
3
Methods for Patient-Centered Outcomes Research
The workshop discussions summarized in this chapter cover methods that could advance patient-centered outcomes research (PCOR) and make PCOR data more useful going forward. The brief overview of the input received from the presenters is followed by the committee’s conclusions. Speakers in this session were asked to focus on the following questions:
- What emerging methods are likely to be most relevant for the PCOR data infrastructure looking forward? What are the most important research and data challenges?
- What computing advances, innovative health information technologies, and methodologies might present opportunities going forward?
- What role can the Office of the Assistant Secretary for Planning and Evaluation (ASPE) play in supporting effective methods for PCOR studies? What characteristics of HHS’s public mission, programs, or authorities could be leveraged?
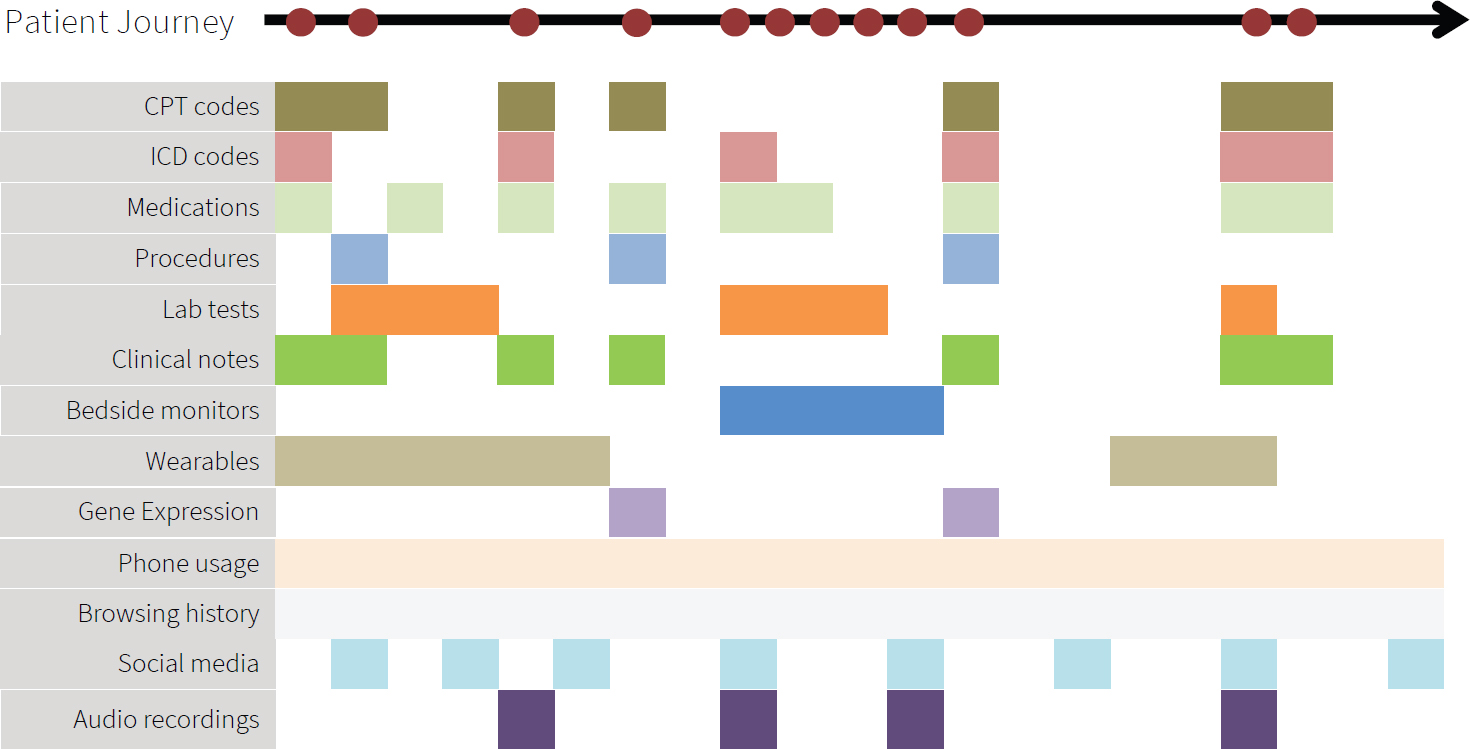
Nigam H. Shah, Stanford University, argued that to make better use of patient-centered outcomes data, it would be useful to adopt a patient timeline view of the data. Typically, data are thought of as residing in tables, text files, images, and so on, but health care happens over time, and it is useful to think of the data in those terms, as events occurring over time.
Figure 3-1 illustrates Shah’s patient timeline perspective. The figure shows a patient’s journey, with the red dots denoting events with some health care relevance. Depending on which access point into medical data
SOURCE: Workshop presentation by Nigam Shah, May 24, 2021.
they use, researchers only get a partial view of the event that really occurred. For example, they might have access to claims filing information corresponding to a medical visit, which might have International Classification of Disease (ICD) codes, medication codes, Common Procedural Terminology (CPT) codes, and laboratory test orders. From the electronic health records, researchers might be able to access test results, the clinician’s notes, and perhaps the signal streams from bedside monitors. Outside of the health system, we might get data from wearables, such as a Fitbit or an Apple watch. In a research setting, we might find gene expression data, genomic data, and perhaps more kinds of molecular measurements. Outside of the context of medical care, researchers might have access to information about online activities, such as phone usage, browsing, social media postings, audio clips, and so on.
Shah said that artificial intelligence (AI) or machine learning may make it easier to automate the processing of the types of data included in the timeline view. A more innovative use of AI is to combine multiple data modalities to trigger some proactive action.
Shah pointed out that few data source systems in routine use have native constructs for handling a task such as, for example, finding patients with a history of myocardial infarction who have pneumonia. This query has to be programmed in SQL (Structured Query Language) programming language, which is currently the dominant mechanism for interacting with this type of data. To be able to make full use of timeline data, it is also necessary to have tools that can perform interval algebra. The next step after performing interval algebra would be navigating knowledge graphs.
For example, one might want to find patients with disorders of glucose metabolism or patients with disorders of glucose metabolism treated with certain types of medications. The challenge is that current data systems do not handle medical knowledge graphs, and manual coding is necessary.
Shah also discussed the need to be able to state phenotype definitions, in other words, the necessary and sufficient conditions for believing that a particular event of interest occurred. As an example, hypertension as a phenotype might imply a different blood pressure cutoff, depending on the decade. “Ventilator days” was another example, mentioned in the workshop in connection with the COVID-19 pandemic. Shah noted that the complexity of phenotype definitions ranges from the collection of codes to elaborate Word documents that need to be translated into SQL.
Shah summarized his points as the need for technology that allows researchers to go from timelines to data frames in real time, taking timeline objects (with their as-yet unsolved storage challenges) and performing advanced analytics, satisfying the necessary and sufficient statements to conclude that a particular exposure outcome happened, and producing an analysis data frame in real time. He argued that solving these challenges would greatly accelerate PCOR.
Shah also discussed the Advanced Cohort Engine (ACE), a search engine he and his colleagues developed for patient data.1 The search engine consists of a persistent in-memory database of patient objects and a temporal query language, both optimized for fast search, and a flexible application programming interface to access and retrieve data. Researchers can quickly find patients by searching across diagnosis and procedure codes, concepts extracted from clinical notes, laboratory test results, or vital signs, as well as by visit types and duration of inpatient stays. They can then compare the outcomes of these patients. Shah mentioned that the search engine is available with the Observational Medical Outcomes Partnership Common Data Model (OMOP CDM) version 5.3 and higher, emphasizing the importance of adhering to at least one community standard so that going from data to analyses is reproducible, reliable, and scalable.
Shah underscored the need to upgrade the collective computational infrastructure in the United States to be able to conduct the types of analyses he described in real time. There is also a need for a stronger focus on systems and software, beyond methods development.
Sharon-Lise Normand, Harvard University, highlighted data silos as one of the main challenges for PCOR data and PCOR in general. There are a large number of data sources, the usability and availability of unique IDs
___________________
1 A. Callahan, V. Polony, J.D. Posada, J.M. Banda, S. Gombar, and N.H. Shah. (2021). ACE: The Advanced Cohort Engine for searching longitudinal patient records. Journal of the American Medical Informatics Association. https://doi.org/10.1093/jamia/ocab027.
are questionable, and linkages across databases are difficult to accomplish. She agreed with Shah that understanding what works requires longitudinal observation of patients over time.
Normand pointed at missing data as another challenge for PCOR. While missing data has always posed difficulties for statisticians, it is important to understand what this means specifically for electronic health records and to consider solutions for irregularly spaced data. She also noted the added challenges of missing data when more than one source is linked, when dealing with large volumes of data, and when using machine learning approaches.
The large number of data sets and new tools for processing the data also bring new challenges in terms of uncertainty over the precision of the estimates. One issue is selective inference, and the numerous decisions required as part of the analysis, because this ends up making the findings difficult to reproduce. Normand noted that currently no good methods exist for dealing with the propagation of differing errors associated with the use of multiple, complicated data sets. She argued that it is necessary to have an honest reflection concerning uncertainty and that there is a need for transparency regarding the assumptions and decisions that are made as part of the analyses.
Normand also discussed several areas where methodological opportunities exist for PCOR. The first such area is clinical trials. The availability of large volumes of electronic data will make it possible to streamline approaches for adaptive trials, which are difficult to conduct. Developing parallel randomized and prospective observational studies, using the same database and the same cohort receiving treatment at the same time, can also increase ability to learn about how effective certain treatments are. Finally, the usefulness of the data could be improved if adjustments were developed for reporting non-blinded outcomes, such as when participants are asked to complete a questionnaire.
The second area where opportunities exist for advancing PCOR is causal inference and the adoption of experimental thinking. Normand encouraged more emphasis on designing studies, as opposed to simply focusing on the analysis. Integrating causal inference approaches would be particularly useful in pragmatic trials. Opportunities exist to better understand the implications of missing data in sparse data settings and to better understand uncertainty and error propagation for the estimates.
Finally, Normand argued that exploiting the connectedness of information that is available from observational settings represents another methodological opportunity. She described this as a longitudinal multitask approach, sharing information across devices and across patients.
Addressing what ASPE could focus on, Normand said that the new Bridge2AI funding opportunity announcement from the National Institutes
of Health (NIH) made her think that it would be useful to have “on demand” data, for example data that are already linked. Building a trial infrastructure for randomized and observational studies would be helpful. She also argued that to be able to make valid inferences about patient-centered outcomes data, it is necessary to invest in statistical methodology.
Sherri Rose, Stanford University, began by talking about data transformations in cases where it might be necessary to intervene if the information available represents structural biases in the collection of those data. Rose mentioned a recent paper she coauthored with colleagues on the ethical use of machine learning in health care.2 The paper discusses the potential for data tools to exacerbate existing health disparities, along the different steps in the process from problem selection, through data collection and outcome definitions, and finally to algorithm development and potential postdeployment activities. She said that the preprocessing steps are where data transformations would typically be considered, but a lot of the work can also happen in the algorithm-building stage, or in the post-processing stage, where one might decide, for example, to adjust thresholds to handle concerns about the data. Rose said that questions to ask include Who decides the research questions? Who is the target population? and, What do the data reflect?
Rose discussed her prior work on using data transformation to bring causal conceptual thinking to the matter of fairness in data infrastructure.3 The work focused on payment systems, aiming to reduce disparities in low-income neighborhoods and underprovision of services for chronic conditions, and the idea was to develop a methodology to set policies at desired levels. Rose added that thinking about how to do these types of data transformations is challenging, but this methodology is underleveraged and could benefit data infrastructure.
In the context of data linking and causality, Rose discussed a collaboration she had undertaken with Normand, in which they linked claims, registry, and vital statistics data to study the comparative effectiveness of cardiac stents.4 Using machine learning made it possible to identify heterogeneous effects for the safety outcome in a cohort of patients receiving percutaneous coronary interventions. One piece of information they did not have was a
___________________
2 I.Y. Chen, E. Pierson, S. Rose, S. Joshi, K. Ferryman, and M. Ghassemi. (2021). Ethical machine learning in healthcare. Annual Review of Biomedical Data Science, 4(1), 123–144. https://www.annualreviews.org/doi/abs/10.1146/annurev-biodatasci-092820-114757.
3 S.L. Bergquist, T.J. Layton, T.G. McGuire, and S. Rose. (2019). Data transformations to improve the performance of health plan payment methods. Journal of Health Economics, 66, 195–207. https://doi.org/10.1016/j.jhealeco.2019.05.005.
4 R.S. and S.-L. Normand. (2018). Double robust estimation for multiple unordered treatments and clustered observations: Evaluating drug-eluting coronary artery stents. Biometrics, 75, 289–296. https://doi.org/10.1111/biom.12927.
reliable estimate of the operator’s skill, so they controlled for the operator in that study. She said that technology now exists to film operators doing surgery and produce an estimate of operator skill based on the footage to augment existing data. This technology might not scale well to large data sets, but it is an area with a lot of potential.
Generalizability was another topic touched on by Rose. While generalizability is typically considered in the context of inference, she argued that it is also useful to think of generalizability in prediction and clustering. The literature on generalizability from disparate data sources is spread across a variety of fields, including computer science, statistics, and health sciences. She mentioned a review she completed with one of her students and noted that there is substantial work yet to be done in this area.5
In some of their current work, Rose and her colleagues are focusing on integrating randomized and observational data, where each data source contains individuals who were missed by the other source with respect to the covariate distribution. In this work, they are focused on the area of overlap between randomized and observational data to develop new estimators and leverage the probability of selection into the randomized trial and the probability of receiving the treatment or receiving the intervention.
Rose echoed some of the conclusions highlighted by other speakers regarding opportunities to enhance PCOR. This includes the need to support work on developing new databases and software as well as maintaining existing software. She emphasized as well the importance of supporting the development of creative new methods for building data infrastructure. In closing, she urged researchers to consider whether their algorithms have a social impact statement. In connection with building tools for a data infrastructure, she named several social impact principles, including responsibility, explainability, accuracy, auditability, and fairness.
Nirosha Mahendraratnam Lederer, of Aetion, said that the company’s Aetion Evidence Platform puts real-world data on a patient timeline, and uses transparent and scientifically validated workflows to analyze the data to generate real-world evidence. All the company’s designs and analysis considerations are maintained in an audit trail.
Concerning real-world data, Lederer said that many variables of interest are available from traditional sources, such as medical and pharmacy claims, hospital chargemasters, electronic medical records, and clinical laboratory results. Additionally, newer digital tools, such as mobile health apps, sensors, and wearables enable the collection of additional patient-generated data. Linking traditional and newer digital sources makes it possible to generate a fuller picture of a patient, including the different factors
___________________
5 I. Degtiar and S. Rose. (2021). A Review of Generalizability and Transportability. https://arxiv.org/pdf/2102.11904.pdf.
that ultimately impact the person’s well-being, beyond physical health and traditional clinical outcomes. This enables researchers to study questions that patients really care about and provide information that can address issues with health care delivery, as well as structural and societal challenges.
Lederer suggested that the key for successfully using real-world data for research is to start with a well-defined research question that can be studied in the real world, and to ensure that a data source suitable for answering the question is available. However, the right data are not always available. For example, data that would allow researchers to study health disparities are rarely usable. Lederer said that there are two main reasons for challenges of this type.
The first reason why the available real-world data do not always include all the necessary data elements is that they are typically collected for purposes such as claims for billing, and not targeted for research purposes. As a result, these data sets are often missing key variables necessary to generate high-quality evidence. Lederer suggested that identifying a minimum set of core data elements to collect in routine clinical care can enable more meaningful research and facilitate data linkages. She added that building on existing tools and initiatives instead of creating new programs might be most practical. For example, instead of creating bespoke sets of required minimum data elements, perhaps the Office of the National Coordinator for Health Information Technology could collaborate with the research community to augment the United States Core Data for Interoperability (USCDI) to include essential data elements for research. Lederer acknowledged that USCDI applies only to electronic health records, and suggested that perhaps voluntary community standards could work for other types of data. To encourage adoption, it would be important to engage with digital health companies and organizations such as the Digital Medicine Society, because high-quality standardized data entry can make a big difference in the suitability of data for research.
The second reason why real-world data sometimes do not include data elements necessary for research is that privacy laws or commercial interests may be restricting the accessibility of these data, even when the data elements are captured. Lederer said that in an effort to protect privacy, frequently the tradeoffs are between information on race, geographical granularity, and place of service. All three of these data elements are essential for addressing issues with health care quality and disparities. Given technological advances, and the way data are collected, used, and linked today, Lederer said that it is important to revisit these policies in the context of research.
Another challenge highlighted by Lederer is that often only researchers within a health care system have access to certain data, and external researchers do not. This brings up the issue of parity, and the benefits that
would result from more researchers with different perspectives and ideas having the opportunity to test their hypotheses using these restricted data sets.
Lederer also highlighted challenges associated with carrying out analysis using real-world data, even when the data are available. She pointed out that not all real-world data translate to high-quality evidence. However, there are some clear principles for generating high-quality evidence that is patient-centered and suitable for decision making. This includes starting with the concept of designing the target randomized controlled trial that one would conduct to answer the research question, and then emulating that trial through an observational study.
Over the longer term, Lederer said that she supports making research an infrastructure investment for state-of-the-art data curation and analytics such as AI or advanced methods to aim to quantify and adjust time-varying unobservables. However, in the more immediate term, it would be useful to think about how to refine the operationalization of valid research. Lederer suggested organizing, evaluating, and incentivizing the use of PCOR and real-world evidence tools to promote the generation of decision-grade real-world evidence. She added that this could essentially be a real-world PCOR toolbox. While many of the tools that would need to be included in such a toolbox are available today, many researchers do not know that they exist or how to find them. Making a toolbox readily available could also result in the development of a framework for conducting real-world PCOR.
Lederer noted that the development of new tools is also necessary. For example, raw data need to be transformed into variables that can be analyzed. For federal data sets that are available for public use, this could involve creating standardized, validated measures and measure sets to help operationalize and augment the use of the data. It would also be useful to create disease-specific tools, which could include master protocols for real-world evidence that centralize the relevant expertise needed for high-priority research questions. One potential model that could be leveraged is the Reagan-Udall Foundation for the U.S. Food and Drug Administration (FDA) in collaboration with Friends of Cancer Research’s COVID-19 Evidence Accelerator, which convenes health care stakeholders to use a common data shell and protocol to run analyses for high-priority research questions for COVID-19.
The creation of a toolbox would not be easy, Lederer acknowledged. Part of the process would be reviewing all of the available resources, triaging them, harmonizing them, and identifying how they can be used for regulatory decision making, clinical decision making, policy decision making, or personal decision making.
Lederer also emphasized the importance of transparency for building credibility to advance the science of real-world PCOR. This includes data
transparency, protocol transparency (e.g., preregistering studies to address potential concerns over hacking and data dredging), and publishing the results regardless of the outcome.
Lederer argued that science should not be proprietary. She highlighted the benefits of a culture where inferential protocols are made publicly available, not only in the interest of reproducibility and replicability, but also because otherwise one might not have access to the full scope of expertise necessary to conduct a high-quality study. She said that transparency could be accelerated through incentives, such as tying access to federal data sets or federal funding to the registration of the studies and the publication of the research protocols and results.
Lara Mangravite, Sage Bionetworks, focused on the governance component of the data infrastructure, discussing issues related to the governance structures used to enable research that typically involves data from multiple sources. She briefly described the governance structure of the National Center for Advancing Translational Sciences (NCATS) National COVID Cohort Collaborative (N3C), which assembled medical records from approximately 65 medical centers from across the country into one central repository with the purpose of using it for research.
Mangravite noted that, typically, one of the important roles within governance structures is that of a data steward. The data steward is responsible for the technology that allows the data to be managed and used and for the legal agreements between the data donors and the data users. The N3C effort, Mangravite said, illustrated the challenge of integrating data across systems. She argued that data interoperability between health systems and data linkage across sources requires increased investment in data quality standards.
Mangravite also discussed the evaluation of care, which in her view often requires integrating data on lived experience beyond the data captured in the medical system. Person-centered research necessitates data that comes directly from the patient, in part because clinical care is impacted by a variety of factors not captured in the medical record. She noted, however, that obtaining data on individuals’ lived experiences increasingly involves private and sensitive information, and that it is important to consider the value proposition from the perspective of the individual providing the data. Sage Bionetworks works with a lot of sensor data, and Mangravite pointed out that a person’s characteristics impact what researchers see, for example, in the accelerometry data from someone walking down the street. This has implications for how the data are analyzed, but also how the data are managed and what the privacy considerations and value proposition are.
Mangravite said that most discussions of data sharing involve researchers acting as data stewards and exchanging data. These discussions typically do not involve the individuals whose data are shared. The expectation is
that these individuals would simply need to trust the data governance to happen in their interests. This might not be an acceptable situation, given that for many types of data the risks and benefits are not well understood. Mangravite argued that approaches to data governance need to change; they need to go beyond simply making the informed consent processes more dynamic and involving the people being represented in the data in the practice of the research itself, throughout the lifecycle of the studies. This is especially important because the implications of the use of the data are not always clear at the stage when the data are collected. Involving the individuals providing the data in the study would at a minimum ensure transparency about how the data are being used, and ideally would also allow room to impact decisions related to the data use.
One of Sage Bionetwork’s current projects, called the MindKind Study, aims to identify self-management strategies that might work for youth with anxiety or depression. Mangravite said that to observe youths’ mental health states in combination with self-management strategies or other activities they may be engaging in, and to do that dynamically over time, requires a lot of data that are not found in medical records. She and her colleagues are examining whether integrating youth into the data governance and stewardship model impacts their willingness to participate. They asked youth and researchers in several countries a series of questions related to data governance (e.g., their preferences related to who can access the data, who controls the data, what kind of research can be conducted with the data, and so on). They found agreement between the youth and researchers on responses to many of the questions, including, for example, on who can access the data. However, perspectives differed on some questions, such as, for example, on who control the data. Mangravite said that they are now conducting a study that aims to better understand differences between what is preferred and what is acceptable, and looks at how potential changes based on what they learned would impact willingness to participate.
In summary, Mangravite highlighted the need for integration of data across systems, and the integration of participants into the research lifecycle, as two of the areas that need the most attention in terms of the data infrastructure. To integrate participants, her specific suggestions were to focus on enabling richer understanding of lived experiences outside of the medical system, support the alignment of research questions with community needs, and support capacity building for translating research outcomes into action.
DISCUSSION
As with the previous session, the formal presentations on PCOR methods were followed by additional discussion among the participants.
One topic that was explored in further detail and emerged as a key theme was the need for a more holistic “timeline” view of people’s experiences. The main challenges associated with developing longitudinal data sets are the costs and barriers associated with following and identifying people over time and with linking information from different sources. The fragmentation of the health care system and the lack of unique identifiers were reoccurring themes in the discussion of barriers. The limited availability of timestamps associated with the data that are available was also highlighted.
A theme that had been explored in detail in the committee’s first workshop and was revisited by the participants in this one was the need to broaden research perspectives from the patient to the person in a broader sense, bringing in additional data on factors that are outside of the health care provider system. Integrating relevant data that go beyond provider databases represents its own challenges, but a timeline view that expands beyond a person’s experiences within the health care system would greatly increase our ability to understand, for example, chronic diseases.
The topic of data privacy was also discussed, including concerns about the unknowns in the area of potential re-identification. The discussion echoed points made by the speakers in the previous two sessions, highlighting tensions related to different perspectives on whether fully de-identified data is a realistic goal, and whether access to identified data with strong security and penalties for misuse would be an option. This topic, and the committee’s conclusions, are addressed further in Chapter 4.
Another theme that emerged during the discussion was the importance of engaging patients in the research process and being transparent about the methods used to generate findings. Participants also discussed the need to balance the goals of transparency with the interests of stakeholders who would like to keep some of the information proprietary, and there are efforts under way to develop approaches that achieve this balance. However, widespread adoption would be more likely if there were incentives and a central repository in place.
CONCLUSIONS
One theme that emerged from the session on methods for PCOR was the potential usefulness of adopting a timeline or longitudinal perspective on understanding a person’s journey through the health care system, and through life events that have a relevance to health more broadly. Several changes could facilitate this shift, as summarized in Conclusion 3-1.
CONCLUSION 3-1: The ability to adopt a longitudinal, comprehensive perspective on an individual’s journey could open new opportunities for
patient-centered outcomes research. The shift could be facilitated by focusing on efforts to
- simplify the integration of data across the research data ecosystem;
- address challenges posed by the limitations associated with health identifiers;
- incorporate person-generated data into health data systems; and
- leverage real-world data to expand the timeline view of a person’s health-related experiences.
Speakers emphasized the need for transparency and for consideration of related scientific principles, such as reproducibility of the data and methods used for PCOR. These considerations are important for all types of data and analysis, but the increasing use of tools such as machine learning and natural language processing raises the question of whether best practices can ensure that these tools do not have negative social impacts.
CONCLUSION 3-2: Observing scientific best practices, including those of transparency and ethical use of data, is essential to generate trust in patient-centered outcomes research among all stakeholders, including the public and researchers. This is important both for observational data and for emerging data sources and methods.
The session on methods highlighted the importance of interpreting best practices around the dissemination of the research broadly. That is, best practices apply not only to the sharing of results but also to other resources and components associated with the research process, such as the software developed for analyses. Sharing all these resources ensures that the data can be widely used and that the research can be replicated. Ultimately the goal of patient-centered outcomes research is to benefit people, so the question of what happens to the research after it is done, and the sharing of the information with those whose data are being used, also deserves further attention.
CONCLUSION 3-3: The results of patient-centered outcomes research (and research in general) are only replicable and are most useful when the underlying data and comprehensive research documentation (such as analytic code) are made available for use by others.












