S. leadership in IT depends in no small part on taking advantage of the leading edge of computing performance. The IT industry annually generates a trillion dollars of revenue and has even larger indirect effects throughout society. This huge economic engine depends on a sustained demand for IT products and services; use of these products and services in turn fuels demand for constantly improving performance. More broadly, virtually every sector of society—manufacturing, financial services, education, science, government, the military, entertainment, and so on—has become dependent on continued growth in computing performance to drive industrial productivity, increase efficiency, and enable innovation. The performance achievements have driven an implicit, pervasive expectation that future IT advances will occur as an inevitable continuation of the stunning advances that IT has experienced over the last half-century.
Finding: The information technology sector itself and most other sectors of society—for example, manufacturing, financial and other services, science, engineering, education, defense and other government services, and entertainment—have grown dependent on continued growth in computing performance.
Software developers themselves have come to depend on that growth in performance in several important ways, including:
- Developing applications that were previously infeasible, such as real-time video chat;
- Adding visible features and ever more sophisticated interfaces to existing applications;
- Adding “hidden” (nonfunctional) value—such as improved security, reliability, and other trustworthiness features—without degrading the performance of existing functions;
- Using higher-level abstractions, programming languages, and systems that require more computing power but reduce development time and improve software quality by making the development of correct programs and the integration of components easier; and
- Anticipating performance improvements and creating innovative, computationally intensive applications even before the required performance is available at low cost.
The U.S. computing industry has been adept at taking advantage of increases in computing performance, allowing the United States to be a moving and therefore elusive target—innovating and improvising faster than anyone else. If computer capability improvements stall, the U.S. lead will erode, as will the associated industrial competitiveness and military advantage.
Another consequence of 5 decades of exponential growth in performance has been the rise and dominance of the general-purpose microprocessor that is the heart of all personal computers. The dominance of the general-purpose microprocessor has stemmed from a virtuous cycle of (1) economies of scale wherein each generation of computers has been both faster and less expensive than the previous one, and (2) software correctness and performance portability—current software continues to run and to run faster on the new computers, and innovative applications can also run on them. The economies of scale have resulted from Moore’s law scaling of transistor density along with innovative approaches to harnessing effectively all the new transistors that have become available. Portability has been preserved by keeping instruction sets compatible over many
generations of microprocessors even as the underlying microprocessor technology saw substantial enhancements, allowing investments in software to be amortized over long periods.
The success of this virtuous cycle dampened interest in the development of alternative computer and programming models. Even though alternative architectures might have been technically superior (faster or more power-efficient) in specific domains, if they did not offer software compatibility they could not easily compete in the marketplace and were easily overtaken by the ever-improving general-purpose processors available at a relatively low cost.
CONSTRAINTS ON GROWTH IN SINGLE-PROCESSOR PERFORMANCE
By the 2000s, however, it had become apparent that processor performance growth was facing two major constraints. First, the ability to increase clock speeds has run up against power limits. The densest, highest-performance, and most power-efficient integrated circuits are constructed from CMOS technology. By 2004, the long-fruitful strategy of scaling down the size of CMOS circuits, reducing the supply voltage and increasing the clock rate was becoming infeasible. Since a chip’s power consumption is proportional to the clock speed times the supply voltage squared, the inability to continue to lower the supply voltage halted the ability to increase the clock speed without increasing power dissipation. The resulting power consumption exceeded the few hundred watts per chip level that can practically be dissipated in a mass-market computing device as well as the practical limits for mobile, battery-powered devices. The ultimate consequence has been that growth in single-processor performance has stalled (or at least is being increased only marginally over time).
Second, efforts to improve the internal architecture of individual processors have seen diminishing returns. Many advances in the architecture of general-purpose sequential processors, such as deeper pipelines and speculative execution, have contributed to successful exploitation of increasing transistor densities. Today, however, there appears to be little opportunity to significantly increase performance by improving the internal structure of existing sequential processors. Figure S.1 graphically illustrates these trends and the slowdown in the growth of processor performance, clock speed, and power since around 2004. In contrast, it also shows the continued, exponential growth in the number of transistors per chip. The original Moore’s law projection of increasing transistors per chip continues unabated even as performance has stalled. The 2009 edition of
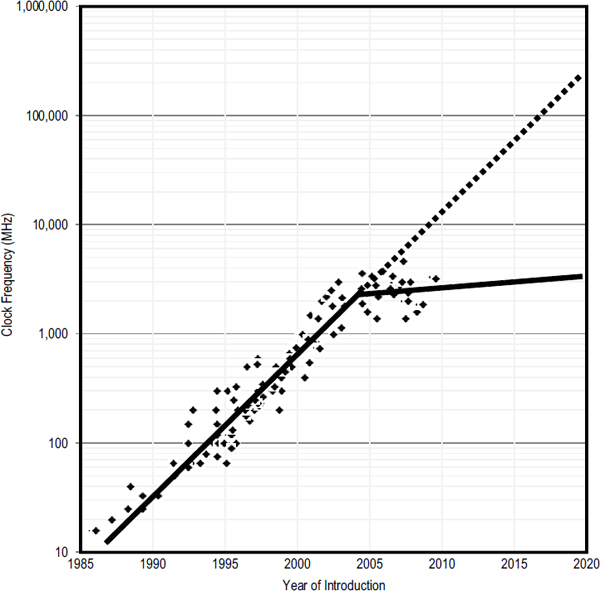
FIGURE S.1 Historical growth in single-processor performance and a forecast of processor performance to 2020, based on the ITRS roadmap. The dashed line represents expectations if single-processor performance had continued its historical trend. The vertical scale is logarithmic. A break in the growth rate at around 2004 can be seen. Before 2004, processor performance was growing by a factor of about 100 per decade; since 2004, processor performance has been growing and is forecasted to grow by a factor of only about 2 per decade. An expectation gap is apparent. In 2010, this expectation gap for single-processor performance is about a factor of 10; by 2020, it will have grown to a factor of 100. Most sectors of the economy and society implicitly or explicitly expect computing to deliver steady, exponentially increasing performance, but as this graph illustrates, traditional single-processor computing systems will not match expectations. Note that this graph plots processor clock rate as the measure of processor performance. Other processor design choices impact processor performance, but clock rate is a dominant processor performance determinant.
the International Technology Roadmap for Semiconductors (ITRS)1 predicts the continued growth of transistors/chips for the next decade, but it will probably not be possible to continue to increase the transistor density (number of transistors per unit area) of CMOS chips at the current pace beyond the next 10 to 15 years. Figure S.1 shows the historical growth in single-processor performance and a forecast of processor performance to 2020 based on the ITRS roadmap. A dashed line represents what could have been expected if single-processor performance had continued on its historical trend. By 2020, however, a large “expectation gap” is apparent for single processors. This report explores the implications of that gap and offers a way to begin to bridging it.
Finding: After many decades of dramatic exponential growth, single-processor performance is increasing at a much lower rate, and this situation is not expected to improve in the foreseeable future.
Energy and power constraints play an important—and growing—role in computing performance. Computer systems require energy to operate and, as with any device, the more energy needed, the more expensive the system is to operate and maintain. Moreover, all the energy consumed by the system ends up as heat, which must be removed. Even when new parallel models and solutions are found, most future computing systems’ performance will be limited by power or energy in ways that the computer industry and researchers have not had to deal with thus far. For example, the benefits of replacing a single, highly complex processor with increasing numbers of simpler processors will eventually reach a limit when further simplification costs more in performance than it saves in power. Constraints due to power are thus inevitable for systems ranging from hand-held devices to the largest computing data centers even as the transition is made to parallel systems.
Even with success in sidestepping the limits on single-processor performance, total energy consumption will remain an important concern, and growth in performance will become limited by power consumption within a decade. The total energy consumed by computing systems is already substantial and continues to grow rapidly in the United States and around the world. As is the case in other sectors of the economy, the total energy consumed by computing will come under increasing pressure.
____________________
1ITRS, 2009, ITRS 2009 Edition, available online at http://www.itrs.net/links/2009ITRS/Home2009.htm.
Finding: The growth in the performance of computing systems—even if they are multiple-processor parallel systems—will become limited by power consumption within a decade.
In short, the single processor and the sequential programming model that have dominated computing since its birth in the 1940s, will no longer be sufficient to deliver the continued growth in performance needed to facilitate future IT advances.2 Moreover, it is an open question whether power and energy will be showstoppers or just significant constraints. Although these issues pose major technical challenges, they will also drive considerable innovation in computing by forcing a rethinking of the von Neumann model that has prevailed since the 1940s.
PARALLELISM AS A SOLUTION
Future growth in computing performance will have to come from parallelism. Most software developers today think and program by using a sequential programming model to create software for single general-purpose microprocessors. The microprocessor industry has already begun to deliver parallel hardware in mainstream products with chip multi-processors (CMPs—sometimes referred to as multicore), an approach that places new burdens on software developers to build applications to take advantage of multiple, distinct cores. Although developers have found reasonable ways to use two or even four cores effectively by running independent tasks on each one, they have not, for the most part, parallelized individual tasks in such a way as to make full use of the available computational capacity. Moreover, if industry continues to follow the same trends, they will soon be delivering chips with hundreds of cores. Harnessing these cores will require new techniques for parallel computing, including breakthroughs in software models, languages, and tools. Developers of both hardware and software will need to focus more attention on overall system performance, likely at the expense of time to market and the efficiency of the virtuous cycle described previously.
Of course, the computer science and engineering communities have been working for decades on the hard problems associated with parallelism. For example, high-performance computing for science and engineering applications has depended on particular parallel-programming techniques such as Message Passing Interface (MPI). In other cases,
____________________
2Of course, computing performance encompasses more than intrinsic CPU speed, but CPU performance has historically driven everything else: input/output, memory sizes and speeds, buses and interconnects, networks, and so on. If continued growth in CPU performance is threatened, so are the rest.
domain-specific languages and abstractions such as MapReduce have provided interfaces with behind-the-scenes parallelism and well-chosen abstractions developed by experts, technologies that hide the complexity of parallel programming from application developers. Those efforts have typically involved a small cadre of programmers with highly specialized training in parallel programming working on relatively narrow types of computing problems. None of this work has, however, come close to enabling widespread use of parallel programming for a wide array of computing problems.
Encouragingly, a few research universities, including MIT, the University of Washington, the University of California, Berkeley, and others have launched or revived research programs in parallelism, and the topic has also seen a renewed focus in industry at companies such as NVIDIA. However, these initial investments are not commensurate with the magnitude of the technical challenges or the stakes. Moreover, history shows that technology advances of this sort often require a decade or more. The results of such research are already needed today to sustain historical trends in computing performance, which makes us already a decade behind. Even with concerted investment, there is no guarantee that widely applicable solutions will be found. If they cannot be, we need to know that as soon as possible so that we can seek other avenues for progress.
Finding: There is no known alternative to parallel systems for sustaining growth in computing performance; however, no compelling programming paradigms for general parallel systems have yet emerged.
RECOMMENDATIONS
The committee’s findings outline a set of serious challenges that affect not only the computing industry but also the many sectors of society that now depend on advances in IT and computation, and they suggest national and global economic repercussions. At the same time, the crisis in computing performance has pointed the way to new opportunities for innovation in diverse software and hardware infrastructures that excel in metrics other than single-chip processing performance, such as low power consumption and aggregate delivery of throughput cycles. There are opportunities for major changes in system architectures, and extensive investment in whole-system research is needed to lay the foundation of the computing environment for the next generation.
The committee’s recommendations are broadly aimed at federal research agencies, the computing and information technology industry,
and educators and fall into two categories. The first is research. The best science and engineering minds must be brought to bear on the challenges. The second is practice and education. Better practice in the development of computer hardware and software today will provide a foundation for future performance gains. Education will enable the emerging generation of technical experts to understand different and in some cases not-yet-developed parallel models of thinking about IT, computation, and software.
Recommendations for Research
The committee urges investment in several crosscutting areas of research, including algorithms, broadly usable parallel programming methods, rethinking the canonical computing stack, parallel architectures, and power efficiency.
Recommendation: Invest in research in and development of algorithms that can exploit parallel processing.
Today, relatively little software is explicitly parallel. To obtain the desired performance, it will be necessary for many more—if not most—software designers to grapple with parallelism. For some applications, they may still be able to write sequential programs, leaving it to compilers and other software tools to extract the parallelism in the underlying algorithms. For more complex applications, it may be necessary for programmers to write explicitly parallel programs. Parallel approaches are already used in some applications when there is no viable alternative. The committee believes that careful attention to parallelism will become the rule rather than the notable exception.
Recommendation: Invest in research in and development of programming methods that will enable efficient use of parallel systems not only by parallel-systems experts but also by typical programmers.
Many of today’s programming models, languages, compilers, hyper-visors (to manage virtual machines), and operating systems are targeted primarily at single-processor hardware. In the future, these layers will need to target, optimize programs for, and be optimized themselves for explicitly parallel hardware. The intellectual keystone of the endeavor is rethinking programming models so that programmers can express application parallelism naturally. The idea is to allow parallel software to be developed for diverse systems rather than specific configurations, and to have system software deal with balancing computation and minimizing
communication among multiple computational units. The situation is reminiscent of the late 1970s, when programming models and tools were not up to the task of building substantially more complex software. Better programming models—such as structured programming in the 1970s, object orientation in the 1980s, and managed programming languages in the 1990s—have made it possible to produce much more sophisticated software. Analogous advances in the form of better tools and additional training will be needed to increase programmer productivity for parallel systems.
A key breakthrough would be the ability to express application parallelism in such ways that an application will run faster as more cores are added. The most prevalent parallel-programming languages do not provide this performance portability. A related question is what to do with the enormous body of legacy sequential code, which will be able to realize substantial performance improvements only if it can be parallelized. Experience has shown that parallelizing sequential code or highly sequential algorithms effectively is exceedingly difficult in general. Writing software that expresses the type of parallelism required to exploit chip multiprocessor hardware requires new software engineering processes and tools, including new programming languages that ease the expression of parallelism and a new software stack that can exploit and map the parallelism to hardware that is diverse and evolving. It will also require training programmers to solve their problems with parallel computational thinking.
The models themselves may or may not be explicitly parallel; it is an open question whether or when most programmers should be exposed to explicit parallelism. A single, universal programming model may or may not exist, and so multiple models—including some that are domain-specific—should be explored. Additional research is needed in the development of new libraries and new programming languages with appropriate compilation and runtime support that embody the new programming models. It seems reasonable to expect that some programming models, libraries, and languages will be suited for a broad base of skilled but not superstar programmers. They may even appear on the surface to be sequential or declarative. Others, however, will target efficiency, seeking the highest performance for critical subsystems that are to be extensively reused, and thus be intended for a smaller set of expert programmers.
Another focus for research should be system software for highly parallel systems. Although operating systems of today can handle some modest parallelism, future systems will include many more processors whose allocation, load balancing, and data communication and synchronization interactions will be difficult to handle well. Solving those problems will require a rethinking of how computation and communication resources
are viewed much as demands for increased memory size led to the introduction of virtual memory a half-century ago.
Recommendation: Focus long-term efforts on rethinking of the canonical computing “stack”—applications, programming language, compiler, runtime, virtual machine, operating system, hypervisor, and architecture—in light of parallelism and resource-management challenges.
Computer scientists and engineers typically manage complexity by separating interface from implementation. In conventional computer systems, that is done recursively to form a computing stack: applications, programming language, compiler, runtime, virtual machine, operating system, hypervisor, and architecture. It is unclear whether today’s conventional stack provides the right framework to support parallelism and manage resources. The structure and elements of the stack itself should be a focus of long-term research exploration.
Recommendation: Invest in research on and development of parallel architectures driven by applications, including enhancements of chip multiprocessor systems and conventional data-parallel architectures, cost-effective designs for application-specific architectures, and support for radically different approaches.
In addition to innovation and advancements in parallel programming models and systems, advances in architecture and hardware will play an important role. One path forward is to continue to refine the chip multiprocessors (CMPs) and associated architectural approaches. Are today’s CMP approaches suitable for designing most computers? The current CMP architecture has the advantage of maintaining compatibility with existing software, the heart of the architectural franchise that keeps companies investing heavily. But CMP architectures bring their own challenges. Will large numbers of cores work in most computer deployments, such as on desktops and even in mobile phones? How can cores be harnessed together temporarily, in an automated or semiautomated fashion, to overcome sequential bottlenecks? What mechanisms and policies will best exploit locality (keeping data stored close to other data that might be needed at the same time or for particular computations and saving on the power needed to move data around) so as to avoid communications bottlenecks? How should synchronization and scheduling be handled? How should challenges associated with power and energy be addressed? What do the new architectures mean for such system-level features as reliability and security?
Is using homogeneous processors in CMP architectures the best
approach, or will computer architectures that include multiple but heterogeneous cores—some of which may be more capable than others or even use different instruction-set architectures—be more effective? Special-purpose processors that have long exploited parallelism, notably graphics processing units (GPUs) and digital signal processor (DSP) hardware, have been successfully deployed in important segments of the market. Are there other important niches like those filled by GPUs and DSPs? Alternatively, will computing cores support more graphics and GPUs support more general-purpose programs, so that the difference between the two will blur?
Perhaps some entirely new architectural approach will prove more successful. If systems with CMP architectures cannot be effectively programmed, an alternative will be needed. Work in this general area could eschew conventional cores. It can view the chip as a tabula rasa of billions of transistors, which translates to hundreds of functional units; the effective organization of those units into a programmable architecture is an open question. Exploratory computing systems based on field-programmable gate arrays (FPGAs) are a step in this direction, but continued innovation is needed to develop programming systems that can harness the potential parallelism of FPGAs.
Another place where fundamentally different approaches may be needed is alternatives to CMOS. There are many advantages to sticking with today’s silicon-based CMOS technology, which has proved remarkably scalable over many generations of microprocessors and around which an enormous industrial and experience base has been established. However, it will also be essential to invest in new computation substrates whose underlying power efficiency promises to be fundamentally better than that of silicon-based CMOS circuits. Computing has benefited in the past from order-of-magnitude performance improvements in power consumption in the progression from vacuum tubes to discrete bipolar transistors to integrated circuits first based on bipolar transistors, then on N-type metal oxide semiconductors (NMOS) and now on CMOS. No alternative is near commercial availability yet, although some show potential.
In the best case, investment will yield devices and manufacturing methods—as yet unforeseen—that will dramatically surpass the CMOS IC. In the worst case, no new technology will emerge to help solve the problems. That uncertainty argues for investment in multiple approaches as soon as possible, and computer system designers would be well advised not to expect one of the new devices to appear in time to obviate the development of new, parallel architectures built on the proven CMOS technology. Better performance is needed immediately. Society cannot wait the decade or two that it would take to identify, refine, and apply a new tech-
nology that may or may not even be on the horizon now. Moreover, even if a groundbreaking new technology were discovered, the investment in parallelism would not be wasted, in that advances in parallelism would probably exploit the new technology as well.
Recommendation: Invest in research and development to make computer systems more power-efficient at all levels of the system, including software, application-specific approaches, and alternative devices. Such efforts should address ways in which software and system architectures can improve power efficiency, such as by exploiting locality and the use of domain-specific execution units. R&D should also be aimed at making logic gates more power-efficient. Such efforts should address alternative physical devices beyond incremental improvements in today’s CMOS circuits.
Because computing systems are increasingly limited by energy consumption and power dissipation, it is essential to invest in research and development to make computing systems more power-efficient. Exploiting parallelism alone cannot ensure continued growth in computer performance. There are numerous potential avenues for investigation into better power efficiency, some of which require sustained attention to known engineering issues and others of which require research. These include:
- Redesign the delivery of power to and removal of heat from computing systems for increased efficiency. Design and deploy systems in which the absolute maximum fraction of power is used to do the computing and less is used in routing power to the system and removing heat from the system. New voluntary or mandatory standards (including ones that set ever-more-aggressive targets) might provide useful incentives for the development and use of better techniques.
- Develop alternatives to the general-purpose processor that exploit locality.
- Develop domain-specific or application-specific processors analogous to GPUs and DSPs that provide better performance and power-consumption characteristics than do general-purpose processors for other specific application domains.
- Investigate possible new, lower-power device technology beyond CMOS.
Additional research should focus on system designs and software configurations that reduce power consumption, for example, reducing
power consumption when resources are idle, mapping applications to domain-specific and heterogeneous hardware units, and limiting the amount of communication among disparate hardware units.
Although the shift toward CMPs will allow industry to continue for some time to scale the performance of CMPs based on general-purpose processors, general-purpose CMPs will eventually reach their own limits. CMP designers can trade off single-thread performance of individual processors against lower energy dissipation per instruction, thus allowing more instructions by multiple processors while the same amount of energy is dissipated by the chip. However, that is possible only within a limited range of energy performance. Beyond some limit, lowering energy per instruction by processor simplification can lead to degradation in overall CMP performance because processor performance starts to decrease faster than energy per instruction. When that occurs, new approaches will be needed to create more energy-efficient computers.
It may be that general-purpose CMPs will prove not to be a solution in the long run and that we will need to create more application-optimized processing units. Tuning hardware and software toward a specific type of application allows a much more energy-efficient solution. However, the current design trend is away from building customized solutions, because increasing design complexity has caused the nonrecurring engineering costs for designing the chips to grow rapidly. High costs limit the range of potential market segments to the few that have volume high enough to justify the initial engineering investment. A shift to more application-optimized computing systems, if necessary, demands a new approach to design that would allow application-specific chips to be created at reasonable cost.
Recommendations for Practice and Education
Implementing the research agenda proposed here, although crucial for progress, will take time. Meanwhile, society has an immediate and pressing need to use current and emerging CMP systems effectively. To that end, the committee offers three recommendations related to current development and engineering practices and educational opportunities.
Recommendation: To promote cooperation and innovation by sharing, encourage development of open interface standards for parallel programming rather than proliferating proprietary programming environments.
Private-sector firms are often incentivized to create proprietary interfaces and implementations to establish a competitive advantage. How-
ever, a lack of standardization can impede progress inasmuch as the presence of many incompatible approaches allows none to achieve the benefits of wide adoption and reuse—a major reason that industry participates in standards efforts. The committee encourages the development of programming-interface standards that can facilitate wide adoption of parallel programming even as they foster competition in other matters.
Recommendation: Invest in the development of tools and methods to transform legacy applications to parallel systems.
Whatever long-term success is achieved in the effective use of parallel systems from rethinking algorithms and developing new programming methods will probably come at the expense of the backward-platform and cross-platform compatibility that has been an economic cornerstone of IT for decades. To salvage value from the nation’s current, substantial IT investment, we should seek ways to bring sequential programs into the parallel world. On the one hand, there are probably no “silver bullets” that enable automatic transformation. On the other hand, it is prohibitively expensive to rewrite many applications. The committee urges industry and academe to develop “power tools” for experts that can help them to migrate legacy code to tomorrow’s parallel computers. In addition, emphasis should be placed on tools and strategies to enhance code creation, maintenance, verification, and adaptation of parallel programs.
Recommendation: Incorporate in computer science education an increased emphasis on parallelism, and use a variety of methods and approaches to better prepare students for the types of computing resources that they will encounter in their careers.
Who will develop the parallel software of the future? To sustain IT innovation, we will need a workforce that is adept in writing parallel applications that run well on parallel hardware, in creating parallel software systems, and in designing parallel hardware.
Both undergraduate and graduate students in computer science, as well as in other fields that make intensive use of computing, will need to be educated in parallel programming. The engineering, science, and computer-science curriculum at both the undergraduate and graduate levels should begin to incorporate an emphasis on parallel computational thinking, parallel algorithms, and parallel programming. With respect to the computer-science curriculum, because no general-purpose paradigm has emerged, universities should teach diverse parallel-programming languages, abstractions, and approaches until effective ways of teaching
and programming emerge. The necessary shape of the needed changes will not be clear until some reasonably general parallel-programming methods have been devised and shown to be promising.
Related to this is improving the ability of the programming workforce to cope with the new challenges of parallelism. This will involve retraining today’s programmers and also developing new models and abstractions to make parallel programming more accessible to typically skilled programmers.
CONCLUDING REMARKS
There is no guarantee that we can make future parallel computing ubiquitous and as easy to use as yesterday’s sequential computer, but unless we aggressively pursue efforts as suggested by the recommendations above, it will be game over for future growth in computing performance. This report describes the factors that have led to limitations of growth of single processors based on CMOS technology. The recommendations here are aimed at supporting and focusing research, development, and education in architectures, power, and parallel computing to sustain growth in computer performance and to permit society to enjoy the next level of benefits.
















