
First-Person Computational Vision
KRISTEN GRAUMAN
University of Texas at Austin
Recent advances in sensor miniaturization, low-power computing, and battery life have carved the path for the first generation of mainstream wearable cameras. Images and video captured by a first-person (wearable) camera differ in important ways from third-person visual data. A traditional third-person camera passively watches the world, typically from a stationary position. In contrast, a first-person camera is inherently linked to the ongoing experiences of its wearer—it encounters the visual world in the context of the wearer’s physical activity, behavior, and goals.
To grasp this difference concretely, imagine two ways you could observe a scene in a shopping mall. In the first, you watch a surveillance camera video and see shoppers occasionally pass by the field of view of the camera. In the second, you watch the video captured by a shopper’s head-mounted camera as he actively navigates the mall—going in and out of stores, touching certain objects, moving his head to read signs or look for a friend. While both cases represent similar situations—and indeed the same physical environment—the latter highlights the striking difference in capturing the visual experience from the point of view of the camera wearer.
This distinction has intriguing implications for computer vision research—the realm of artificial intelligence and machine learning that aims to automate visual intelligence so that computers can “understand” the semantics and geometry embedded in images and video.
EMERGING APPLICATIONS FOR FIRST-PERSON COMPUTATIONAL VISION
First-person computational vision is poised to enable a class of new applications in domains ranging well beyond augmented reality to behavior assessment, perceptual mobile robotics, video indexing for life-loggers or law enforcement, and even the quantitative study of infant motor and linguistic development.
What’s more, the first-person perspective in computational vision has the potential to transform the basic research agenda of computer vision as a field: from one focused on “disembodied” static images, heavily supervised machine learning for closed-world tasks, and stationary testbeds—to one that instead encompasses embodied learning procedures, unsupervised learning and open-world tasks, and dynamic testbeds that change as a function of the system’s own actions and decisions.
My group’s recent work explores first-person computational vision on two main fronts:
- Embodied visual representation learning. How do visual observations from a first-person camera relate to its 3D ego-motion? What can a vision system learn simply by moving around and looking, if it is cognizant of its own ego-motion? How should an agent—whether a human wearer, an autonomous vehicle, or a robot—choose to move, so as to most efficiently resolve ambiguity about a recognition task? These questions have interesting implications for modern visual recognition problems and representation learning challenges underlying many tasks in computer vision.
- Egocentric summarization. An always-on first-person camera is a double-edged sword: the entire visual experience is retained without any active control by the wearer, but the entire visual experience is not substantive. How can a system automatically summarize a long egocentric video, pulling out the most important parts to construct a visual index of all significant events? What attention cues does a first-person video reveal, and when was the camera wearer engaged with the environment? Could an intelligent first-person camera predict when it is even a good moment to take photos or video? These questions lead to applications in personal video summarization, sharing first-person experiences, and in situ attention analysis.
Throughout these two research threads, our work is driven by the notion that the camera wearer is an active participant in the visual observations received. We consider egocentric or first-person cameras of varying sources—those worn by people as well as autonomous vehicles and mobile robots.
EMBODIED VISUAL LEARNING: HOW DOES EGO-MOTION SHAPE VISUAL LEARNING AND ACTION?
Cognitive science indicates that proper development of visual perception requires internalizing the link between “how I move” and “what I see.” For example, in their famous “kitten carousel” experiment, Held and Hein (1963) examined how the visual development of kittens is shaped by their self-awareness and control (or lack thereof) of their own physical motion.
However, today’s best computer vision algorithms, particularly those tackling recognition tasks, are deprived of this link, learning solely from batches of images downloaded from the Web and labeled by human annotators. We argue that such “disembodied” image collections, though clearly valuable when collected at scale, deprive feature learning methods from the informative physical context of the original visual experience (Figure 1).
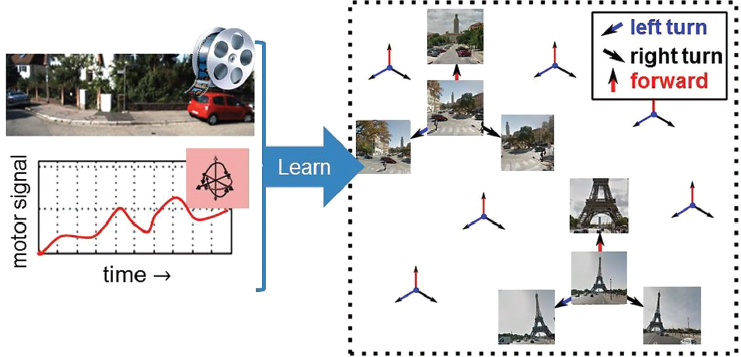
We propose to develop embodied visual representations that explicitly link what is seen to how the sensor is moving. To this end, we present a deep feature learning approach that embeds information not only from the video stream the observer sees but also from the motor actions he simultaneously makes (Jayaraman and Grauman 2015). Specifically, we require that the features learned in a convolutional neural network exhibit equivariance, i.e., respond predictably to transformations associated with distinct ego-motions.
During training, the input image sequences are accompanied by a synchronized stream of ego-motor sensor readings. However, they need not possess any semantic labels. The ego-motor signal could correspond, for example, to the

inertial sensor measurements received alongside video on a wearable or car-mounted camera.
The objective is to learn a function mapping from pixels in a video frame to a space that is equivariant to various motion classes. In other words, the resulting learned features should change in predictable and systematic ways as a function of the transformation applied to the original input (Figure 2).
To exploit the features for recognition, we augment the neural network with a classification loss when class-labeled images are available, driving the system to discover a representation that is also suited for the recognition task at hand. In this way, ego-motion serves as side information to regularize the features learned, which we show facilitates category learning when labeled examples are scarce. We demonstrate the impact for recognition, including a scenario where features learned from “ego-video” on an autonomous car substantially improve large-scale scene recognition.
Building on this concept, we further explore how the system can actively choose how to move about a scene, or how to manipulate an object, so as to recognize its surroundings using the fewest possible observations (Jayaraman and Grauman 2016). The goal is to learn how the system should move to improve its sequence of observations, and how a sequence of future observations is likely to change conditioned on its possible actions.
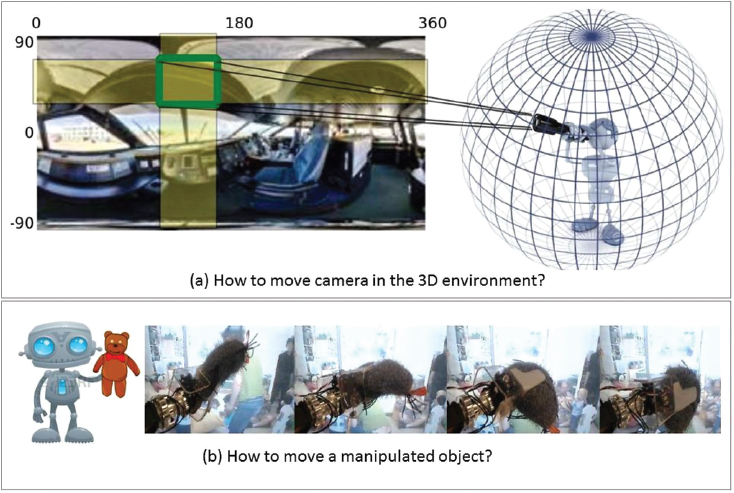
We show how a recurrent neural network–based system may perform end-to-end learning of motion policies suited for this “active recognition” setting. In particular, the three functions of control, per-view recognition, and evidence fusion are simultaneously addressed in a single learning objective. Results so far show that this significantly improves the capacity to recognize a scene by instructing the egocentric camera where to point next, and to recognize an object manipulated by a robot arm by determining how to turn the object in its grasp to get the sequence of most informative views (Figure 3).
EGOCENTRIC SUMMARIZATION: WHAT IS IMPORTANT IN A LONG FIRST-PERSON VIDEO?
A second major thrust of our research explores video summarization from the first-person perspective. Given hours of first-person video, the goal is to produce a compact storyboard or a condensed video that retains all the important people,

objects, and events from the source video (Figure 4). In other words, long video in, short video out. If the summary is done well, it can serve as a good proxy for the original in the eyes of a human viewer.
While summarization is valuable in many domains where video must be more accessible for searching and browsing, it is particularly compelling in the first-person setting because of (1) the long-running nature of video generated from an always-on egocentric camera and (2) the storyline embedded in the unedited video captured from a first-person perspective.
Our work is inspired by the potential application of aiding a person with memory loss, who by reviewing their visual experience in brief could improve their recall (Hodges et al. 2011). Other applications include facilitating transparency and memory for law enforcement officers wearing bodycams, or allowing a robot exploring uncharted territory to return with an executive visual summary of everything it saw.
We are developing methods to generate visual synopses from egocentric video. Leveraging cues about ego attention and interactions to infer a storyline, the proposed methods automatically detect the highlights in long source videos. Our main contributions so far entail
- learning to predict when an observed object/person is important given the context of the video (Lee and Grauman 2015),
- inferring the influence between subevents in order to produce smooth, coherent summaries (Lu and Grauman 2013),
- identifying which egocentric video frames passively captured with the wearable camera look as if they could be intentionally taken photographs (i.e., if the camera wearer were instead actively controlling a camera) (Xiong and Grauman 2015), and
- detecting temporal intervals where the camera wearer’s engagement with the environment is heightened (Su and Grauman 2016).
With experiments processing dozens of hours of unconstrained video of daily life activity, we show that long first-person videos can be distilled to succinct visual storyboards that are understandable in just moments.
CONCLUSION
The first-person setting offers exciting new opportunities for large-scale visual learning. The work described above offers a starting point toward the greater goals of embodied representation learning, first-person recognition, and storylines in first-person observations.
Future directions for research in this area include expanding sensing to multiple modalities (audio, three-dimensional depth), giving an agent volition about its motions during training as well as at the time of inference, investigating the most effective means to convey a visual or visual-linguistic summary, and scaling algorithms to cope with large-scale streaming video while making such complex decisions.
REFERENCES
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L. 2009. ImageNet: A large-scale hierarchical image database. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 20–25, Miami Beach.
Held R, Hein A. 1963. Movement-produced stimulation in the development of visually guided behavior. Journal of Comparative and Physiological Psychology 56(5):872–876.
Hodges S, Berry E, Wood K. 2011. Sensecam: A wearable camera which stimulates and rehabilitates autobiographical memory. Memory 19(7):685–696.
Jayaraman D, Grauman K. 2015. Learning image representations tied to ego-motion. Proceedings of the IEEE International Conference on Computer Vision (ICCV), December 13–16, Santiago. Available at www.cs.utexas.edu/~grauman/papers/jayaraman-iccv2015.pdf.
Jayaraman D, Grauman K. 2016. Look-ahead before you leap: End-to-end active recognition by forecasting the effect of motion. Proceedings of the European Conference on Computer Vision (ECCV), October 8–16, Amsterdam. Available at www.cs.utexas.edu/~grauman/papers/jayaraman-eccv2016-activerec.pdf.
Lee YJ, Grauman K. 2015. Predicting important objects for egocentric video summarization. International Journal on Computer Vision 114(1):38–55.
Lu Z, Grauman K. 2013. Story-driven summarization for egocentric video. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 23–28, Portland, OR. Available at www.cs.utexas.edu/~grauman/papers/lu-grauman-cvpr2013.pdf.
Su Y-C, Grauman K. 2016. Detecting engagement in egocentric video. Proceedings of the European Conference on Computer Vision (ECCV), October 8–16, Amsterdam. Available at www.cs.utexas.edu/~grauman/papers/su-eccv2016-ego.pdf.
Xiong B, Grauman K. 2015. Intentional photos from an unintentional photographer: Detecting snap points in egocentric video with a web photo prior. In: Mobile Cloud Visual Media Computing: From Interaction to Service, eds. Hua G, Hua X-S. Cham, Switzerland: Springer International Publishing.








