
6
Quality Frameworks for Statistics Using Multiple Data Sources
A recurrent theme in the panel’s first report (National Academies of Sciences, Engineering, and Medicine, 2017b), as well as the previous chapters of this report, is that the quality of administrative and private-sector data sources needs careful examination before being used for federal statistics. The theme and the caution have been driven by the relatively recent novelty of the simultaneous use of multiple data sources and the fact that some potential new sources of data present new issues of data quality.
We begin this chapter with a discussion of quality frameworks for survey data and then briefly review additional quality features and some extensions of these frameworks for administrative and private-sector data sources. We then consider how different data sources have been or could be combined to produce federal statistics, with examples to illustrate some of the quality issues in using new data sources.
A QUALITY FRAMEWORK FOR SURVEY RESEARCH
The science of survey research has its origins in the provision of quantitative descriptive data for the use of the state beginning in the 17th century. In general, the approach was to enumerate the whole population (censuses) to provide a description of the population to rulers and administrators. Over time, the increasing demands for information by states for both planning and administrative functions placed greater strains on the capacity of national statistical offices to provide the data, particularly in a timely manner.
The International Statistical Institute, founded in the second half of the 19th century, brought together the chief statistical officers of developed countries, including some leading academic scholars. At its convention in 1895, the chief statistician of Norway, Anders Kiaer, proposed a radical innovation—to collect information on only a subset of the population, a representative sample. Over a period of 30 years, statisticians refined the ideas he presented and developed the form of the sample survey that remained the foundation of the collection of policy-related statistical data throughout the 20th century.
Beginning in the 1930s, statisticians worked on identifying sources of error in survey estimates, and when possible, measuring their effects. All these components are combined in the total survey error framework shown in Figure 6-1. The basic inferential structure of the sample survey involves two separate processes. The first is a measurement inference, in which the questions answered or items sought from a sample unit are viewed as proxies for the true underlying phenomenon of interest. For example, every month interviewers asked a sample person: “what were you doing
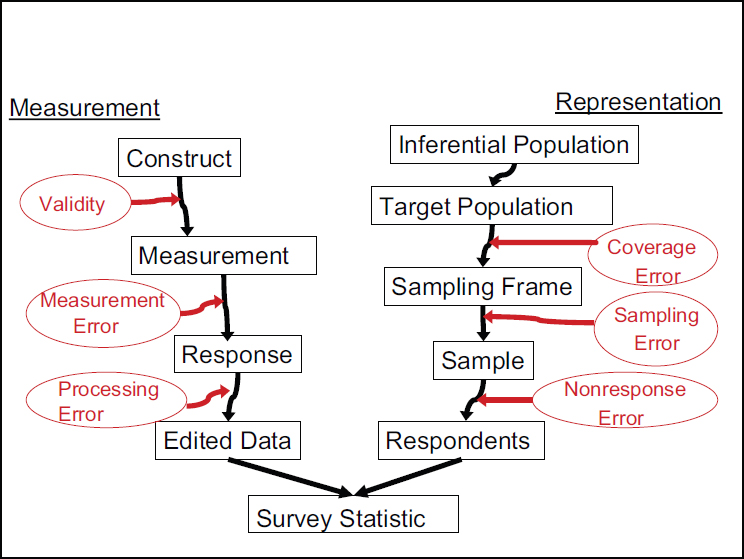
SOURCE: Adapted from Groves et al. (2009, p. 48).
last week (the week of the 12th)?” as a key item for the statistic that is labeled as the monthly employment rate. There is a difference between the measurement of behavior for the week of the 12th and the concept of an unemployment rate for the whole month. The inference being made is complicated and threatened in months in which labor strikes occur in the middle of the month as the status of that week is unlike that of other weeks in some other way.
Another example, and one that provides a clearer notion of measurement inference, can be seen when the underlying concept is clearly unobservable without a self-report. Various attributes of human knowledge fit this case well. For example, the Trends in International Mathematics and Science Study (TIMSS) assesses mathematics knowledge among students in grades 4 and 8. Knowledge of mathematics is often measured through problems that can be solved only by those people with the requisite knowledge. There are many types of mathematics problems and thousands of instances of every type of mathematical knowledge. In some cases, there are an infinite number of ways to measure a type of mathematics knowledge. Each problem, therefore, might be viewed as one sample from that infinite population. And since each problem exhibits its own variability over conceptually repeated administrations, measuring mathematics knowledge with multiple problems increases the stability of an estimate. In this case, an inference is drawn from a question or set of questions to the underlying unobservable mathematics knowledge.
The second inferential step concerns the measurement of a subset of units of the target population. In this case, inference based on probability sampling is the foundation of government statistical agencies throughout the world. The inference, however, needs careful descriptions of the target population and the frame population: in an ideal situation, the frame has a one-to-one correspondence to the full population of interest, the target population. Government statistical agencies strive to create and maintain such universal frames for households and businesses. Some countries attempt to construct frames of people through population registers.
For each error source shown in Figure 6-1, one can further distinguish two kinds of errors: (1) biases, which represent systematic errors that are integral to the process and would therefore not be ameliorated without a change in the process; and (2) variances, which represent instability in the estimates and depend on the number of units of a particular kind included in the data collection. Variance can be reduced by increasing the number of units of that kind.
Federal statistical agencies are very sensitive to the potential errors in their surveys. Their primary focus has been on the fact that data are collected on only a sample of the population, as it is this feature that distinguishes surveys from a complete population census. Many of the most
widely used sampling and estimation procedures for surveys were developed at the U.S. Census Bureau in the 1930s and 1940s. Other statistical agencies have also been leaders in the provision of detailed information on sampling errors (measures of precision for survey estimates), and most federal surveys produce detailed tables of standard errors for their estimates. Other aspects of data quality have been given less emphasis, though agencies have conducted important investigations of some nonsampling errors in major surveys.
There has also been some work to apply the same ideas of statistical inference to some other forms of measurement error (response error in surveys) particularly, models of interviewer effects (interviewer variance), using the concepts of simple and correlated response variance (by analogy with simple and correlated sampling variance), and looking at instability in responses (reliability). These models were refined by U.S. and other statistical agencies in the 1960s, 1970s, and 1980s. A major conceptual push toward the examination of measurement error occurred as a result of work on cognitive aspects of survey methods, which examined the psychological mechanisms that influence respondents’ understanding of questions and retrieval of information (see National Research Council, 1984). The major statistical agencies set up cognitive laboratories to incorporate these principles into the design of questions used in their surveys (see Tanur, 1999).
Concern about nonresponse has also been a feature of quality control in statistical agencies, and the emphasis has most often been on maximizing the response rate. The standards and guidelines for statistical surveys issued by the U.S. Office of Management and Budget (2006) stipulated standards for the collection of statistical information that included a high threshold for response rates (80 percent) and a detailed protocol for evaluating errors if the response rate is below this threshold. However, there is generally no reporting mechanism that quantifies the effect of nonresponse in a way that corresponds to the routine publication of standard errors. This reflects a general emphasis on variances (stability) rather than biases, as well as the ability to calculate standard errors directly from the sample, while determining nonresponse bias requires information external to the survey.
Some federal statistical agencies have created “quality profiles” for some major surveys to bring together what is known about the various sources of error in a survey. This was first done for the Current Population Survey in 1978 (Federal Committee on Statistical Methodology, 1978) and was also done for other surveys (see, e.g., National Center for Education Statistics, 1994; U.S. Census Bureau, 1996, 1998, 2014b). The Census Bureau currently includes this kind of information in design and methodology reports for the Current Population Survey and American Community Survey (see U.S. Census Bureau, 2006, 2014a).
CONCLUSION 6-1 Survey researchers and federal statistical agencies have developed useful frameworks for classifying and examining different potential sources of error in surveys, and the agencies have developed careful protocols for understanding and reporting potential errors in their survey data.
Effectively using frameworks for the different sources of error in surveys requires agencies to provide information or metrics for reporting on survey quality. A subcommittee of the Federal Committee on Statistical Methodology (2001) reviewed the different kinds of reports produced by statistical agencies and the amount of information provided about the different sources of error in each and further provided guidance to agencies on measuring and reporting sources of error in surveys. It recommended the minimum amount of information that should be provided, which depended on the length and detail of the report.
Measures of sampling error (estimates of the variability in the estimates due to sampling) are the most commonly reported metric of quality across all agency reports (see Federal Committee on Statistical Methodology, 2001). These measures include standard errors or coefficients of variation, and they are often the only quantitative indicator of quality reported by the agency. Other error sources are noted in more general narrative form, such as statements that surveys are also subject to nonsampling errors. Since standard errors are typically the only quantitative metric available at the estimate level, it is easy for users to conclude that this measure conveys the overall quality of the estimate.
The second principal metric of quality often used in official statistics is the response rate, which is also a very imperfect metric of quality. Low response rates do not, by themselves, indicate poor-quality statistics. Instead, lower rates indicate a higher risk of nonresponse error. Similarly, high response rates provide important protection against the potential for nonresponse bias. However, this is an area in which the direct collection of ancillary data (paradata) could facilitate a more comprehensive assessment of the danger of the vulnerability of survey results to bias arising from nonresponse. Furthermore, access to other data sources (administrative or private sector) could also provide validating (or invalidating) evidence. And in some cases paradata could provide a basis for imputing data when a survey failed to obtain information directly. In this instance, the incorporation of additional data would supplement or validate, rather than replace, the survey data.
CONCLUSION 6-2 Commonly used existing metrics for reporting survey quality may fall short in providing sufficient information for evaluating survey quality.
BROADER FRAMEWORKS FOR ASSESSING QUALITY
There is considerable inertia in any long-established system. Consequently, the evaluation of the quality of any statistic tends to be seen through the lens of the current dimensions of focus and concern. In the new environment in which emerging data sources with quite different provenance and characteristics provide alternative ways of measuring the underlying phenomena, it may be necessary to rethink the weight that is placed on traditional measures of quality relative to other quality measures.
There are broader quality frameworks that emphasize the granularity of the data and the estimates in ways that were previously not possible. An influential quality framework has been developed by Eurostat, the Statistical Office of the European Union (European Statistical System Committee, 2013) (see Box 6-1). This framework has five major output quality components:
- Relevance
- Accuracy and Reliability
- Timeliness and Punctuality
- Accessibility and Clarity
- Coherence and Comparability
It is worth noting that all the technical aspects of the total survey error model discussed above are encompassed by just one of the above five output quality components—accuracy and reliability. Of course, many of the others are critical in determining what information is collected and disseminated, in particular, relevance. The criterion of coherence also makes important demands on the process by requiring that the estimates are consistent internally and comparable across subsets of a population. Maintaining relevance and coherence may be a particular challenge in moving from one system or configuration to another. This challenge is exacerbated in the case of surveys by the length of time it takes to develop and test survey components, leading to a lack of nimbleness in response to changes in circumstances and policy requirements.
Two aspects of data quality in particular warrant emphasis here: timeliness and spatial and subgroup granularity.
Timeliness
Though timeliness is described in the European Statistical System Committee’s quality framework in terms of the timing and punctuality of reports, it is important to recognize that existing systems have tailored their reporting mechanisms and their reporting requirements to the practical constraints and limitations in place at the time the systems were established. For example, the unemployment rate, calculated from the Current Population Survey (CPS), is published monthly based on information collected about a single week in the preceding month. When the system was established in the 1940s, this schedule (and basis) was at the outer limits of feasibility and practicality for a national survey. Changes in the data environment have made the range of possibilities much broader, and, therefore, the assessment of quality should now incorporate this new context.
For policy purposes, it is particularly important that information be available to decision makers in time to incorporate it into the decision-making process. Data collected through surveys tend to have a minimum interval between the beginning of data collection and the production of the estimate. Even with the CPS, there is a lag of about 3 weeks between the reference period for the survey responses and the production of the estimate. With some private-sector data that is captured electronically, the time lapse between the event being measured and the availability of the data is, in principle, negligible (though in practice this may not be the case).
In this context, one needs to think about the value of this aspect of statistical estimates and the particular use to be made of the estimate. With prices (see the discussion in Chapter 4 of the panel’s previous report), the current (old-fashioned) process of visiting stores to collect price information has the virtue of providing almost comprehensive coverage (through
probability sampling) of the population of stores, but it suffers from a considerable time lag in reporting. Data from the Internet, in contrast, can be harvested in a timely manner but may miss differentially key sectors of the population of stores. Researchers and analysts need to be able to evaluate the relative importance of timeliness and coverage for each particular purpose of a statistic. If the purpose is to provide early warning of price changes, one might argue that the Internet data, though deficient in coverage terms, would function better than the more comprehensively representative survey data. If the purpose is to provide an estimate that gives an unbiased measure of change in prices for the population as a whole, the argument would swing in favor of the probability sample of stores. Combining the sources offers the potential to improve the timeliness of estimates from probability samples and reduce the bias present in Internet data.
Spatial and Subgroup Granularity
A second important aspect of quality is the degree to which estimates can be obtained for small subdivisions of the population, such as spatial subdivisions or different socioeconomic status categories. In census and survey statistical terminology, these estimates are usually referred to as small-area statistics. The practical limitation on the size of the sample that can realistically be afforded for traditional surveys places a severe limit on the ability to provide reliable small-area statistics. With private-sector data, such refinement of the estimates may be accomplished at low marginal cost once the system processes have been put in place. The value to policy makers at a national level of having information at this more detailed level can be considerable and could compensate for some loss of quality on the dimensions of accuracy and reliability.
All of these considerations point to the importance of recognizing the need to evaluate quality in a more broad-based way. By combining data sources (as described in Chapter 2 and in the examples in this chapter, below), hybrid estimates can be produced that come close to possessing the positive quality aspects of the components used to construct them.
CONCLUSION 6-3 Timeliness and other dimensions of granularity have often been undervalued as indicators of quality; they are increasingly more relevant with statistics based on multiple data sources.
RECOMMENDATION 6-1 Federal statistical agencies should adopt a broader framework for statistical information than total survey error to include additional dimensions that better capture user needs, such as timeliness, relevance, accuracy, accessibility, coherence, integrity, privacy, transparency, and interpretability.
ASSESSING THE QUALITY OF ADMINISTRATIVE AND PRIVATE-SECTOR DATA
Administrative Data
Administrative and private-sector data have their own challenges and errors. These errors arise for multiple reasons, such as mistakes in understanding or interpreting metadata, errors in entity linkage, and incomplete or missing information. Unlike handling data from traditional surveys, these errors usually need to be dealt with after the data have been obtained and been through cleaning and processing (see Chapter 3). That is, the errors can usually not be avoided during data gathering or generation because the processes that generate the data have their own purposes: that is, unlike surveys, the production of the statistic is secondary to another objective. In contrast, survey designers spend a great deal of time and effort developing and pretesting survey instruments to ensure they are obtaining the information they want from respondents and minimizing measurement errors. Electronic survey instruments often include consistency checks and acceptable ranges of responses to further ensure that potential problems with data entry or responses are resolved at the point of collection.
Data Linkage and Integration
The use of administrative and private-sector data not only shifts the focus of reducing errors into the postdata gathering stage, it also adds a new error source that is not usually encountered in surveys: linkage errors. In many instances, it is necessary to match data related to the same real-world entities, even if they are identified in different ways. As we note in Chapter 2, many linkage variables have variants: the same person might be listed in different data sources as “Susan Johnson Wright,” “Suzy Johnson,” “Sue Wright,” or “S.J. Wright.” Failure to recognize these as belonging to the same person will result in records being declared distinct when they ought to be linked—a missed link. Conversely, there may be multiple Susan Wrights in the population, and two records may match exactly on the identifying variables yet represent two different people—a false link. Missed links and false links can distort relationships among variables in the data sources or result in inaccurate measures of the population size when linkage is used to augment the number of records available for study.
In the case of a potential false link, one would need to look at other evidence, such as an address, to determine whether it is the same person. However, this is complicated, because people do move, so one would have to distinguish between the same person who has changed addresses and a different person who just happens to have the same name. And in the case
of matching individuals to themselves, there is the complication of the difficulty to match an individual after a name change, say, due to marriage or simply an interest in changing one’s name. Additional difficulties of linking individuals could also include joint bank accounts, accounts that have only one spouse’s name, and parents or others paying for a service for a child or other relative.1 In short, good entity matching is very hard. However, there is much active research work in this area and a significant body of technology that can be exploited for this work.
Most data of interest to statistical agencies is likely to have a temporal component. Each fact will represent either an instant in time or a period of time. It is likely that the time frames for data reporting will not perfectly line up when integrating data sources. In such circumstances, techniques are needed to proceed with integration and, if at all possible, without introducing too much error. For instance, where reported aggregates change smoothly over time, some type of interpolation may be appropriate. For example, where certain secondary information, such as North American Industry Classification System codes or dictionary terms, is largely static, one may reasonably assume it has the same value at the time of interest as at another time.
Similar issues also arise for geographical alignment: if some data are reported by ZIP code and other data by county, one can integrate them only if one can transform one of the two datasets into a report by the other. Such transformation is complicated by the fact that ZIP code to county is a many-to-many relationship: many ZIP codes can include more than one county and vice versa. Techniques for small-area estimation (see Chapter 2) may be helpful in achieving such temporal and spatial alignment.
CONCLUSION 6-4 Quality frameworks for multiple data sources need to include well-developed treatments of data linkage errors and their potential effects on the resulting statistics.
Concepts of Interest and Other Quality Features
The kinds of statistical models discussed in Chapter 2 when using multiple data sources underscore the need for more attention to quality features that have not received as much attention in traditional statistics (see also Groves and Schoeffel, in press). We note here several issues with regard to administrative data that will need attention.
One core difference with respect to quality for administrative and private-sector data is tied to the concept of interest. Since data are being
___________________
1 Additional concerns arise if consent is required in order to link different datasets (see Chapter 4).
repurposed, the meanings of particular values are likely to be subtly different. A precise understanding of those differences is critical for correct interpretation and difficult due to varying metadata recording standards across data sources. Similarly, population coverage and sampling bias are also of particular concern when repurposing data. Understanding exactly what has been done is a necessary step to ensuring correctness. Finally, repurposing data will often require considerable manipulation. Therefore, recording the editing and cleaning processes applied to the data, the statistical transformations used, and the version of software run become particularly important (see Chapter 3).
It is likely that the population covered by one dataset will not match the population covered by another. Administrative records exist for program participants but not for nonparticipants, and some people may not be in any record system. Some administrative records contain people outside of the population of inference of a survey dataset to which records are to be linked (e.g., voter records may contain dead people formerly eligible to vote). There may be duplicate records in some sources, and it is possible that records from multiple datasets simply cannot be linked. Moreover, it will not be possible to separate linkage errors with coverage errors.
The level of measurement in the multiple data sources may vary. One dataset may be measured on the person level, another on the household level, another on the consumer unit level, another on the address level, and another on the tax unit level, and other data, such as credit card purchases, may be at a transaction level. Errors in statistics can arise due to mismatches when combining data from such different datasets.
The temporal extent of the data may vary. Some administrative data systems are updated on a relatively haphazard schedule, depending on interaction with the client. The result is that time can be variable over records in the same administrative dataset. The value reflects the “latest” version, sometimes with no metadata on the date the value was entered. The data may also contain information on an individual only for the time during which the individual was in a program. As individuals leave the program, they will not have new data recorded about them, but they may also not be removed from the system. Combining records to produce statistics that are designed to describe a population at a given time point is thus problematic.
The underlying measurement construct may differ across datasets. In the total survey error framework, this occurrence is sometimes labeled as an issue of validity or a gap between concept and measurement. For example, in one dataset the value of an economic transaction may capture only the goods or service provided, but in another it may also involve cash given to the customer by the provider but charged to the account of the customer.
The nature of missing data in records may vary across surveys and other sources. In survey data, questions may be skipped for several rea-
sons: because a respondent chooses to terminate participation before the question is posed; because of a refusal to answer the question because the respondent does not want to answer it; or because the respondent does not know the answer.
In addition, in administrative record systems, some data fields may be empty because of their lack of importance to the program: for example, a service clerk did not need the data to execute the task at hand. A field may also be empty because new processes fail to capture the datum. And less important information may not be captured as accurately or as carefully as information that is critical to the immediate administrative task.
As with surveys, some recorded items may be inaccurate because they are misunderstood by the clerk entering the information or by the respondent providing the information. To compensate for missing data, survey-based imputation schemes use patterns of correlations of known attributes to estimate values missing in the records. Those kinds of techniques may need some reassessment for administrative data. For example, unstructured text data appear in many medical record systems. Does the absence of the mention of some attribute mean that the attribute is nonexistent for the patient or that the health provider failed to record the attribute?
Frameworks for Assessing Quality of Administrative Data
In the panel’s first report (National Academies of Sciences, Engineering, and Medicine, 2017b) we concluded that “administrative records have demonstrated potential to enhance the quality, scope and cost efficiency of statistical products” (p. 35), and that “not enough is yet known about the fitness for use of administrative data in federal statistics” (p. 48). Therefore, we made the following recommendation:
Federal statistical agencies should systematically review their statistical portfolios and evaluate the potential benefits and risks of using administrative data. To this end, federal statistical agencies should create collaborative research programs to address the many challenges in using administrative data for federal statistics. (National Academies of Sciences, Engineering, and Medicine, 2017b, Recommendation 3-1, p. 48).
As part of their review of administrative data, agencies need to assess the quality of the data and whether the data are fit for use for their intended statistical purposes (see, e.g., Iwig et al., 2013). Brackstone (1987, p. 32) notes that the quality of administrative records for statistical purposes depends on at least three factors:
- the definitions used in the administrative system;
- the intended coverage of the administrative system;
- the quality with which data are reported and processed in the administrative system.
In the United States, Iwig and his colleagues (2013) created a tool for assessing the quality of administrative data for statistical uses to help statistical agencies systematically obtain the relevant information they need at each stage of the data-sharing process (see Box 6-2). Although the tool is based on quality frameworks from a number of national statistical offices, it is intended to help guide the conversation between a statistical agency and a program agency, rather than provide a comprehensive framework itself.
Administrative records are used by many national statistical offices for producing statistics; however, there have not been statistical theories developed for assessing the uncertainty from administrative data as there have been for surveys (Holt, 2007). There have been efforts to examine the processes that generate administrative data and population registers (see Wallgren and Wallgren, 2007), as well as examinations of measurement errors in both administrative records and survey reports (e.g., see Oberski et al., 2017; Abowd and Stinson, 2013; Groen, 2012). Recently, Zhang (2012) has extended the Groves et al. (2009) model of survey error sources (shown in Figure 6-1) to create a two-phase (primary and secondary) life cycle of integrated statistical microdata. In this model, the first phase covers the data from each individual source, while the second phase concerns the integration of data from different sources, which typically involves some transformation of the original data (see Zhang [2012] for a complete discussion of the model).
Private-Sector Data
Different Types of Data
In our first report (National Academies of Sciences, Engineering, and Medicine, 2017b, p. 57) we noted the enormous amounts of private-sector data that are being generated constantly from a wide variety of sources. We distinguished between structured data, semi-structured data, and unstructured data:
- Structured data, such as mobile phone location sensors, or commercial transactions, are highly organized and can easily be placed in a database or spreadsheet, though they may still require substantial scrubbing and transformation for modeling and analysis.
- Semi-structured data, such as text messages or emails, have structure but also permit flexibility so that they cannot be placed in a relational database or spreadsheet; the scrubbing and transformation for modeling and analysis is usually more difficult than for structured data.
- Unstructured data, such as in images and videos, do not have any structure so that the information of value must first be extracted and then placed in a structured form for further processing and analysis.
The challenges with the quality of these different data sources led to a conclusion and recommendation:
The data from private-sector sources vary in their fitness for use in national statistics. Systematic research is necessary to evaluate the quality, stability, and reliability of data from each of these alternative sources currently held by private entities for their intended use. (National Academies of Sciences, Engineering, and Medicine, 2017b, Conclusion 4-2, p. 70)
The Federal Interagency Council on Statistical Policy should urge the study of private-sector data and evaluate both their potential to enhance the quality of statistical products and the risks of their use. Federal statistical agencies should provide annual public reports of these activities. (National Academies of Sciences, Engineering, and Medicine, 2017b, Recommendation 4-2, p. 70)
The panel thinks it likely that the data to be combined with traditional survey and census data will increasingly come from unstructured text, such as web-scraped data. Converting such data to a more structured form presents a range of challenges. Although errors arise in coding open-ended responses to surveys, the issues with unstructured text compound those errors given the ambiguity of the context and the development and use of coding algorithms, which can result in a special type of processing error. The ambiguity of words—does “lost work” refer to a job termination or a hard disk crash?—will be a constant challenge. The possibility of coding words on multiple dimensions (e.g., meaning and effect) arises. From a quality or error standpoint, a coding error might create a new source of bias if one coding algorithm is used, or a new source of variance in statistics if multiple coding algorithms are used. Training these algorithms using human-coded data essentially builds in any biases that were present in the original human coding. The emergence of computational linguistics since the early days of survey coding may offer help in this aspect of big data quality.
Some of the data used in federal statistics could be combinations of data arising from sensors. For example, traffic sensor data are useful in traffic volume statistics. From time to time, sensors fail, creating missing data for a period of time until the sensor is repaired or replaced. If the probability that the sensor fails is related to volume of traffic or traffic conditions (e.g., when heavy rain or snow occurs), then the existence of missing data can be correlated with the very statistic of interest, creating what survey researchers would label a type of item nonresponse error.
The panel’s first report also discussed the possibility that social media
data might be combined in certain circumstances with survey or census data. Social media data have an error source uncommon in surveys: the possibility that data are generated by actors outside the population of inference. For example, software bots are known to create Twitter posts. The software bots might have handles and profiles that appear to be people, with revealed geographic positions, under the Twitter protocols. However, the data generated by the software bots are not a person- or business-measurement unit eligible for a survey or census measurement. Although this might be viewed as a type of coverage error in traditional total survey error terms, it has such a distinct source that it needs its own attention.
Risks of Private-Sector Data
Although there is considerable potential in the enormous volume of private-sector data, these data carry considerable risks. First, as they are primarily administrative or transactional data collected for purposes related to the transactions they cover, they tend to be less stable in definition and form than federal survey data that are collected specifically for statistical purposes. Consequently, statistical agencies need to be cautious in relying on these data as a primary (or, especially, sole) source of information; private-sector data are vulnerable to being changed or discontinued without notice. Second, statistical agencies do not have control over the creation and curation of the data; there is the possibility of deliberate manipulation or “front-running” by private-sector data companies providing data to government agencies: that is, if the data supplied by a private-sector entity constituted a sufficiently influential portion of a statistic so that the entity itself could predict the agency’s results, the entity could profit by selling this information to others or by acting on it directly. Third, the data themselves could be subject to manipulation for financial gain.
Quality Frameworks
There have been some recent efforts to extend the total survey error framework to include big data (see Biemer, 2016; Japec et al., 2015; U.N. Economic and Social Council, 2014; U.N. Economic Commission for Europe [UNECE], 2014). The UNECE model is a multidimensional hierarchical framework that describes quality at the input, throughput and output phases of the business process (see Box 6-3).
Biemer (2016) and Japec et al. (2015) similarly distinguish between the phases of generation of the data, the extraction/transformation/load of the data, and the analysis of the data. In this scheme, data generation errors are analogous to survey data collection errors and may result in erroneous, incomplete, or missing data and metadata. Extraction/transformation/
load errors are similar to survey processing errors and include errors in specification, linking, coding, editing, and integration. Analysis errors are analogous to modeling and estimation errors in surveys and also include errors in adjustments and weighting, which may reflect errors in the original data or in filtering and sampling the data. Both models attempt to provide an overall conceptual view of errors in a broad array of data sources and a language to describe these errors; however, neither of the models has yet been applied to a variety of sources by researchers or analysts.
Hsieh and Murphy (2017) have taken a more specific approach and described error sources for a specific social media data source, creating a “total Twitter error.” The authors posit that major classes of errors occur during the data extraction and the analysis process.
CONCLUSION 6-5 New data sources require expanding and further development of existing quality frameworks to include new components and to emphasize different aspects of quality.
CONCLUSION 6-6 All data sources have strengths and weaknesses, and they need to be carefully examined to assess their usefulness for a given statistical purpose.
RECOMMENDATION 6-2 Federal statistical agencies should outline and evaluate the strengths and weaknesses of alternative data sources on the basis of a comprehensive quality framework and, if possible, quantify the quality attributes and make them transparent to users. Agencies should focus more attention on the tradeoffs between different quality aspects, such as trading precision for timeliness and granularity, rather than focusing primarily on accuracy.
As we note in previous chapters, expanding the use of data sources for federal statistics also requires expanding the skills of the statistical agency staff to address the new issues that arise when using these new data sources. Researchers and analysts who are trained in survey methodology have a solid foundation for conceptualizing and measuring different error sources, but expertise and training is also needed in computer science for processing, cleaning, and linking datasets and the errors that can arise in these operations. In addition, specific expertise is needed in the data generating mechanisms and current uses of different administrative and private-data sources that an agency is considering for use for statistical purposes.
RECOMMENDATION 6-3 Federal statistical agencies should ensure their statistical and methodological staff receive appropriate training in various aspects of quality and the appropriate metrics and methods for examining the quality of data from different sources.
THE QUALITY OF ALTERNATIVE DATA SOURCES: TWO ILLUSTRATIONS
In this section we provide two examples of the current approach for generating federal statistics and of existing different data sources that could be used. The two examples are measuring crime and measuring inflation. We discuss how some key quality characteristics of these sources might interact and permit enhanced federal statistics if these sources were combined. Our goal here is illustrative rather than prescriptive, and the responsible federal statistical agencies would need to conduct a much more in-depth review of the alternative sources and the methods for combining them than we can do here.
Measuring Crime
Current Approach
The National Crime Victimization Survey (NCVS) of the Bureau of Justice Statistics (BJS) is the nation’s primary source of information on
criminal victimization.2 Since 1973, data have been obtained annually from a nationally representative sample of about 90,000 households, comprising nearly 160,000 people, on the frequency, characteristics, and consequences of criminal victimization in the United States. The NCVS screens respondents to identify people who have been victims of nonfatal personal crimes (rape or sexual assault, robbery, aggravated and simple assault, and personal larceny) and property crimes (burglary, motor vehicle theft, and other theft), and it includes crimes whether or not they have been reported to the police. For each crime incident, the victim provides information about the offender, characteristics of the crime, whether it was reported to the police, and the consequences of the crime, including the victim’s experiences with the criminal justice, victim services, and health care systems. In addition, there is a wealth of additional information collected—including a victim’s demographic characteristics, educational attainment, labor force participation, household composition, and housing structure—that is related to risk of victimization (see Langton et al., 2017; National Academies of Sciences, Engineering, and Medicine, 2016a).
Despite the appearance of being comprehensive, the NCVS has its quality challenges:
- Not everyone can be reached for an interview, and if people who spend large amounts of time outside their homes are more likely to be at risk for victimization, crimes can be missed.
- Of the people who are reached, not all are willing to participate in the survey, introducing the possibility for bias if those who choose not to participate differ from those who do.
- Not everyone is willing to report crimes that happen to them.
- Some respondents may misunderstand the questions asked.
- Careful testing of measurement instruments and long redesign processes lead to lags in capturing emerging crimes, such as identity theft.
- Data collection takes considerable time, so that annual estimates are only available months after the end of the year in which the crimes occurred.
Alternative Approaches
Alternative data sources on crime include the Uniform Crime Reports (UCR), which is based on police administrative records. The UCR Summary System covers jurisdiction-level counts of seven index crimes that are collated and published by the FBI. The scope of this collection has remained
___________________
2 See https://www.bjs.gov/index.cfm?ty=dcdetail&iid=245#Collection_period [August 2017].
essentially constant since 1929. Several features make the UCR an attractive alternative. The UCR is intended to be a census of about 18,000 police departments covering the whole country; however, there are lots of missing data. It provides consistent classification over time, with only modest periodic changes: arson was added in 1978, and hate crimes in the 1980s. The UCR also can provide monthly data, allowing for finer granularity in time, as well as granularity in geography because of the jurisdiction-level counts of the major crime categories.
However, the UCR also has its own errors and limitations (Biderman and Lynch, 1991; Lynch and Addington, 2007):
- It is restricted to crimes reported to the police, and the NCVS has found that more than 50 percent of crimes reported by victims are not known to the police.
- The data are reported at the jurisdiction level and cannot be disaggregated. That is, one cannot obtain counts of offenses or rates of crimes for a subjurisdictional area or any subpopulation in the jurisdiction.
- There is virtually no information provided on the characteristics of victims or offenders or the circumstances of the incident.
- Police jurisdictions map poorly onto census classifications of places that serve as the denominator of crime rates.
- There is little enforcement of standards of reporting. Although the FBI provides training and audits to check for appropriate counting and classification of offense, there is no way to ensure that all eligible crimes are included. (The FBI collates the reported data but does not provide a warrant of quality.) Occasional audits are performed on a small number of agencies annually, but they focus on counting rules and proper classification and not on the completeness with which eligible incidents are reported. Police agencies may also misreport or misclassify crimes: for example, the Los Angeles Times found that nearly 1,200 violent crimes had been misclassified by the Los Angeles Police Department as minor offenses, resulting in a lower reported violent crime rate.3
- The system is voluntary at the national level. There are mandatory reporting laws in states that require that local police report to the states, but there are no requirements to report to the UCR. There are also few instances in which a state mandatory reporting law has been invoked for a jurisdiction’s failure to report. In addition, unit missing data is assessed on the basis of jurisdictions that have
___________________
3 See http://www.latimes.com/local/la-me-crimestats-lapd-20140810-story.html [August 2017].
previously reported to the UCR, so units that have never participated are not counted as missing.
In addition to the data available in the Summary System, the UCR also includes the National Incident Based Reporting System (NIBRS), which contains data on crime incidents rather than jurisdiction-level counts. Currently, however, this data system is available only in a relatively small proportion of police agencies, and it substantially underrepresents the larger jurisdictions that contain most of the crime.
This would appear to be a situation in which combining data from the different sources (see Chapter 2) could greatly enhance the value of the estimates. BJS’s small-area estimation program (see National Academies of Sciences, Engineering, and Medicine, 2017b, Ch. 2) illustrates how the UCR Summary System and the NCVS could be used jointly to increase understanding of crime in states and other subnational areas (see also Li et al., 2017). As NIBRS, through the National Crime Statistics Exchange (NCS-X),4 is implemented more broadly across the nation, the blending of NCVS and NCS-X data could be done at the incident level, which would substantially increase the ability to leverage the two data sources. The fact that both NCS-X and NCVS are sample based may pose problems for such estimates, but the emphasis on large cities in both data collections may afford sufficient overlap for useful estimation.
Measuring Inflation
Current Approach
The Consumer Price Index (CPI), produced by the Bureau of Labor Statistics (BLS), provides monthly data on changes in the prices paid by urban consumers for a representative basket of goods and services. The CPI has three major uses. First, the CPI is an economic indicator and the most widely used measure of inflation. Second, the CPI is a deflator of other economic series: the CPI and its components are used to adjust other economic series for price inflation and to translate them into inflation-adjusted dollars. Third, the CPI is used to adjust wages: more than 2 million workers are covered by collective bargaining agreements that tie wages to inflation.5
BLS produces thousands of component indexes, by areas of the country,
___________________
4 The NCS-X program is designed to generate nationally representative incident-based data on crimes reported to law enforcement agencies. It comprises a sample of 400 law enforcement agencies to supplement the existing NIBRS data by providing their incident data to their state or the federal NIBRS program. See https://www.bjs.gov/content/ncsx.cfm [September 2017].
5 See https://www.bls.gov/cpi/cpifaq.htm#Question_6 [August 2017].
by major groups of consumer expenditures, and for special categories, such as services. In each case the index is based on two components—the “representative basket of goods” and the price changes in that basket of goods. The market basket of goods is based on the Consumer Expenditure Survey (CE), which is a household survey conducted each year in a probability sample of households selected from all urban areas in the United States. In one part of the survey, 7,000 households are interviewed each quarter on their spending habits; an additional 7,000 families complete diaries for a 2-week period on everything they bought during those 2 weeks. The CE produces a picture of the expenditure patterns of households and selected subgroups, in terms of the quantities of different products and services they bought during the period. These are combined across the households in the sample to provide a picture of the total expenditure patterns of the U.S. household population and for subsets of that population. The weight for an item is derived from reported expenditures on that item divided by the total of all expenditures. The most recent CPI market basket is based on data from CE for 2013 and 2014.
Separate surveys and visits to retail stores are conducted by BLS to obtain prices for goods and services used to calculate the CPI, which are collected in 87 urban areas throughout the country, covering about 89 percent of the total U.S. population and about 23,000 retail and service establishments. Data on rents are collected from about 50,000 landlords or tenants.
These massive data collection efforts are facing challenges. As we described in our first report, response rates for the Consumer Expenditure interview and diary surveys have declined (National Academies of Sciences, Engineering, and Medicine, 2017b, Ch. 2). Another major source of error in the CE is the quality of the measurement of expenditures, given that respondents are exposed to very lengthy questionnaires with many recall tasks. Facing many questions in a row about their expenditures and details about each expenditure item, respondents are likely to underreport and so shorten the interview (or skip recording items in the diary) in order to reduce the reporting burden (see National Research Council, 2013a). And, as for the NCVS, some people are not willing to participate in the survey, reducing the precision of the resulting estimates and possibly introducing bias (National Research Council, 2013b).
Alternative Approaches
The explosion in the availability of online consumer data suggests that this is an area in which there is enormous potential to use alternative data to supplement or replace the current measurement of inflation. One example of such an effort is the Billion Prices Project (BPP): it was initi-
ated in 2007 to provide an alternative inflation index for Argentina, given widespread distrust of the official level reported by the national statistical office, and has since expanded to cover almost 80 countries (Cavallo and Rigobon, 2016). The objective of BPP was to substitute the collection of prices using web-scraping instead of visiting retail stores in person to collect prices. Although the data are dispersed across hundreds of websites and thousands of web pages, advances in automated scraping software now allow design and implementation of large-scale data collections on the web.
The main advantage of web-scraping is that sampling and nonresponse errors are minimized—and in some circumstances they might go to zero.6 Furthermore, detailed information can be collected for each good, and new and disappearing products can be quickly detected and accounted for. Online data collection is cheap, fast, and accurate, making it an ideal complement to traditional methods of collecting prices, particularly in categories of goods that are well represented online, such as food, personal care, electronics, clothing, air travel, hotels, and transportation. In addition to being well-represented online, these sectors reflect prices that are close to the prices from all transactions (i.e., offline transactions are the same prices), making the data of high quality. In some sectors the data quality is less desirable. Gasoline is an example: gasoline is not bought online, and the prices are collected by third parties and then shown online. The quality of this procedure depends dramatically on how the data are collected and curated before they are shown. Because information about prices on the web may be very good in some sectors but seriously deficient in others, there is a continuing challenge to develop a described, researched error structure for a hybrid approach, which would combine information from different sources to calculate an index of inflation.
To create an inflation index, consumption quantities are needed in addition to prices. Information on quantities is essentially nonexistent online (at least not accessible through web-scraping). For the BPP, the consumption quantities (i.e., the data to construct the weights) come from a combination of the CE and inferences on how the web pages are organized. Therefore, the construction of online-based inflation indexes uses a hybrid approach of survey and alternative data sources, both the prices and quantities.
___________________
6 Nonresponse errors would be zero if all selected websites were able to be scraped. Sampling errors would be zero if the relevant universe was completely covered.
























