
8
Recent Trends in Machine Learning, Part 3
DOMAIN ADAPTATION
Judy Hoffman, Georgia Institute of Technology
Judy Hoffman, Georgia Institute of Technology, said that both the machine learning and computer vision communities believe that their models work well, particularly when they have access to a lot of data and the ability to use deep learning approaches to train the models. Looking at things such as challenge performance over time reinforces that notion. In the ImageNet classification challenge, Hoffman’s team found that performance started to approach near perfect on the test set; this improvement came as a result of leveraging millions of training examples effectively and expanding capacities of models over time. While people expect similarly strong performance in real-world applications, such stellar performance is unlikely. This is disconcerting because the problem may be bias in the training data rather than any perturbations (as with adversarial examples). Classifiers are often trained with biased data that can be very different from what is found in real-world settings. For example, images scraped from social media sites are limited by what people choose to post on social media (e.g., images tend to have good lighting, composition, and resolution). Another example is image segmentation for autonomous vehicles, where bias can impact the interpretation of images (e.g., a model trained on images of roads from a sunny location may struggle to recognize snow-covered features).
To address these types of problems, domain adaptation can take a model that was trained under a set of biases and generalize or adapt it for use in new visual environments, without requiring significant human intervention. Domain adaptation requires access to a large, unlabeled data set representing a new environment that does not quite match the visual statistics of the original data set used to train the model. The model can adapt to this new data and learn to overcome differences and biases between the two visual environments.
Before deep learning was being used for domain adaptation, a common practice was to use a source representation, extract a high-dimensional vector that represented the data, and use that representation to learn a classifier on labeled source data. Classifiers were often blamed when there was a misalignment between the representation space on the source and the target. Earlier deep learning approaches relied on
simple statistical techniques such as mean alignment; later, higher-order statistical alignment techniques were utilized. Today’s technique bounds the target error by the discrepancy. The theoretical literature in domain adaptation allows for a probabilistic upper bound on the expected error in the deployment setting.
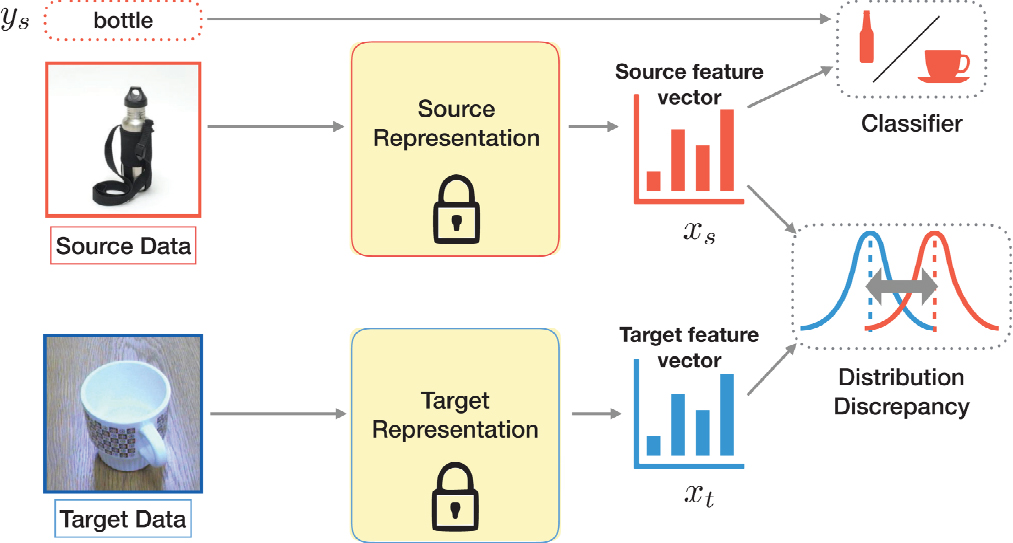
Now that deep domain adaptation is possible, images can be simultaneously represented and classified into relevant objects. This paradigm shift enables representation of images that are invariant to the differences between the first and the second domains. Instead of having a fixed function that separates the data into two distinct biases, end-to-end learnable functions can explicitly supervise those representations so as to be invariant to the differences between the two different collections of data. This can be done by defining a learning objective that aims to minimize the distribution mismatch (see Figure 8.1).
Hoffman emphasized that when trying to improve performance and reduce error in the deployment setting, it is possible to observe that the equation is dependent on how far apart the source and the target are, and it is possible to explicitly minimize that distance. The first challenge is trying to measure that distance; it is possible to empirically approximate the distance between the two distributions by looking at the error of the domain classifier. It is possible to estimate how far apart these two collections of data are by training a classifier in the representation space and evaluating the difference of the features of the two collections. Rama Chellappa, University of Maryland, College Park, asked how this is related to maximum mean discrepancy for domain adaptation, and Hoffman responded that this approach uses a different statistical alignment technique, different learning bounds, and a different algorithm but that the maximum mean discrepancy technique is also relatively easy to implement in practice.
By first training a classifier to differentiate between the source and the target, it is possible to create a minimization function; if it is possible to observe a difference, the collections are far apart in the feature space. Next, the underlying representation is updated by modifying the spatial distribution of the points. Because these data are labeled, these points can be relocated and a deep representation can be inferred. The question at hand is what happens when one tries to view a new collection of data under that same learned representation space. If the two collections are too far apart, the original classifier may not work as well on
the new unlabeled deployment set. In these cases, the distance between the two distributions can be approximated, the classifier can be trained to tell the difference between the target and source images, and the underlying representation can be updated. The object classifier that learned on the source images will now perform better on the unlabeled images from a new visual environment. This is iterated in high dimensions until it is no longer possible to learn a classifier to disambiguate the two sources of data. This gives a learning algorithm that does not require labels in the deployment setting but does make it possible to update the underlying representation so as to learn a domain-invariant feature space. She added that it is also possible to think about domain adversarial learning directly by aligning in pixel space, similar to the work of generative adversarial networks (GANs).
Hoffman shared an example of digit translation to demonstrate the key difference in image-to-image translation with GANs and domain adaptation. The goal is to recognize the different digits observed, assuming there are only labels in one paradigm of a Google Street View data set. This performance will be evaluated in the MNIST (Modified National Institute of Standards and Technology database) data set. With image-to-image translation techniques, it is possible to take the Google Street View and translate it to look like the MNIST digits. However, the standard GAN approach is difficult to optimize and there are issues to consider, such as mode collapse and production of blurry images. An alternate approach is the CycleGAN model, which introduces auxiliary losses that should improve upon the original optimization by adding a new learning objective. She said that it should also be possible to take the inverse stylization to reconstruct the original image, and then, ideally, there would be enough low-level structural information represented in the translated image to assume a better translation than that from the standard GAN model. This generates two learning objectives: a stylization and a reconstruction. However, there are failures with image-to-image translation techniques that can be catastrophic if the goal is to take an image, translate it, and use it to train a better classifier for a new visual environment.
Using the example of Google Street View digits again, Hoffman said that the learned translations are correctly stylized per MNIST, but the corresponding reconstructions have the wrong semantics. This means that it would not be possible to train a classifier on these images for the target setting. However, the end goal of this approach is not to produce the best possible looking image; rather, the goal is to use the image to perform some recognition task. In the large labeled data set, it is possible to train an initial classifier; this classifier does not have perfect performance on MNIST but has strong performance and can be a useful cue overall. Next, another objective is added specifying that the translation should retain the same semantics as judged by the weak classifier. The Google Street View images are translated into images that look like those from the MNIST data set. Since the translated images are not perfect, further feature space alignment is performed. Hoffman showed the performance results for digit recognition using different methods on the unlabeled target data set. A simple digital data set has a low accuracy at 67 percent. This shows how much performance can degrade across different visual environments. Hoffman’s team’s method, CyCADA, generated 90 percent accuracy. Even without using any labels from MNIST, it is possible to use statistical alignment techniques to improve performance from 67 to 90 percent.
Hoffman’s team tried this same approach on a larger problem: semantic segmentation in driving settings. Collecting annotations of driving scenes is expensive and there is large potential for change in the scenes, owing to weather, location, and vehicle. She showed three different settings from these variations where one may opt to use automotive adaptation instead of requiring new labels to recognize similar but different scenes: (1) In the cross-city adaptation example, she trained on the CITYSCAPES data set and looked at performance in testing on a San Francisco data set. Differences exist in the signs, tunnels, and road sizes. Before adaptation, a building is confused with sidewalk/road; after adaptation, the building is recognized correctly. (2) In the cross-season adaptation example, she trained on a fall scene and tested on a winter scene, both synthetically rendered in the SYNTHIA data set. Before adaptation, there was confusion on the parts of the scene covered in snow; after adaptation, the overall statistics of the image were used to adapt the model to understand the environmental change. (3) In the synthetic-to-real pixel adaptation example, she was learning directly from simulated driving imagery using a Grand Theft Auto scene to train to learn to recognize things in a real scene from CITYSCAPES. She took images from the simulated imagery, learned to make them look more realistic, and then performed feature space alignment
to get a real-world model. Adaptation makes it possible to recognize the images more effectively by using overall marginal statistical techniques. Using the mean intersection over the union of the data, it is possible to improve raw pixel accuracy using unsupervised alignment techniques. The algorithm looks at the pixel level and the feature level and examines how to best make changes to the representation so as to still perform original classification tasks but also to learn biases in invariance space.
Hoffman said that the objective of adversarial domain adaptation is to minimize the discrepancy between the source and the target. This can be computed in feature space and/or image space, but she cautioned against letting the domain classifier confuse the model.
Next she turned to a brief discussion of deploying similar techniques in a setting that continues over time and in which a visual scene changes when the task does not (e.g., a camera pointed at a traffic intersection). It is possible to apply domain adversarial learning, but new research questions surfaces. The goal is to have a model that generalizes across different settings, remembers things previously known, reacts when new situations arise, learns quickly from few examples, and proposes scalable solutions. Aram Galstyan, University of Southern California, asked if connections exist to tools for invariance representation learning. Hoffman said that there are connections, and others have also looked at these settings. She said that her research is unique in that she is examining the classifier and the invariance at the same time. She described this as a semi-supervised learning paradigm where performance is important. She said that the most relevant paradigms are those that come from the adaptation community. Tom Goldstein, University of Maryland, wondered if the adaptation is responsible for greying-out the images. Hoffman said yes and noted that image-to-image translation techniques do not have vibrant colorization. He suggested combating that problem by changing the loss function, and Hoffman noted that there are likely additional steps that need to happen. Chellappa asked about short- and long-term issues in the field. Hoffman emphasized the value of rethinking the notion of domains in adaptation literature: What happens before going to continuous? What happens if someone provides a collection of data sets? What is the best way to combine all of this information? She said that there is also a need to address the overall robustness in the adaptation literature, with a focus on better controlling the initial model so it is less susceptible to natural or artificial changes.
EXPLAINABLE MACHINE LEARNING
Anna Rohrbach, University of California, Berkeley
Anna Rohrbach, University of California, Berkeley, discussed techniques that can be useful to expose and combat bias and other problems faced by analysts. Although artificial intelligence (AI) can make fairly accurate predictions, questions arise about whether those predictions can and should be trusted. AI often relies on black boxes, about which the user has no information. She suggested that techniques would be adopted more widely if AI could explain its predictions, thus increasing trust and improving interpretability. Rohrbach and her team’s goal is to improve the interpretability of deep learning by making more introspective modular architectures and by building models that can justify their predictions for users through “storytelling.” Explainability and performance both stand to be improved owing to these measures. Deep models may perform better when augmented with explainable AI (XAI). Target domains include image and video analysis, vehicle control, and strategic games.
Rohrbach discussed three of her team’s innovations during her presentation. The first project is developing more modular, introspective architectures to aid in reasoning. When humans are confronted with a question, they take a series of reasoning steps and analyze relationships before attempting to answer the question. A system can learn to do such step-wise reasoning and deliver human-understandable outputs. She commented on the history of work in this area that was based on supervised layouts for processing the questions. These relied on an external parser to analyze the question and build “expert” layouts to supervise the module choice. As a comparison, the current model has differentiable module choices that are inherently explainable, and the question is represented through recurrent neural networks. The model is end-to-end
trainable with gradient descent so that no reinforcement learning is needed. It can also work on multiple tasks and has compositional behavior without requiring layout supervision. All of the modules contribute to the answer but in a different degree. In a human evaluation, the human users rate the model as “clear” in terms of understandable reasoning; the flexible architecture is inherently interpretable by design.
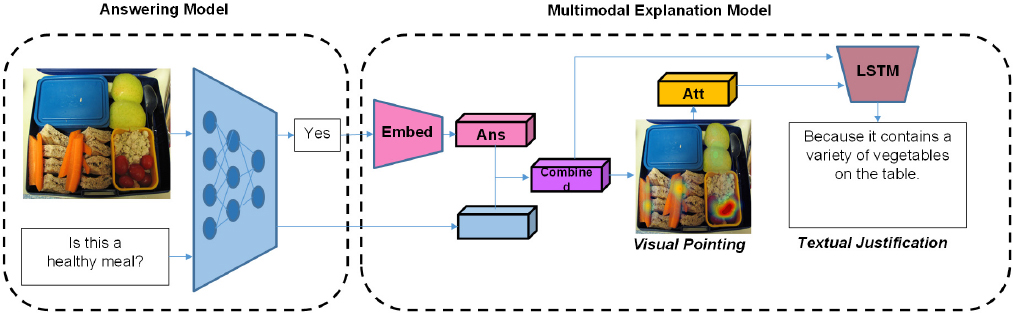
The second project Rohrbach discussed was about textual justification, which is a post-hoc explanation. Providing justifications for responses and pointing to evidence are trivial tasks for humans but not for AI. She explained that any given visual question answering (VQA) architecture or answering model could be augmented with a multi-modal explanation model, which will condition on the visual and question representations, as well as the answer, to predict the textual justification, which will be grounded through the visual pointing mechanism. The only supervision comes from the text that was provided by the human. By doing this, the system can learn to provide human-like justifications (see Figure 8.2).
Rohrbach and her team also found that humans are better at predicting a model’s success or failure when given an explanation; humans benefit from the machine-generated explanation because it helps them decide whether to trust the machine.
The third project Rohrbach presented was about causal factors for visuomotor policies. The objective of this project was to predict vehicle motion and communicate to the human in natural language why a certain driving behavior occurred (i.e., generating textual explanation of how visual evidence is compatible with a decision). The team collected data from the Berkeley DeepDrive data set (a large, crowdsourced collection of driving videos from human drivers) and augmented those with descriptions and explanations. The desired outcome is to have explanations that align with whatever the vehicle controller is seeing in that moment as opposed to providing post-hoc explanations. This could be conveyed as explanations with strongly aligned attention or weakly aligned attention, with the latter working best because it allows the system the freedom to find other evidence to mention, to which the controller does not necessarily need to pay attention. The goal is to develop explanations that are introspective and conditioned on the internal representation of the controller. However, there is currently no temporal reasoning across all of the video segments, which can lead to mistakes in explanations. In the future, to get the system to focus on more interesting but perhaps less common events or objects (e.g., pedestrians), it is important to bias the system toward categories that are more significant for humans.
Summarizing the results of these three projects, Rohrbach said that the multi-step introspection model learns to reason and allows users to better predict model performance via intermediate visualizations. She said that this is a goal for all systems but is not trivial to adapt to other domains. She said that the textual justification model can predict expert rationales in a variety of domains and is useful for understanding
category differences. She added that causal XAI provides introspection into driving behavior and helps obtain grounded human understandable explanations.
A workshop participant asked Rohrbach if her team has tried applying the justification to naturally occurring or intentionally generated adversarial images. Rohrbach said that although they have not tried that yet, they have done something related for VQA. They have performed an adversarial attack and visualized the attention to see where the model is “looking.” The attack forces it to find evidence to justify the incorrect answer (i.e., it often fools the model in an interpretable way). A workshop participant observed that the explanations Rohrbach’s system gave appear to be based on things one can see in the image at the time, as opposed to common sense knowledge. Rohrbach said that both types of information are used and the explanation tries to be relevant in context. Although the systems do not get external common sense, the machines pick up patterns from training data. The ultimate goal is for the system to be relevant to the image/video instead of only providing a plausible common sense explanation. Although additional external knowledge has not yet been injected, that could be an interesting future direction.
Rohrbach then turned to a discussion of diagnosing and correcting bias in captioning models. Explanations could be useful to expose and measure bias in systems. She said that useful priors are necessary for learning (i.e., all machine learning methods learn by exploiting correlations and patterns present in training data). Failures can occur if the task domain changes or if the domain remains the same but the data distribution changes. This sometimes leads to incorrect or even offensive predictions. She described how captioning models exaggerate imbalances in training data and amplify bias—for example, an image of a woman can be labeled as a man, owing to the presence of a desk and a computer in the scene. In this case, the system captured biases and spurious correlations. One goal of Rohrbach’s work is to improve gender bias in deep captioning models. The prediction of gender in captions needs to be based on appropriate evidence. In order to make an accurate gender prediction using a standard cross entropy loss for image captioning, the captioning pipeline is retained while additional losses are introduced to correct the problem of gender misclassification. The results are categorized by error rate (i.e., misclassification of women as men and vice versa), gender ratio (i.e., women/men in predicted captions), and being right for the right reasons (i.e., the model is looking at the people in the image). The Equalizer model reduces the distance to the gender ratio (i.e., the difference between the ratio of man to woman predicted and the ratio in ground truth captions) and error rate (i.e., percent of gendered words predicted incorrectly) and is right for the right reasons more often than the baselines. If evidence is weak and gender is uncertain, the label “person” will be used in the prediction.
A workshop participant suggested that such biases are a property of the data set, and any combination of properties would likely have this same flaw. Rohrbach said that in the case of gender, there are societal implications pertaining to fairness. Here, the goal is to avoid the amplification of biases, to avoid spurious correlations that lead to errors, and to be fairer to the actual data set distribution. Another audience participant asked if randomness could be injected into the process to make the neural network more powerful. Rohrbach said that vision and language each carry responsibility for these kinds of errors and that it is difficult to uncover where the error originates. One will always have to deal with multimodality, so it is difficult to determine whether that would be a solution. She said that there is a way for the process to propagate priors or biases in non-obvious ways: people have tried rebalancing the training data, but Rohrbach does not think this is a scalable and reasonable solution because there are many different biases and correlations, and they cannot all be balanced. An audience participant asked if the labels are more accurate with her approach, and Rohrbach responded that they have become more accurate in terms of gender while maintaining caption quality. In response to a follow-up question as to whether there is an advantage to using this approach over simply rebalancing the data, Rohrbach said that, yes, this approach is advantageous over the baseline because the baseline carries and amplifies all of the training biases and does not adapt to new distributions. A workshop participant asked how the system could dynamically rebalance the bias. Rohrbach reiterated that she trains a single system on the given training data, which has its biases, but evaluates on different test sets. She said that the system adapts well to different test distributions. She explained that the system is now looking at the person rather than relying on context correlations. She emphasized that correcting this behavior alone is an important advance. A workshop
participant said that this goes beyond an issue of bias in a particular data set during training or test and has more to do with training using only one objective (i.e., the overall captioning loss, which combines multiple sources of evidence in the data). The right thing to do would be to see if, for example, an umbrella always corresponds with a woman; that could be a valuable cue. Hoffman added that the goal is to have more modular models that pay attention to different cues and report on each of them independently. She said that it sounds like Rohrbach is introducing an auxiliary loss that allows one to focus on relevant details of what should be used to determine gender. Rohrbach said that while in some cases the correlations are desired and it is acceptable to use them, there could be ramifications from the public about such stereotypes.
Rohrbach provided a very brief overview of change captioning before concluding her presentation. She noted that although data analysts want to use AI, there are obstacles across multiple domains in understanding changes over time. Although not everything that changes would be relevant to an analyst, it is important to recognize semantic changes: semantic change detection and captioning is a way to detect changes between two different images of the same scene taken at different times. The goal is to be able to summarize the change that occurred using the tools from image captioning and other vision or language techniques to discover and explain the change over time. Changes in scenes can be nontrivial to recognize. Qualitative results reveal that one cannot rely on single attention, because if something is no longer present, the system has a difficult time understanding that change and associating the same object in two scenes. So, the approach she described has two attention mechanisms to discover the change and highlight in an explainable manner where the right evidence is located. In summary, the Dual Dynamic Attention Model is used to localize and describe changes between images. She noted that her team’s model is robust to viewpoint changes and its dynamic attention scheme is superior to the baselines.








{kind=link}