
Page 390
What Does Voice-Processing Technology Support Today?
SUMMARY
This paper describes the state of the art in applications of voice-processing technologies. In the first part, technologies concerning the implementation of speech recognition and synthesis algorithms are described. Hardware technologies such as microprocessors and DSPs (digital signal processors) are discussed. Software development environment, which is a key technology in developing applications software, ranging from DSP software to support software also is described. In the second part, the state of the art of algorithms from the standpoint of applications is discussed. Several issues concerning evaluation of speech recognition/synthesis algorithms are covered, as well as issues concerning the robustness of algorithms in adverse conditions.
INTRODUCTION
Recently, voice-processing technology has been greatly improved. There is a large gap between the present voice-processing technology and that of 10 years ago. The speech recognition and synthesis market, however, has lagged far behind technological progress. This paper describes the state of the art in voice-processing technology applications and points out several problems concerning market growth that need to be solved.
Page 391
Technologies related to applications can be divided into two categories. One is system technologies and the other is speech recognition and synthesis algorithms.
Hardware and software technologies are the main topics for system development. Hardware technologies are very important because any speech algorithm is destined for implementation on hardware. Technology in this area is advancing quickly. Microprocessors with capacities of about 100 MIPS are available. Also, digital signal processors (DSPs) that have capabilities of nearly 50 MFLOPS have been developed (Dyer and Harms, 1993) for numerical calculations dedicated to voice processing. Almost all speech recognition/synthesis algorithms can be used with a microprocessor and several DSPs. With the progress of device technology and parallel architecture, hardware technology will continue to improve and will be able to cope with the huge number of calculations demanded by improved algorithms of the future.
Also, software technologies are an important factor, as algorithms and application procedures should be implemented by the use of software technology. In this paper, therefore, software technology will be treated as an application development tool. Along with the growth areas of application of voice-processing technology, various architectures and tools that support applications development have been devised. This architecture and these tools range from compilers for developing DSP firmware to software development tools that enable users to develop dedicated software from application specifications. Also, when speech processing is the application target, it is important to keep in mind the characteristics peculiar to speech. Speech communication basically is of a nature that it should work in a real-time interactive mode. Computer systems that handle speech communications with users should have an ability to cope with these operations. Several issues concerning real-time interactive communication will be described.
For algorithms there are two important issues concerning application. One is the evaluation of algorithms, and the other is the robustness of algorithms under adverse conditions. Evaluation of speech recognition and synthesis algorithms has been one of the main topics in the research area. However, to consider applications, these algorithms should be evaluated in real situations rather than laboratory situations, which is a new research trend. There are two recent improvements in algorithm evaluation. First, algorithm evaluation using large-scale speech databases, which are developed and shared by many research institutions, means that various types of algorithms can be more easily and extensively compared. The second improve-
Page 392
ment is that, in addition to the use of comprehensive databases for evaluation, the number of databases that include speech uttered under adverse conditions is increasing.
Also, the robustness of algorithms is a crucial issue because conditions in almost all real situations are adverse, and algorithms should therefore be robust enough for the application system to handle these conditions well. For speech recognition, robustness means that algorithms are able to cope with various kinds of variations that overlap or are embedded in speech. In addition to robustness in noisy environments, which is much studied, robustness for speech variabilities should be studied. Utterances of a particular individual usually contain a wide range of variability which makes speech recognition difficult in real conditions. Technologies that can cope with speech variabilities will be one of the key technologies of future speech recognition.
Finally, several key issues will be discussed concerning advanced technology and how its application can contribute to broadening the market for speech-processing technology.
SYSTEM TECHNOLOGIES
When speech recognition or synthesis technology is applied to real services, the algorithms are very important factors. The system technology—how to integrate the algorithms into a system and how to develop programs for executing specific tasks—is similarly a very important factor since it affects the success of the system. In this paper we divide the system technology into hardware technology and application—or software—technology and describe the state of the art in each of these fields.
Hardware Technology
Microprocessors
Whether a speech-processing system utilizes dedicated hardware, a personal computer, or a workstation, a microprocessor is necessary to control and implement the application software. Thus, microprocessor technology is an important factor in speech applications. Microprocessor architecture is categorized as CISC (Complex Instruction Set Computer) and RISC (Reduced Instruction Set Computer) (Patterson and Ditzel, 1980). The CISC market is dominated by the Intel x86 series and the Motorola 68000 series. RISC architecture was developed to improve processing performance by simplifying the instruction set and reducing the complexity of the circuitry. Recently,
Page 393
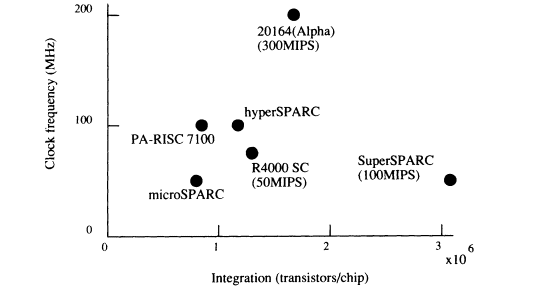
FIGURE 1 Performance of RISC chip.
RISC chips are commonly used in engineering workstations. Several common RISC chips are compared in Figure 1. Performance of nearly 300 MIPS is available. The processing speed of CISC chips has fallen behind that of the RISC in recent years, but developers have risen to the challenge to improve the CISC's processing speed, as the graph of the performance of the x86 series in Figure 2 shows. Better microprocessor performance makes it possible to carry out most speech-processing algorithms using standard hardware, whereas formerly dedicated hardware was necessary. In some applications, the complete speech-processing operation can be carried out using only a standard microprocessor.
Digital Signal Processors
A DSP, or digital signal processor, is an efficient device that carries out algorithms for speech and image processing digitally. To process signals efficiently, the DSP chip uses the following mechanisms: high-speed floating point processing unit, pipeline multiplier and accumulator, and parallel architecture of arithmetic-processing units and address calculation units.
Specifications of typical current DSPs are shown in Table 1. DSPs of nearly 50 MFLOPS are commercially available. Recent complicated
Page 394
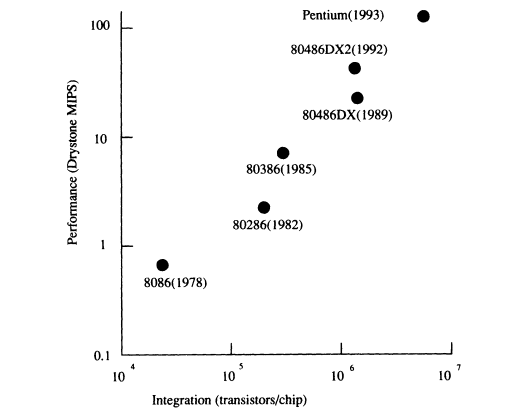
FIGURE 2 Performance improvement of x86 microprocessor.
speech-processing algorithms need broad dynamic range and high precision. The high-speed floating point arithmetic unit has made it possible to perform such processing in minimal instruction cycles without loss of calculation precision. Increased on-chip memory has made it possible to load the whole required amount of data and access internally for the speech analysis or pattern-matching calculations, which greatly contributes to reducing instruction cycles. Usually more cycles are needed to access external memory than are needed for accessing on-chip memory. This is a bottleneck to attaining higher throughput. The amount of memory needed for a dictionary for speech recognition or speech synthesis is too large to implement on-chip though; several hundred kilobytes or several megabytes of external memory are required to implement such a system.
Most traditional methods of speech analysis, as well as speech
Page 395
TABLE 1 Specifications of Current Floating-Point DSPs
| Developer | Name | Cycle Time | Data Width | Multiplier | On-chip RAM | Address | Technology | Electric Power Consumption |
| Texas Instruments | TMS320C40 | 40 ns | 24E8 | 24E8 x 24E8 | 2K w | 4G w | 0.8-m m CMOS | 1.5 W |
| Motorola | DSP96002 | 50 ns | 24E8 | 32E11 x 32E11 | (1K+512) w | 12G w | 1.2-m m CMOS | 1.5 W |
| AT&T | DSP3210 | 60 ns | 24E8 | 24E8 x 24E8 | 2K w | 1G w | 0.9-m m CMOS | 1.0 W |
| NEC | mPD77240 | 90 ns | 24E8 | 24E8 x 24E8 | 1K w | 64M w | 0.8-m m CMOS | 1.6 W |
| Fujitsu | MB86232 | 75 ns | 24E8 | 24E8 x 24E8 | 512 w | 1M w | 1.2-m m CMOS | 1.0 W |
Page 396

FIGURE 3 Transputer architecture (Inmos, 1989).
recognition algorithms based on the HMM (hidden Markov model), can be carried out in real time by a single DSP chip and some amount of external memory. On the other hand, recent speech analysis, recognition, and synthesis algorithms have become so complex and time consuming that a single DSP cannot always complete the processing in real time. Consequently, to calculate a complex algorithm in real time, several DSP chips work together using parallel processing architecture. The architecture of the transputer, a typical parallel signal-processing system, is shown in Figure 3. It has four serial data communication links rather than a parallel external data bus, so that the data can be sent effectively and the computation load can be distributed to (four) other transputers. The parallel programming language "Occam" has been developed for this chip.
Equipment and Systems
Speech-processing equipment or a speech-processing system can be developed using either microprocessors or DSPs. They can use one of the following architectures: (a) dedicated, self-contained hardware that can be controlled by a host system, (b) a board that can be plugged into a personal computer or a workstation, and (c) a dedicated system that includes complete software and other necessities for an application.
In the early days of speech recognition and synthesis, devices of type (a) were developed because the performance of microprocessors and DSPs was not adequate for real-time speech processing (and were
Page 397
not so readily available). Instead, the circuits were constructed using small-scale integrated circuits and wired logic circuits. Recently, however, DSPs are replacing this type of system. A type (a) speech-processing application system can be connected to a host computer using a standard communication interface such as the RS-232C, the GPIB, or the SCSI. The host computer executes the application program and controls the speech processor as necessary. In this case the data bandwidth is limited and is applicable only to relatively simple processing operations.
As for case (b), recent improvements of digital device technology such as those shown in Figures 1 and 2, and Table 1 have made it possible to install a speech-processing board in the chassis of the increasingly popular personal computers and workstations. The advantages of this board-type implementation are that speech processing can be shared between the board and a host computer or workstation, thus reducing the cost of speech processing from that using self-contained equipment; speech application software developed for a personal computer or workstation equipped with the board operates within the MS-DOS or UNIX environment, making it easier and simpler to develop application programs; and connecting the board directly to the personal computer or workstation bus allows the data bandwidth to be greatly widened, which permits quick response—a crucial point for a service that entails frequent interaction with a user.
In some newer systems only the basic analog-to-digital and digital-to-analog conversions are performed on the board, while the rest of the processing functions are carried out by the host system.
Examples of recent speech recognition and speech synthesis systems are shown in Figure 4 and Figure 5, respectively. Figure 4 shows a transputer-based speech recognizer, which comprises one board that plugs into the VME bus interface slot of a workstation. The function of the board is speech analysis by DSPs, HMM-based speaker-independent word spotting, and recognition candidate selection using nine transputer chips (Imamura and Suzuki, 1990). The complete vocabulary dictionary is shared among the transputers, and the recognition process is carried out in parallel. The final recognition decision, control of the board, and the other processing required by the application are done in the host workstation. The application development and debugging are also done on the same host machine. The Japanese text-to-speech synthesizer shown in Figure 5 is also a plug-in type, for attachment to a personal computer. Speech synthesis units are created by the context-dependent phoneme unit using the clus-
Page 398

FIGURE 4 Example of a speech recognition system (Imamura and Suzuki, 1990).

FIGURE 5 Example of a text-to-speech synthesizer (Sato et al., 1992).
tering technique. The board consists mainly of the memory for the synthesis unit, a DSP for LSP synthesis, and a digital-to-analog converter (Sato et al., 1992).
Method (c) is adopted when an application is very large. The speech system and its specific application system are developed as a package, and the completed system is delivered to the user. This method is common for telecommunications uses, where the number of users is expected to be large. In Japan a voice response and speech recognition system has been offered for use in public banking services since 1981. The system is called ANSER (Automatic answer Network System for Electrical Request). At first the system had only
Page 399

FIGURE 6 Configuration of the ANSER system (Nakatsu and Ishii, 1987).
the voice response function for Touch-Tone telephones. Later, a speech recognition function was added for pulse, or rotary-dial, telephone users. After that, facsimile and personal computer interface capabilities were added to the system, and ANSER is now an extensive system (Nakatsu, 1990) that processes more than 30 million transactions per month, approximately 20 percent of which are calls from rotary-dial telephones. The configuration of the ANSER system is shown in Figure 6.
Application Technology Trend
Development Environment for DSP
As mentioned above, a DSP chip is indispensable to a speech-processing system. Therefore, the development environment for a DSP system is a critical factor that affects the turnaround time of system development and eventually the system cost. In early days only an assembler language was used for DSPs, so software development required a lot of skill. Since the mid-1980s, the introduction of high-level language compilers (the C cross compiler is an example) made DSP software development easier. Also, some commonly used algorithms are offered as subroutine libraries to reduce the programmer's burden. Even though the cross compilers have become more popular these days, software programming based on an assembler language may still be necessary in cases where real-time processing is critical.
Page 400

FIGURE 7 DSP development environment (Texas Instruments, 1992).
An example of a DSP development environment is shown in Figure 7. A real-time operating system for DSP is available. Moreover, a parallel processing development environment is offered for parallel DSP systems. However, the critical aspect of parallel DSP programming depends substantially on the programmer's skill. A more efficient and usable DSP development environment is needed to make DSP programming easier and more reliable.
Application Development Environment
Environments in application development take various forms, as exemplified by the varieties of DSP below:
Page 401
(a) Application software is developed in a particular language dedicated to a speech system.
(b) Application software is developed using a high-level language such as C.
(c) Application software is developed using an ''application builder," according to either application flow or application specifications.
Application software used to be written for each system using assembler language. Such cases are rare recently because of the inadequacy of a low-level programming language for developing large and complex systems. However, assembler language is still used in special applications, such as games or telephones, that require compact and high-speed software modules.
Recently, applications have usually been described by a high-level language (mainly C). Speech recognition and synthesis boards are commonly plugged into personal computers, and interface subroutines with these boards can be called from an application program written in C. An application support system for Dragon Writer (Dragon Systems, Inc.) is shown in Figure 8.
As an application system becomes larger, the software maintenance becomes more complicated; the user interface becomes more important; and, eventually, control of the speech system becomes more complicated, the specifications become more rigid, and improvement becomes more difficult. Therefore, the application development should be done in a higher-level language. Moreover, it is desirable for an "Application Builder" to adhere to the following principles: automatic program generation from a flowchart, automatic generation of an application's grammar, and graphical user interface for software development. Such an environment is called "Application Builder." Development of the Application Builder itself is an important and difficult current theme of automatic software generation research. So far, few systems have been implemented using the Application Builder, though some trials have been done in the field of speech-processing systems (Renner, 1992).
Speech Input/Output Operating Systems
Availability of a speech input/output function on a personal computer or workstation is a requisite for popularizing the speech input/output function. It is adequate to implement the speech input/output function at the operating system level. There are two ways: (a) developing a dedicated operating system with speech input/output function and (b) adding a speech input/output function as a preprocessor to an existing operating system.
Page 402

FIGURE 8 Application support of speech recognition system (Dragon Writer).
Method (a) best utilizes speech recognition and synthesis capabilities. With this method a personal computer or workstation system with a speech input/output function can be optimally designed. However, no operating system that is specific to speech input/output has yet been developed. In the field of character recognition, on the other hand, pen input specific operating systems—called "Pen OS"—have begun to appear. These operating systems are not limited to handwritten character recognition; they are also capable of pen-pointing and figure command recognition. In other words, character recognition is not the primary function but just one of the functions. This grew out of the realization that recognition of handwritten characters is not yet satisfactory and that handwriting is not necessarily faster than keyboard input. Optimum performance was achieved by combining several data input functions such as keyboard input, mouse
Page 403
clicking, or pen input. This principle should be applied to the development of speech operating systems.
In method (b) there is no need to develop a new operating system. For example, a Japanese kana-kanji preprocessor, which converts keyboard inputs into 2-byte Japanese character codes, is widely used for Japanese character input. The same concept can be applied to speech input/output. An advantage of this method is that speech functions can easily be added to popular operating systems such as MS-DOS. An example of the speech preprocessor is shown in Figure 9. Input can alternate between mouse and speech, and menu selection can be carried out by either mouse clicking or speech input. Input can be accomplished more efficiently by speech, especially when using a drawing application.
Real-Time Application Support
Real-time dialogue-processing function is a future need in speech applications. The speech system must carry out an appropriate control of the speech recognizer and the speech synthesizer to realize the
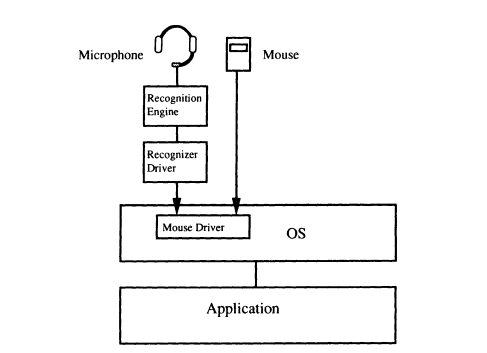
FIGURE 9 Configuration of a speech preprocessor.
Page 404
real-time dialogue between humans and computers. Also, an easy method to describe this control procedure needs to be developed and opened to users so that they can develop dialogue control software easily. These points would be the main problems when developing an application system in the near future. The state of the art and the required technologies for the real-time application system are described below.
Barge in "Barge in" means an overlap or collision of utterances, which frequently occurs in human speech conversation. This phenomenon is actually an important factor in making the communication smooth. The time delay on an international telecommunication line makes the conversation awkward because it interferes with this barge in. It is pointed out that the same phenomenon readily occurs in dialogues between humans and computers. The following techniques allow for barge in in a speech system:
• The system starts recognition as soon as it starts sending a voice message. An echo canceller can be applied to subtract the synthesizer's voice and to maintain recognition performance.
• The system may start sending a voice message as soon as the key word is extracted even if the speaker's voice has not been completed yet.
Although the former function has been implemented in some systems, no application has yet incorporated the latter function. This function can be carried out in a small-vocabulary system, so the human-machine interface should be researched in this case.
Key Word Extraction Even in applications based on word recognition, humans tend to utter extra words or vocal sounds and sometimes even entire sentences. When the recognition vocabulary is limited, a simple key word extraction or spotting technique is used. (If the vocabulary size is huge or unlimited, the speech must be recognized in its entirety.) Several word-spotting algorithms have been proposed (Kimura et al., 1987; Wilpon et al., 1990) and proven efficient for extracting only key words.
Distributed Control of DSP Real-time processing is needed for speech recognition and speech synthesis. Currently, DSP hardware and software design is entrusted to skillful systems engineers, and this sometimes creates a bottleneck in system development. The following development environment is desirable:
Page 405
• Speech-processing algorithms are transformed into programs, ignoring real-time realization problems.
• The DSP system has a flexible parallel architecture and a real-time operating system. When the program to be processed in real time is loaded, the operating system automatically divides the job into subtasks that can be processed in real time by single DSPs. These subtasks are distributed to several DSPs, and then the operation is executed in real time.
ALGORITHMS
Recognition of large spoken vocabularies and understanding of spontaneous spoken language are studied eagerly by many speech recognition researchers. Recent speech synthesis research focuses on improvement of naturalness and treatment of prosodic information. The state of the art of speech recognition/synthesis technologies is described further elsewhere in this volume in papers by Carlson and Makhoul and Schwartz. In most of these studies, rather clean and closed speech data are usually used for both training and evaluation. However, field data used in developing applications are neither clean nor closed. This leads to various problems, which are described below:
• Databases. A speech database that includes field data rather than laboratory data is necessary both for training and evaluating speech recognition systems.
• Algorithm assessment. Evaluation criteria other than those that have been used to undertake algorithm evaluation in the laboratory should be used to assess the feasibility of speech recognition/synthesis algorithms and systems to be used in real applications.
• Robustness of algorithms. In a real environment a broad spectrum of factors affect speech. Speech recognition/synthesis algorithms should be robust under these varied conditions. These topics will be discussed in the following sections.
Databases
Databases for Research
Currently, in speech recognition research, statistical methods such as the HMM are widely used. One of the main characteristics of a statistical method is that its performance generally depends on the quantity and quality of the speech database used for its training. The
Page 406
amount of speech data collected is an especially important factor for determining its recognition performance. Because construction of a large database is too big a job for a single researcher or even a single research institute, collaboration among speech researchers to construct databases has been very active. In the United States, joint speech database construction is undertaken in Spoken Language programs supported by DARPA (Defense Advanced Research Projects Agency) (MADCOW, 1992; Pallet et al., 1991). In Europe, under several projects such as ESPRIT (European Strategic Program for Research and Development in Information Technology), collaborative work has been done for constructing large speech databases (Carre et al., 1984; Gauvain et al., 1990). Also, in Japan large speech databases are under construction by many researchers at various institutes (Itahashi, 1990).
For speech synthesis, on the other hand, concatenation of context-dependent speech units has recently proven efficient for producing high-quality synthesized speech. In this technology selection of the optimum unit for concatenation from a large set of speech units is essential. This means that a large speech database is necessary in speech synthesis research also, but a trend toward collaborative database construction is not yet apparent in this area. The main reason is that the amount of speech data needed for speech synthesis is far less than that for speech recognition because the aim of speech synthesis research is not to produce various kinds of synthesized speech.
Databases for Application
The necessity of a speech database is not yet being discussed from the standpoint of application. Two reasons are as follows:
• The application area both for speech recognition and speech synthesis is still very limited. Accordingly, there is not a strong need for constructing speech databases.
• Applications are tied closely to business. This means that vendors or value-added resellers who are constructing speech databases do not want to share the information in their databases.
For telephone applications, on the other hand, disclosure of information about databases or the databases themselves is becoming common. In this area, applications are still in the early stages and competition among vendors is not strong yet. Another reason is that in telephone applications the amount of speech database necessary for training a speaker-independent speech recognition algorithm is
Page 407
TABLE 2 Examples of Telephone Speech Database
| Institute | Vocabulary | No. Speakers | Region |
| NTT | Sixteen words | 3000 (male,: 1500; female: 1500) | Three regions Tokyo, Osaka, Kyushu |
| Texas Instruments | Connected-digit sentence | 3500 | Eleven dialects |
| AT&T | Three words | Training: 4000 Test: 1600 | Eight regions in Spain |
| Six words | Training: 22,000 Test: 4500 | Eighteen regions in the United Kingdom | |
| Oregon Graduate Institute | Name, city name | 4000 | |
| NYNEX (planning) | 6500-8000 words | 1000 |
SOURCE: Picone, 1990; Walker and Millar, 1989.
huge, which has led to a consensus between researchers that collaboration on database construction is necessary.
Some examples of speech database collection through telephone lines are summarized in Table 2. In the United States, Texas Instruments is trying to construct a large telephone speech database that is designed to provide a statistically significant model of the demographics of the U.S. population (Picone, 1990). Also, AT&T is actively trying to adapt word-spotting speech recognition technology to various types of telephone services. For that purpose, the company has been collecting a large amount of speech data through telephone lines (Jacobs et al., 1992). Several other institutes are also constructing various kinds of telephone speech databases (Cole et al., 1992; Pittrelli et al., 1992). In Europe, various trial applications of speech recognition technology to telephone service are under way (Rosenbeck and Baungaard, 1992; Walker and Millar, 1989). In Japan, as discussed earlier, the ANSER speech recognition and response system has been widely used for banking services since the beginning of the 1980s. For training and evaluating the speech recognition algorithm used in the ANSER system, a large speech database consisting of utterances of more than
Page 408
3000 males and females ranging in age from 20 to 70 was constructed (Nomura and Nakatsu, 1986).
As telephone service has been considered a key area for the application of speech recognition technology, various trials have been undertaken and various issues are being discussed. Several comments on these issues, based on the experiences of developing the ANSER system and participating in the operation of the banking service, are given below.
Simulated Telephone Lines
Because of the difficulties underlying the collection of a large speech corpus through telephone lines, there has been a discussion that a synthetic telephone database, constructed by passing an existing speech database through a simulated telephone line, could be used as an alternative (Rosenbeck, 1992), and a prototype of such a simulated telephone line has been proposed (Yang, 1992).
Table 3 summarizes the use of speech data to improve service performance in the ANSER system. In the first stage of the ANSER services, a speech database from simulated telephone lines was used. This database was replaced by real telephone line data because recognition based on the simulated telephone data was not reliable enough. From these experiences it was concluded that simulated telephone data are not appropriate for real telephone applications. The main reasons are as follows:
TABLE 3 Milestones of Speech Recognition in ANSER
| Training Data | ||||
| Line | No. Speakers | Region | ||
| Spring 1981 | Service started in Tokyo area | Pseudo-telephone line | 500 | Tokyo |
| Autumn 1981 | Service recognizer retrained | Telephone line | 500 | Tokyo |
| Spring 1982 | Service area widened to Osaka and Kyushu areas | Telephone line | 500 | Tokyo |
| Autumn 1982 | Speech recognizer retrained | Telephone line | 1500 | Tokyo, Osaka, Kyushu |
Page 409
• Characteristics of real telephone lines vary greatly depending on the pass selected. It is difficult, therefore, to simulate these variations using a simulated line.
• In addition to line characteristics, various noises are added to speech. Again, it is difficult to duplicate these noises on a simulated line.
To overcome the difficulty of collecting a large speech corpus through real telephone lines, NYNEX has constructed a large database, called NTIMIT (Jankowski et al., 1990), by passing recorded speech through a telephone network.
Dialects It is considered important for speech data to include the various dialects that will appear in real applications. This dialect factor was taken into consideration in the construction of several databases (Jacobs et al., 1992; Picone, 1990). The ANSER service used speech samples collected in the Tokyo area when the real telephone line database was introduced. As the area to which banking service is offered expanded to include the Osaka and Kyushu areas, it was pointed out that the performance was not as good in these areas as it was in the Tokyo area. In response to the complaints, telephone data were collected in both the Osaka and Kyushu areas. The speech recognizer was retrained using all of the utterances collected in all three areas, and recognition performance stabilized.
Assessment of Algorithms
Assessment of Speech Recognition Algorithms
In the early days of speech recognition, when word recognition was the research target, the word recognition rate was the criterion for assessment of recognition algorithms. Along with the shift of research interest from word recognition to speech understanding, various kinds of assessment criteria, including linguistic processing assessment, have been introduced. These assessment criteria are listed in Table 4. Regarding application, the following issues are to be considered.
Assessment Criteria for Applications In addition to the various criteria used for the assessment of recognition methods at the laboratory level, other criteria should be introduced in real applications. Some of these assessment criteria are listed in Table 5. Recently, various kinds of field trials for telephone speech recognition have been undertaken in
Page 410
TABLE 4 Assessment Criteria for Speech Recognition
| Phoneme Level | Word Level | Sentence Level |
| Correct segmentation rate | Isolated word: Word recognition rate | Word recognition rate (after linguistic processing) |
| Phoneme recognition rate | Connected word: Word recognition rate (including insertion, deletion, and substitution) | Sentence recognition rate |
| Word sequence recognition rate | Correct answer rate | |
| Key-word extraction rate |
which several kinds of assessment criteria are used (Chang, 1992; Nakatsu and Ishii, 1987; Rosenbeck and Baungaard, 1992; Sprin et al., 1992). Among these criteria, so far, the task completion rate (TCR) is considered most appropriate (Chang, 1992; Neilsen and Kristernsen, 1992). This matches the experience with the ANSER service. After several assessment criteria had been measured, TCR was determined to be the best criterion. TCR was under 90 percent, and there were many complaints from customers. As TCR exceeded 90 percent, the number of complaints gradually diminished, and complaints are rarely received now that the TCR exceeds 95 percent.
Assessment Using the "Wizard of Oz" Technique When application systems using speech recognition technology are to be improved in order to raise user satisfaction, it is crucial to pinpoint the bottlenecks. The bottlenecks could be the recognition rate, rejection reliability, dialogue design, or other factors. It is nearly impossible to create a sys-
TABLE 5 Assessment Criteria of Speech Recognition from User's Side
| Objective Criteria | Subjective Criteria |
| Task completion rate | Satisfaction rating |
| Task completion time | Fatigue rating |
| Number of interactions | Preference |
| Number of error correction sequences |
Page 411
tem to evaluate the bottlenecks totally automatically because there are too many parameters and because several parameters, such as recognition rate, are difficult to change. The ''Wizard of Oz" (WOZ) technique might be an ideal alternative to this automatic assessment system. When the goal is a real application, reliable preassessment based on the WOZ technique is recommended. One important factor to consider is processing time. When using the WOZ technique, it is difficult to simulate real-time processing because humans play the role of speech recognizer in the assessment stage. Therefore, one must factor in the effect of processing time when evaluating simulation results.
Besides its use for assessment of user satisfaction, other applications of this technique include the comparison of Touch-Tone input with voice input (Fay, 1992) or of comparing human interface service based on word recognition with that based on continuous speech recognition (Honma and Nakatsu, 1987).
Assessment of Speech Synthesis Technology
Speech synthesis technology has made use of assessment criteria such as phoneme intelligibility or word intelligibility (Steeneken, 1992). What is different from speech recognition technology is that almost all the assessment criteria that have been used are subjective criteria. Table 6 summarizes these subjective and objective assessment criteria. As environments have little effect on synthesized speech, the same assessment criteria that have been used during research can be applied to real use. However, as applications of speech synthesis technology rapidly diversify, new criteria for assessment by users arise:
a. In some information services, such as news announcements, customers have to listen to synthesized speech for lengthy periods,
TABLE 6 Assessment Criteria of Speech Synthesis
| Intelligibility | Naturalness |
| Phoneme intelligibility | Preference score |
| Syllable intelligibility | MOS |
| Word intelligibility | |
| Sentence intelligibility |
Page 412
so it is important to consider customers' reactions to listening to synthesized speech for long periods.
b. More important than the intelligibility of each word or sentence is whether the information or meaning is conveyed to the user.
c. In interactive services such as reservations, it is important for customers to realize from the beginning that they are interacting with computers, so for some applications synthesized speech should not only be intelligible but should also retain a synthesized quality.
Several studies have been done putting emphasis on the above points. In one study, the rate of conveyance of meaning was evaluated by asking simple questions to subjects after they had listened to several sentences (Hakoda et al., 1986). Another study assessed the effects on listener fatigue of changing various parameters such as speed, pitch, sex, and loudness during long periods of listening (Kumagami et al., 1989).
Robust Algorithms
Classification of Factors in Robustness
Robustness is a very important factor in speech-processing technology, especially in speech recognition technology (Furui, 1992). Speech recognition algorithms usually include training and evaluation procedures in which speech samples from a database are used. Of course, different speech samples are used for training procedures than for evaluation procedures, but this process still contains serious flaws from the application standpoint. First, the same recording conditions are used throughout any one database. Second, the same instruction is used for all speakers in any one database.
This means that speech samples contained in a particular database have basically similar characteristics. In real situations, however, speakers' environments vary. Moreover, speech characteristics also tend to vary depending on the environments. These phenomena easily interfere with recognition. This is a fundamental problem in speech recognition that is hard to solve by algorithms alone.
Robustness in speech recognition depends on development of robust algorithms to deal with overlapping variations in speech. Factors that determine speech variations are summarized in Table 7.
Environmental Variation Environments in which speakers input speech samples tend to vary. More specifically, variation of transmission characteristics between the speech source and the microphone such
Page 413
TABLE 7 Factors Determining Speech Variation
| Environment | Noise | Speaker |
| Reflection Reverberation Distance to microphone | Stationary or quasi-stationary noise | Interspeaker variation Dialect Vocal tract |
| Microphone characteristics | White noise br> Car noise br>Air-conditioner noise | characteristics Speaking manner Coarticulation |
| Nonstationary noise: Other voices, Telephone bells, Printer noise | Intraspeaker variation: Emotion, Stress, Lombard effect |
as reflection, reverberation, distance, telephone line, and characteristics of the microphone itself are the causes of these variations.
Noise In addition to various kinds of stationary noise, such as white noise, that overlap speech, real situations add various extraneous sounds such as other voices. All sound other than the speech to be recognized should be considered noise.
Speech Variation The human voice itself tends to vary substantially depending on the situation. In addition to interspeaker variation, which is a key topic in speech recognition, speech of the individual person varies greatly depending on the situation. This intraspeaker variation is a cardinal factor in speech recognition.
These variations, and recognition algorithms to compensate for them, are described in more detail below.
Environmental Variation
Environmental variations that affect recognition performance are distance between the speech source and the microphone, variations of transmission characteristics caused by reflection and reverberation, and microphone characteristics. In research where only existing databases are used, these issues have not been dealt with. In real applications, speakers may speak to computers while walking about in a room and are not likely to use head-mounted microphones. The demands on speech recognition created by these needs have recently attracted researchers' attention. Measurement of characteristics, rec-
Page 414
ognition experiments, and algorithm improvement reveal the following facts.
Distance Between Speaker and Microphone As the distance between the speaker and the microphone increases, recognition performance tends to decrease because of degradation of low-frequency characteristics. Normalization of transmission characteristics by using a directional microphone or an array microphone has been found to be effective in compensating for these phenomena (Tobita et al., 1989).
Reflection and Reverberation It has been known that the interference between direct sound and sound reflected by a desk or a wall causes sharp dips in the frequency. Also, in a closed room the combination of various kinds of reflection causes reverberation. As application of speech recognition to conditions in a room or a car has become a key issue, these phenomena are attracting the attention of speech recognition researchers, and several studies have been done. Use of a directional microphone, adoption of an appropriate distance measure, or introduction of adaptive filtering are reported to be effective methods for preventing performance degradation (Tobita et al., 1990a; Yamada et al., 1991).
Microphone Characteristics Each microphone performs optimally under certain conditions. For example, the frequency of a close-range microphone flattens when the distance to the mouth is within several centimeters. Accordingly, using different microphones in the training mode and the recognition mode causes performance degradation (Acero and Stern, 1990; Tobita et al., 1990a). Several methods have been proposed to cope with this problem (Acero and Stern, 1991; Tobita et al., 1990b).
Noise
As described earlier, all sounds other than the speech to be recognized should be considered noise. This means that there are many varieties of noise, from stationary noise, such as white noise, to environmental sounds such as telephone bells, door noise, or speech of other people. The method of compensating varies according to the phenomenon.
For high-level noise such as car noise or cockpit noise, noise reduction at the input point is effective. A head-mounted noise-canceling microphone or a microphone with sharp directional characteristics is reported effective (Starks and Morgan, 1992; Viswanathan et
Page 415
al., 1986). Also, several methods of using microphone arrays have been reported (Kaneda and Ohga, 1986; Silverman et al., 1992).
If an estimation of noise characteristics is possible by some means such as use of a second microphone set apart from the speaker, it is possible to reduce noise by calculating a transverse filter for the noise characteristics and applying this filter to the input signal (Nakadai and Sugamura, 1990; Powell et al., 1987).
An office is a good target for diversifying speech recognition applications. From the standpoint of robustness, however, an office does not provide satisfactory conditions for speech recognition. Offices are usually not noisy. Various kinds of sounds such as telephone bells or other voices overlap this rather calm environment, so these sounds tend to mask the speech to be recognized. Also, a desk-mounted microphone is preferable to a close-range microphone from the human interface standpoint. Use of a comb filter has been proposed for separating object speech from other speech (Nagabuchi, 1988).
Speaker Variation
There are two types of speaker variation. One is an interspeaker variation caused by the differences among speakers between speech organs and differences in speaking manners. The other is intraspeaker variation. So far, various kinds of research related to interspeaker variations have been reported because this phenomena must be dealt with in order to achieve speaker-independent speech recognition. Intraspeaker variations, however, have been regarded as small noise overlapping speech and have been largely ignored. When it comes to applications, however, intraspeaker variation is an essential speech recognition factor.
Human utterances vary with the situation. Among these variations, mannerisms and the effects of tension, poor physical condition, or fatigue are difficult to control. Therefore, speech recognition systems must compensate for these variations.
There is a great practical need for recognition of speech under special conditions. Emergency systems, for example, that could distinguish words such as "Fire!" from all other voices or sounds would be very useful.
Several studies of intraspeaker variation have been undertaken. One typical intraspeaker variation is known as the "Lombard effect," which is speech variation caused by speaking under very noisy conditions (Roe, 1987). Also, in several studies utterances representing various kinds of speaking mannerisms were collected, and the HMM
Page 416
was implemented to recognize these utterances (Lippmann et al., 1987; Miki et al., 1990).
SPEECH TECHNOLOGY AND THE MARKET
As described in this paper, practical speech technologies have been developing rapidly. Applications of speech recognition and speech synthesis in the marketplace, however, have failed to keep pace with the potential. In the United States, for example, although the total voice-processing market at present is over $1 billion, most of this is in voice-messaging services. The current size of the speech recognition market is only around $100 million, although most market research in the 1980s forecasted that the market would soon reach $1 billion (Nakatsu, 1989). And the situation is similar for speech synthesis. In this section the strategy for market expansion is described, with emphasis on speech recognition technology.
Illusions About Speech Recognition Technology
In papers and surveys on speech recognition, statements such as the following have been used frequently:
"Speech is the most convenient method of communication for humans, and it is desirable to achieve oral communication between humans and computers."
"Speech recognition is now mature enough to be applied to real services."
These statements are basically correct. However, when combined, they are likely to give people the following impression:
"Speech recognition technology is mature enough to enable natural communication between computers and humans."
Of course, this is an illusion, and speech researchers or vendors should be careful not to give users this fallacious impression. The truth could be stated more precisely as follows:
a. The capacity to communicate orally is a fundamental human capability, which is achieved through a long learning process that begins at birth. Therefore, although the technology for recognizing natural speech is advancing rapidly, there still exists a huge gap between human speech and the speech a computer is able to handle.
b. Nevertheless, speech recognition technology has reached a level where, if applications are chosen appropriately, they can pro-
Page 417
vide a means for communication between computers and humans that—although maybe not natural—is at least acceptable.
Strategy for Expanding the Market
Market studies carried out by the authors and others have identified the following keys to expansion of the speech recognition market, listed in descending order of importance (Nakatsu, 1989; Pleasant, 1989):
• Applications and marketing. New speech recognition applications must be discovered.
• Performance. Speech recognition algorithms must perform reliably even in real situations.
• Capabilities. Advanced recognition capabilities such as continuous speech recognition must be achieved.
Based on the above results and also on our experiences with developing and operating the ANSER system and service, the following is an outline of a strategy for widening the speech recognition market.
Service Trials
Because practical application of speech recognition to real services is currently limited to word recognition, which is so different from how humans communicate orally, it is difficult for both users and vendors to discover appropriate new applications. Still it is necessary for vendors to try to offer various kinds of new services to users. Although many of them might fail, people would come to recognize the capabilities of speech recognition technology and would subsequently find application areas suited to speech recognition.
Telephone services might be the best, because they will offer speech recognition functions to many people and help them recognize the state of the art of speech recognition. Also, as pointed out earlier, the interesting concept of a "Speech OS" is worth trying.
Robustness Research
It is important for speech recognition algorithms to be made more robust for real situations. Even word recognition with a small vocabulary, if it worked in the field as reliably as in the laboratory, would have great potential for application. It is delightful that re-
Page 418
cently the importance of robustness has attracted the attention of speech researchers and that various kinds of research are being undertaken, as described in the previous section.
One difficulty is that the research being done puts too much emphasis on stationary or quasi-stationary noise. There are tremendous variations of noise in real situations, and these real noises should be studied. Also, as stated before, intraspeaker speech variation is an important factor to which more attention should be paid.
Long Term Research
At the same time, it is important to continue research of speech recognition to realize more natural human-machine communication based on natural conversation. This will be long-term research. However, as oral communication capability arises from the core of human intelligence, basic research should be continued systematically and steadily.
CONCLUSION
This paper has briefly described the technologies related to speech recognition and speech synthesis from the standpoint of practical application.
First, systems technologies were described with reference to hardware technology and software technology. For hardware technology, along with the rapid progress of technology, a large amount of speech processing can be done by personal computer or workstation with or without additional hardware dedicated to speech processing. For software, on the other hand, the environment for software development has improved in recent years. Still further endeavor is necessary for vendors to pass these improvements on to end users so they can develop application software easily.
Then, several issues relating to the practical application of speech recognition and synthesis technologies were discussed. Speech databases for application and evaluation of these technologies were described. So far, because the range of applications of these technologies is limited, criteria for assessing the applications are not yet clear. Robustness of algorithms applied to field situations also was described. Various studies are being done concerning robustness.
Finally, reasons for the slow development of the speech recognition/synthesis market were discussed, and future directions for researchers and vendors to explore were proposed.
Page 419
REFERENCES
Acero, A., and R. M. Stern, "Environmental Robustness in Automatic Speech Recognition," Proceedings of the IEEE ICASSP-90, pp. 849-852 (1990).
Acero, A., and R. M. Stern, "Robust Speech Recognition by Normalization of the Acoustic Space," Proceedings of the IEEE ICASSP-91, pp. 893-896 (1991).
Carre, R., et al., "The French Language Database: Defining and Recording a Large Database," Proceedings of the IEEE ICASSP-84, 42.10 (1984).
Chang, H. M., "Field Performance Assessment for Voice Activated Dialing (VAD) Service," Proceedings of the 1st IEEE Workshop on Interactive Voice Technology for Telecommunications Applications, IEEE (1992).
Cole, R., et al., "A Telephone Speech Database of Spelled and Spoken Names," Proceedings of the International Conference on Spoken Language Processing, pp. 891-893 (1992).
Dyer, S., and B. Harms, "Digital Signal Processing," Advances in Computers, Vol. 37, pp. 104-115 (1993).
Fay, D. F., "Touch-Tone or Automatic Speech Recognition: Which Do People Prefer?," Proceedings of AVIOS '92, pp. 207-213, American Voice I/O Society (1992).
Furui, S., "Toward Robust Speech Recognition Under Adverse Conditions," Proceedings of the ESCA Workshop on Speech Processing in Adverse Conditions, pp. 3142 (1992).
Gauvain, J. L., et al., "Design Considerations and Text Selection for BREF, a Large French Read-Speech Corpus," Proceedings of the International Conference on Spoken Language Processing, pp. 1097-1100 (1990).
Hakoda, K., et al., "Sentence Speech Synthesis Based on CVC Speech Units and Evaluation of Its Speech Quality," Records of the Annual Meeting of the IEICE Japan, Tokyo, the Institute of Electronics Information and Communication Engineers (1986).
Honma, S., and R. Nakatsu, "Dialogue Analysis for Continuous Speech Recognition," Record of the Annual Meeting of the Acoustical Society of Japan, pp. 105-106 (1987).
Imamura, A., and Y. Suzuki, "Speaker-Independent Word Spotting and a Transputer-Based Implementation," Proceedings of the International Conference on Spoken Language Processing, pp. 537-540 (1990).
Inmos, The Transputer Data Book, Inmos (1989).
Itahashi, S., "Recent Speech Database Projects in Japan," Proceedings of the International Conference on Spoken Language Processing, pp. 1081-1084, (1990).
Jacobs, T. E., et al., "Performance Trials of the Spain and United Kingdom Intelligent Network Automatic Speech Recognition Systems," Proceedings of the 1st IEEE Workshop on Interactive Voice Technology for Telecommunications Applications IEEE (1992).
Jankowski, C., et al., "NTIMIT: A Phonetically Balanced, Continuous Speech, Telephone Bandwidth Speech Database," Proceedings of the IEEE ICASSP-90, pp. 109-112 (1990).
Kaneda, Y., and J. Ohga, "Adaptive Microphone-Array System for Noise Reduction," IEEE Trans. on Acoustics, Speech, and Signal Process., No. 6, pp. 1391-1400 (1986).
Kimura, T., et al., "A Telephone Speech Recognition System Using Word Spotting Technique Based on Statistical Measure," Proceedings of the IEEE ICASSP-87, pp. 1175-1178 (1987).
Kumagami, K., et al., "Objective Evaluation of User's Adaptation to Synthetic Speech by Rule," Technical Report SP89-68 of the Acoustical Society of Japan (1989).
Page 420
Lippmann, R., et al., "Multi-Style Training for Robust Isolated-Word Speech Recognition," Proceedings of the IEEE ICASSP-87, pp. 705-708 (1987).
Miki, S., et al., "Speech Recognition Using Adaptation Methods to Speaking Style Variation," Technical Report SP90-19 of the Acoustical Society of Japan (1990).
MADCOW (Multi-Site ATIS Data Collection Working Group), "Multi-Site Data Collection for a Spoken Language Corpus," Proceedings of the Speech and Natural Language Workshop, pp. 7-14, Morgan Kaufmann Publishers (1992).
Nagabuchi, H., "Performance Improvement of Spoken Word Recognition System in Noisy Environment," Trans. of the IEICE Japan, No. 5, pp. 1100-1108, Tokyo, the Institute of Electronics, Information and Communication Engineers (1988).
Nakadai, Y., and N. Sugamura, "A Speech Recognition Method for Noise Environments Using Dual Inputs," Proceedings of the International Conference on Spoken Language Processing, pp. 1141-1144 (1990).
Nakatsu, R., "Speech Recognition Market-Comparison Between the US and Japan," Proceedings of the SPEECH TECH '89, pp. 4-7, New York, Media Dimensions Inc. (1989).
Nakatsu, R., "ANSER: An Application of Speech Technology to the Japanese Banking Industry," IEEE Computer, Vol. 23, No. 8, pp. 43-48 (1990).
Nakatsu, R., and N. Ishii, "Voice Response and Recognition System for Telephone Information Services," Proceedings of the of SPEECH TECH '87, pp. 168-172, New York, Media Dimensions Inc. (1987).
Neilsen, P. B., and G. B. Kristernsen, "Experience Gained in a Field Trial of a Speech Recognition Application over the Public Telephone Network," Proceedings of the 1st IEEE Workshop on Interactive Voice Technology for Telecommunications Applications, IEEE (1992).
Nomura, T., and R. Nakatsu, "Speaker-Independent Isolated Word Recognition for Telephone Voice Using Phoneme-Like Templates," Proceedings of the IEEE ICASSP86, pp. 2687-2690 (1986).
Pallet, D., et al., "Speech Corpora Produced on CD-ROM Media by the National Institute of Standards and Technology (NIST)." Unpublished NIST document (1991).
Patterson, D., and D. Ditzel, "The Case for the Reduced Instruction Set Computer," Computer Architecture News, Vol. 8, No. 6, pp. 25-33 (1980).
Picone, J., "The Demographics of Speaker Independent Digit Recognition," Proceedings of the IEEE ICASSP-90, pp. 105-108 (1990).
Pittrelli, J. F., et al., "Development of Telephone-Speech Databases," Proceedings of the 1st Workshop on Interactive Voice Technology for Telecommunications Applications, IEEE (1992).
Pleasant, B., "Voice Recognition Market: Hype or Hope?," Proceedings of the SPEECH TECH '89, pp. 2-3, New York, Media Dimensions Inc. (1989).
Powell, G. A., et al., "Practical Adaptive Noise Reduction in the Aircraft Cockpit Environment," Proceedings of the IEEE ICASSP-87, pp. 173-176 (1987).
Renner, T., "Dialogue Design and System Architecture for Voice-Controlled Telecommunication Applications," Proceedings of the 1st IEEE Workshop on Interactive Voice Technology for Telecommunications Applications, Session IV (1992).
Roe, D. B., "Speech Recognition with a Noise-Adapting Codebook," Proceedings of the IEEE ICASSP-87, pp. 1139-1142 (1987).
Rosenbeck, P., "The Special Problems of Assessment and Data Collection Over the Telephone Network," Proceedings of the Workshop on Speech Recognition over the Telephone Line, European Cooperation in the Field of Scientific and Technical Research (1992).
Rosenbeck, P., and B. Baungaard, "A Real-World Telephone Application: teleDialogue
Page 421
Experiment and Assessment,'' Proceedings of the 1st IEEE Workshop on Interactive Voice Technology for Telecommunications Applications, IEEE (1992).
Sato, H., et al., "Speech Synthesis and Recognition at Nippon Telegraph and Telephone," Speech Technology, pp. 52-58 (Feb./Mar. 1992).
Silverman, H., et al., "Experimental Results of Baseline Speech Recognition Performance Using Input Acquired from a Linear Microphone Array," Proceedings of the Speech and Natural Language Workshop, pp. 285-290, Morgan Kaufmann Publishers (1992).
Sprin, C., et al., "CNET Speech Recognition and Text-to-Speech in Telecommunications Applications," Proceedings of the 1st IEEE Workshop on Interactive Voice Technology for Telecommunications Applications, IEEE (1992).
Starks, D. R., and M. Morgan, "Integrating Speech Recognition into a Helicopter," Proceedings of the ESCA Workshop on Speech Processing in Adverse Conditions, pp. 195-198 (1992).
Steeneken, H. J. M., "Subjective and Objective Intelligibility Measures," Proceedings of the ESCA Workshop on Speech Processing in Adverse Conditions, pp. 1-10 (1992).
Texas Instruments, TMS320 Family Development Support, Texas Instruments (1992).
Tobita, M., et al., "Effects of Acoustic Transmission Characteristics upon Word Recognition Performance," Proceedings of the IEEE Pacific Rim Conference on Communications, Computer and Signal Processing, pp. 631-634 (1989).
Tobita, M., et al., "Effects of Reverberant Characteristics upon Word Recognition Performance," Technical Report SP90-20 of the Acoustical Society of Japan (1990a).
Tobita, M., et al., "Improvement Methods for Effects of Acoustic Transmission Characteristics upon Word Recognition Performance," Trans. of the IEICE Japan, Vol. J73 D-II, No. 6, pp. 781-787, Tokyo, the Institute of Electronics, Information, and Communication Engineers (1990b).
Viswanathan, V., et al., "Evaluation of Multisensor Speech Input for Speech Recognition in High Ambient Noise," Proceedings of the IEEE ICASSP-86, pp. 85-88 (1986).
Walker, G., and W. Millar, "Database Collection: Experience at British Telecom Research Laboratories," Proceedings of the ESCA Workshop 2, 10 (1989).
Wilpon, J. G., et al., "Automatic Recognition of Keywords in Unconstrained Speech Using Hidden Markov Models," IEEE Trans. on Acoustics, Speech, and Signal Processing, Vol. 38, No. 11, pp. 1870-1878 (1990).
Yamada, H., et al., "Recovering of Broad Band Reverberant Speech Signal by Sub-Band MINT Method," Proceedings of the IEEE ICASSP-91, pp. 969-972 (1991).
Yang, K. M., "A Network Simulator Design for Telephone Speech," Proceedings of the 1st IEEE Workshop on Interactive Voice Technology for Telecommunications Applications, IEEE (1992).
































