
10
HSI Processes and Measures of Human-AI Team Collaboration and Performance
Human-systems integration (HSI) addresses human considerations within the system design and implementation process, with the aim of maximizing total system performance and minimizing total ownership costs (Boehm-Davis, Durso, and Lee, 2015). HSI incorporates human-centered analyses, models, and evaluations throughout the system lifecycle, starting from early operational concepts through research, design-and-development, and continuing through operations (NRC, 2007). HSI policies and procedures applicable to defense-acquisition programs have been published (DODI 5000.02T, Enclosure 7 [DOD, 2020]), and HSI standards have been adopted by the DOD (SAE International, 2019). Further the Human Factors Ergonomic Society/American National Standards Institute (HFES/ANSI) 400 standard on human readiness levels was developed, which codifies the level of maturity of a system relative to HSI activities, ranging from human readiness level 1 (lowest) to 9 (highest) (Human Factors and Ergonomics Society, 2021). In this chapter, the committee examines the state-of-the-art, gaps, and research needs associated with design and evaluation processes for human-AI teams, and discusses the need for incorporating HSI considerations into development of AI systems in addition to the specific design and training issues discussed in previous chapters.
TAKING AN HSI PERSPECTIVE IN HUMAN-AI TEAM DESIGN AND IMPLEMENTATION
The committee notes that, to date, HSI methods have had limited application to the design of human-AI teams. This is largely attributable to the fact that AI systems are currently being developed primarily in a research-and-development context and for non-military applications, in which HSI methods are not commonly applied. While HSI methods are applied outside of the military, AI systems are currently being developed in areas where HSI is not common practice (e.g., automobiles, consumer apps). However, lessons learned during the design of earlier AI systems make clear the importance of taking an HSI approach, to avoid developing AI systems that fail to meet user and mission requirements, resulting in lack of system adoption or extensive need for workarounds when the systems are fielded (NRC, 2007).
The need to consider the context of use throughout the design and evaluation process is an area of consensus in HSI practice (Air Force Scientific Advisory Board, 2004; Boehm-Davis, Durso, and Lee, 2015; Evenson, Muller, and Roth, 2008; NRC, 2007; SAE International, 2019). Context of use includes characteristics of the users, the activities they perform, how the work is distributed across people and machine agents, the range and complexity of situations that can arise, and the broader sociotechnical “environment in which the system will be integrated” (NRC, 2007, p. 136). Context of use is best determined via field observations and interviews with
domain practitioners (e.g., cognitive task analysis methods) to understand the pragmatics of the work context in which the human-AI team will operate (Bisantz and Roth, 2008; Crandall, Klein, and Hoffman, 2006; Endsley and Jones, 2012; Vicente, 1999).
The pitfalls of failing to take the context of use into account continue to be relearned by developers of AI systems. A recent example is a deep-learning system developed for detection of diabetic retinopathy (Beede et al., 2020). While the system achieved levels of accuracy comparable to human specialists when tested under controlled conditions, it proved unusable when implemented in actual clinics in Thailand. Beede and colleagues (2020) identified multiple socioenvironmental factors preventing the system’s effective performance that were only uncovered in the field. They noted that there is currently no requirement for AI systems to be evaluated in real-world contexts, nor is it a customary practice. They advocated for human-centered field research to be conducted prior to and alongside more formal technical performance evaluations.
As a positive contrast, Singer et al. (2021) examined development of successful machine learning (ML)based clinical support systems for healthcare settings. They reported much more active engagement in the field of practice, with back-and-forth between developers and end-users shaping the ultimately successful AI systems. The committee highlights the importance of grounding AI system designs in a deep understanding of the context of use, and the need for continual engagement with users throughout the development and fielding process, to understand the impact of user engagement on practice.
Another point of emphasis in HSI is the need for analysis, design, and testing to ensure resilient performance of the human-AI team in the face of off-normal situations that may be beyond the boundary conditions of the AI system (Woods, 2015; Woods and Hollnagel, 2006). Resilience refers to the capacity of a group of people and/or automated agents to respond to change and disruption in a flexible and innovative manner, to achieve successful outcomes. Unexpected, off-normal conditions are variously referred to as black swans (Wickens, 2009) and dark debt (Woods, 2017), as well as edge, corner, or boundary cases (Allspaw, 2016). These events tend to be rare and often involve subtle, unanticipated system interactions that make them challenging to anticipate ahead of time (Woods, 2017). Allspaw (2012) argued for the need to continuously search for and identify ways to mitigate these anomalies, starting in development and continuing into operation. Neville, Rosso, and Pires (2021) are developing a framework (called Transform with Resilience during Upgrades to Socio-Technical Systems) that characterizes the sociotechnical system properties that enable human-AI teams to anticipate, adapt, and respond to situations that may be at or beyond the edge of the AI system’s competency envelope. The Neville, Rosso, and Pires framework is being used to derive tools and metrics for evaluating system resilience and guiding technology transition processes. Gorman et al. (2019) have similarly developed a method of measuring the dynamics of the human and machine components of a system before, during, and after a perturbation in a simulated setting, to understand the system interdependencies and possible unintended consequences of unanticipated events. In the committee’s judgment, these are promising directions, but more research is needed to develop and validate effective methods for design and evaluation of resilient human-AI teaming.
Key Challenges and Research Gaps
The committee finds three key gaps related to HSI for human-AI teams.
- Currently, the development of AI systems often does not follow HSI best practices.
- Context-of-use analyses to inform design and evaluation of AI systems are not commonly practiced.
- There is limited research and guidance to support analysis, design, and evaluation of human-AI teams to ensure resilient performance under challenging conditions at the boundaries of an AI system’s capabilities.
Research Needs
The committee recommends addressing the following research objective for improved HSI practice relevant to human-AI teaming.
Research Objective 10-1: Human-AI Team Design and Testing Methods.
There is a need to develop and evaluate design/engineering methods for effective human-AI teaming. There is a need to develop and test methods for analysis, design, and evaluation of human-AI team performance under conditions that are at or beyond the competence boundary of the AI system(s).
REQUIREMENTS FOR RESEARCH IN HUMAN-AI TEAM DEVELOPMENT
The development of high-quality system requirements includes specifying high-level goals and functions for a desired system, and typically includes assigning responsibilities to various agents (human or computer-based) to complete these goals (MITRE, 2014). Ideally, requirements should be understandable, succinct, unambiguous, comprehensive, and complete (Turk, 2006). When a cognitive systems engineering approach is used to augment the development of requirements, such requirements will address information needs that explicitly consider human decisions and cognitive work, for individuals, human-human teams, and possibly human-AI teams (Elm et al., 2008).
The committee finds that the rise of AI has introduced new problems currently not addressed by either traditional or cognitive systems-engineering approaches. Although there is a substantial body of literature addressing how requirements should and could be developed for military systems, the bulk of this work assumes that the underlying decision-support systems rely upon deterministic algorithms that perform the same way for every use. Thus, in earlier research, while the underlying algorithms may not always exhibit high performance, they exhibit consistent performance (Turban and Frenzel, 1992), and so it is relatively straightforward to determine whether information requirements are met and under what conditions.
In the committee’s opinion, the increasing use of connectionist or ML-based AI in safety-critical systems, like those in military settings, has brought into sharp contrast the inability of traditional systems-engineering and cognitive systems-engineering approaches to address how development of requirements needs to adapt. A major current limitation of ML-based AI systems is that their use could affect cognitive work and role allocation, and may create the need for new functionalities due to use of systems that reason in ways that are unknown to their designers (Knight, 2017).
Another major problem with ML-based AI is its inability to cope with uncertainty. AI powered by neural networks can work well in very narrow applications, but the algorithms of an autonomous system can struggle to make sense of data that is even slightly different in presentation from the data on which it was originally trained (Cummings, 2021). Such brittleness means humans may need to adjust their cognitive work and unexpectedly take on new functions due to limitations in the underlying AI. In addition, much recent work has revealed how vulnerable ML-based AI systems are to adversarial attacks (Eykholt et al., 2017; Su, Vargas, and Sakurai, 2019). So, in addition to managing AI systems that are inherently brittle, humans may also be burdened with monitoring such systems for signs of potential adversarial attacks.
Key Challenges and Research Gaps
The committee finds that an improved ability to determine requirements for human-AI teams, particular those that involve ML-based AI, is needed.
Research Needs
The committee recommends addressing the following research objective for improved HSI requirements relevant to human-AI teaming.
Research Objective 10-2: Human-AI Team Requirements.
A number of requirements for AI system development will likely change in the presence of machine learning-based AI. Research is needed to address several overarching issues. When and where should machine learning-based AI be used as opposed to symbolic in systems that support human work? What new functions and tasks are likely to be introduced as a result of incorporating brittle AI into human-AI teams? What is the influence of time pressure on decision making for systems that leverage
different kinds of AI? How could or should acceptable levels of uncertainty be characterized in the requirements process, especially as these levels of uncertainty relate to human decision making? How can competency boundaries of both humans and AI systems be mapped so that degraded and potentially dangerous phases of operational systems can be avoided?
RESEARCH TEAM COMPETENCIES
To address the gap in understanding how AI systems could and should influence requirements and the design of systems that support human work, particularly in settings that are high in uncertainty, the committee finds that a new approach is needed for the formation of research teams to tackle such problems. There is a research gap that misses interconnections between fields of focus, partially because scientists and researchers often work in “silos” but also due to a lack of formal interdisciplinary programs that train people to be proficient in more than one field. To address these issues, the committee believes that research teams looking at basic and applied problems in human-AI team development will need to be multi-disciplinary to address the myriad of problems that overlap separate fields.
The exact makeup of any specific research team will depend on the nature of the research question(s), as Figure 10-1 illustrates for human-AI team development. The committee finds that there are four clusters of desired research competencies: (1) computer science; (2) human factors engineering; (3) sociotechnical science; and (4) systems engineering.
In the committee’s opinion, these competencies represent the broad areas needed to support numerous human-AI team research scenarios. Computer science is at the core because any system that incorporates any kind of AI will necessarily have computer scientists (or related disciplines) as the creators of the underlying technology. The importance of computer scientists teaming with other researchers, like those in human factors, systems engineering, and sociotechnical aspects, cannot be overstated. Such multi-disciplinary teams promote an understanding of the broader impacts of the technology and help to make it functional and successful in real-world applications (Dignum, 2019). Table 10-1 illustrates representative topics within each of the research thrusts that the committee finds may be needed to support human-AI teaming research projects; it is likely that even a single project would benefit from collaboration between individuals in multiple blocks of the table.
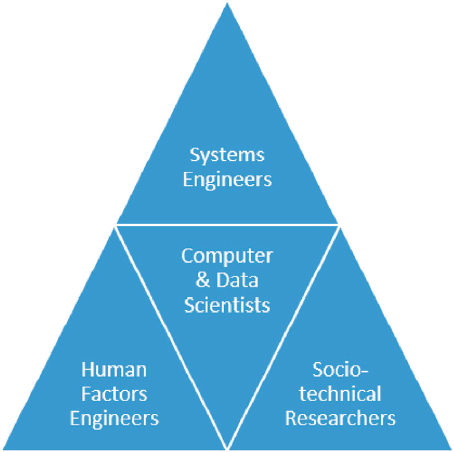
TABLE 10-1 Representative Multi-Disciplinary Team Competency Topics

Key Challenges and Research Gaps
The committee finds that, to develop AI systems with competent human-AI teaming, a new approach to the formation of research teams is needed, which incorporates competencies and approaches from multiple disciplines.
Research Needs
The committee recommends addressing the following research objective for improved human-AI team development.
Research Objective 10-3: Human-AI Team Development Teams.
New multidisciplinary teams and approaches to the development of human-AI teams need to be created. A systems perspective is needed to create successful human-AI teams that will be effective in future multidisciplinary operations, and this will require synergistic work across multiple disciplines that cannot be achieved through a siloed approach. Exploration and evaluation of mechanisms for achieving successful team collaboration in human-AI development teams are needed.
HSI CONSIDERATIONS FOR HUMAN-AI TEAMS
Biased or brittle AI creates a significant challenge for certification efforts. Understanding these biases and limitations is critical for framing the developmental, operational, and support requirements any program must address (MITRE, 2014). Within the DOD, HSI is divided into a number of domains: manpower, personnel, training, human factors engineering, safety and occupational health, force protection and survivability. These encompass a number of important developmental objectives and requirements that have traditionally been called ilities.
Relevant to AI systems, three overarching ilities are paramount (Simpkiss, 2009):
- Usability: “[Usability] means ‘cradle-to-grave’ including operations, support, sustainment, training, and disposal. This includes survivability” (Simpkiss, 2009, p. 4).
- Operational suitability: “Includes utility, lethality, operability, interoperability, dependability, survivability” (Simpkiss, 2009, p. 4).
- Sustainability: Includes supportability, serviceability, reliability, availability, maintainability, accessibility, dependability, interoperability, interchangeability, and survivability.
Other important ilities include functionality, reliability, supportability, and flexibility among others (de Weck et al., 2011). In addition to these important considerations, there are also new ilities to consider for human-AI teams. Table 10-2 outlines both how traditional ilities will need to be adapted for human-AI teams and new ilities that need to be considered. In addition to traditional usability concerns that are well-known to the HSI community, there will need to be added focus on making the limits of AI transparent to users. As noted previously, though there has been a recent increase in research on explainability and interpretability for AI (see Chapter 5), a large part of this research focuses on explainability and interpretability for the developers of AI, with far less focus on the users of AI in practical settings. This is of particular concern to the USAF because time pressure is an attribute of many operational environments and, given the propensity for biased decision making in such settings (Cummings, 2004), in the committee’s judgment it is especially important that AI systems be truly usable and transparent.
TABLE 10-2 HSI Considerations for Human-AI Teams: Traditional and New Ilities
| Ility | Needs |
|---|---|
| Traditional | |
| Usability |
|
| Operational Suitability |
|
| Sustainability |
|
| New | |
| Auditability |
|
| Passive Vulnerability |
|
In the operational suitability category, the biggest need is to address the notion of concept drift, also known as model drift. Concept drift occurs when the relationship between input and output data changes over time (Widmer and Kubat, 1996), making the predictions of such systems irrelevant at best, and potentially dangerous at worst. In the DOD, an embedded AI system that relies on an older training set of data as it attempts to analyze images to find targets in a new and different region will likely experience concept drift. Thus, concept drift is a possible source of dynamic uncertainty that needs to be considered when determining whether an analysis in one setting may adapt well to a different setting. The committee finds that the DOD does not currently have a system in place to ensure the periodical evaluation of AI systems to ensure drift has not occurred or to inform the human operator of the level of applicability of an AI system to current problem sets (see Chapter 8).
The notion of concept drift also affects the sustainability category, given that the best way to prevent such drift is to ensure the underlying data are adequately represented in any AI model. The USAF clearly recognizes that sustainability, reliability, serviceability, and maintainability are key considerations (Simpkiss, 2009), but it is not clear that the USAF has mapped out the workforce changes needed to adequately address these concerns for AI systems. In the committee’s judgment, as there are for aircraft, there will need to be an AI maintenance workforce whose jobs entail database curation, continual model accuracy and applicability assessment, model retraining thresholds, and coordination with testing personnel. In the committee’s judgment, the USAF should create an AI maintenance workforce, which, if done correctly, could be the model for both other military branches and commercial entities.
In addition to the changes needed in terms of the more traditional ilities, the committee finds that there is also a need to explicitly consider auditability, which is the need to document and assess the data and models used in developing an AI system, to reveal possible biases and concept drift. Although there have been recent efforts in developing processes to better contextualize the appropriateness of datasets (Gebru et al., 2018) and model performance with a given dataset (Mitchell et al., 2019), there are no known organized efforts for military applications. In the committee’s opinion, military AI systems could require a level of auditability that far exceeds commercial systems, due to their use on the battlefield. Auditability could fall under the purview of an AI maintenance workforce, as mentioned above.
The last new ility category that will likely need to be expressly considered by the USAF for AI systems is that of passive vulnerability. There is increasing evidence that ML-based AI systems trained on large datasets can be especially vulnerable to forms of passive hacking, in which the environment is modified in small ways to leverage vulnerabilities in the underlying deep-learning algorithms. For example, adversarial ML techniques can deceive face recognition algorithms using relatively benign glasses (Sharif et al., 2016), and recently a Tesla was tricked into going 85 mph versus 35 mph using a small amount of tape on a sign (O’Neill, 2020). Such scenarios, though predominantly occurring in the civilian domain, have clear relevance for military operations, and occur not only in computer vision applications of AI but also in natural language processing (Morris et al., 2020). Such results indicate that, to combat this new source of vulnerability, the USAF will need to continue to develop new cybersecurity capabilities that will require reskilling of the workforce and advanced training.
Key Challenges and Research Gaps
The committee finds that the requirements for the development of trained workforces and methods for detecting problems and testing AI systems need to be determined.
Research Needs
The committee recommends addressing the following two research objectives to develop an understanding of workforce needs to support future human-AI teams.
Research Objective 10-4: AI System Lifecycle Testing and Auditability.
The required workforce skillsets, tools, methodologies, and policies for AI maintenance teams need to be determined. There is also a need to find methods for AI system life-cycle testing and auditing to determine the validity and suitability of the AI system for current use conditions. Determining the enabling processes, technologies, and systems that need to be incorporated into fielded AI systems to support the work of AI maintenance teams is necessary.
Research Objective 10-5: AI Cyber Vulnerabilities.
The necessary workforce skillsets, tools, methodologies, and policies need to be determined for detecting and ameliorating AI cyber vulnerabilities and for detecting and responding to cyber attacks on human-AI teams.
TESTING, EVALUATION, VERIFICATION, AND VALIDATION OF HUMAN-AI TEAMS
Because of the nascent nature of embedded AI in safety-critical systems, testing, evaluation, validation, and verification (TEVV) has been recognized as a potential Achilles’ heel for the DOD (Flournoy, Haines, and Chefitz, 2020; Topcu et al., 2020). A recent report highlighted the significant organizational issues surrounding TEVV for defense systems and spelled out the policies and actions that the DOD is advised to implement in the near- and far-term to address current inadequacies (Flournoy, Haines, and Chefitz, 2020). While this effort outlined the many high-level issues associated with AI TEVV, this section will detail more nuanced areas of TEVV inquiry with a focus on needed areas of research. These issues are also relevant to the training of human-AI teams (see Chapter 9), however, the committee emphasizes that training can never be a substitute for proper design and testing of the AI system.
In the committee’s opinion, the primary reason that TEVV for human-AI teams needs significant attention is the problem with how such systems cope with known and unknown uncertainty. There are three primary sources of uncertainty in any human-AI team, as illustrated in Figure 10-2. As is familiar to the HSI community, human behavior for actors both within and external to a system can be widely variable and can carry significant uncertainty. For the military, the environment is also a major contributor to operational uncertainty, often referred to as the fog of war. What is new in human-AI teams is the need to account for the variability, (i.e., blind spots) in the embedded AI, and how those blind spots could lead to problems in human performance during the operation of human-AI teams (Cummings, 2019).
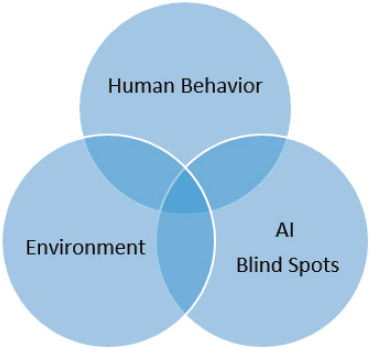
Previous technological interventions (e.g., radar, decision-support tools, etc.) were meant to reduce uncertainty but, with the insertion of AI (particularly ML-based AI), there is now a third axis of uncertainty to be considered: that of AI blind spots. As discussed previously, AI can be brittle and fail in unexpected ways. One recent example is the interpretation of the moon as a stoplight by a Tesla vehicle (Levin, 2021). Although such a mistake seems relatively benign, there have also been several high-profile incidents in which a Tesla crashed broadside into a tractor trailer or hit a barrier head on, killing the drivers; so the combination of significant AI blind spots and human inattention can be deadly (NTSB, 2020).
It is generally recognized that significantly more work is needed in the area of assured autonomy, in which autonomy reliably performs within known and expected limits (Topcu et al., 2020). Assured autonomy requires significant advances in AI testing. In the committee’s judgment, to reach acceptable assurance levels, the DOD needs to adapt its testing practices to address the AI blind-spot issues, but there has been little tangible progress. The DOD’s current approach to testing generally includes developmental tests at the earlier stages of a technology’s development, followed by operational testing as system development matures. The committee finds that, although this approach is reasonable for deterministic systems, it will not be sustainable for systems with embedded AI. The constant updating of software code that is a necessary byproduct of modern software-development methods is a major reason that the DOD needs to adopt new testing practices. Seemingly small changes in software can sometimes lead to unexpected outcomes. Without principled testing, particularly for software that can have a derivative effect on human performance, the stage will be set for potential latent system failures. Moreover, because software is typically updated continuously throughout the lifecycle of a system, it will also be necessary to adapt testing to catch the emergence of a problem in a system with embedded AI. It is not ideal to rely on system users to discover issues during actual operations, and it is particularly problematic in safety-critical operations such as multi-domain operations (MDO). There is a need for user testing prior to issuing each software update, particularly in cases when the update will impact how the user interacts with the system (e.g., changes the information displayed or the behavior of the system).
In addition, users of the system will inevitably discover issues during actual operations, regardless of the testing or development approaches. The question is not whether these surprises will occur, because generally they will. The committee’s goal is to improve DOD testing practices to reduce the occurrence of surprises, by incorporating tests prior to the introduction of any software change. These tests could probe for potential effects of software changes on the ways people must interact with the system. Considerations include assessing (1) how easy it will be for humans (especially users) to anticipate and detect unexpected behavior; and (2) how easy it will be for humans (especially DevOps personnel) to make quick adjustments to the code to mitigate, block, or otherwise make moot the results of the unexpected behavior.
In addition, the committee finds that the DOD’s current staged approach to testing does not explicitly account for the need to test AI blind spots, as illustrated in Figure 10-2 and discussed previously. There is a dearth of research
and knowledge around how the subjective choices of AI designers could lead to AI blind spots, poor human-AI interaction, and, ultimately, system failure (Cummings and Li, 2021a). As a result of the new sources of uncertainty that require rethinking TEVV, particularly in terms of human work, new testbeds will be needed that allow for not only investigation of such uncertainties, but also use by the various research areas outlined in Figure 10-2.
Key Challenges and Research Gaps
The committee finds that methods, processes, and systems for testing, evaluation, verification, and validation of AI systems across their lifespans are needed, particularly with respect to AI blind spots and edge cases, as well as managing the potential for drift over time.
Research Needs
The committee recommends addressing the following research objective to improve testing and verification of human-AI teams.
Research Objective 10-6: Testing of Evolving AI Systems.
Effective methods need to be determined for testing AI systems to determine AI blind spots (i.e., conditions for which the system is not robust). How could or should test cases be developed so that edge and corner cases are identified, particularly where humans could be affected by brittle AI? How can humans certify machine learning-based and probabilistic AI systems in real-world scenarios? Certification includes not just understanding technical capabilities but also understanding how to determine trust for systems that may not always behave in a repeatable fashion. The National Science Foundation recently published an in-depth study on assured autonomy, so there is a potential important collaboration between this organization and the AFRL (Topcu et al., 2020). Given that changes in both software and environmental conditions occur almost continually (due to the potential for concept drift) in AI systems, how to identify, measure, and mitigate concept drift is still very much an open research question. Living labs involving disaster management may form suitable surrogates for research on multi-domain operations human-AI teams.
HUMAN AI-TEAM RESEARCH TESTBEDS
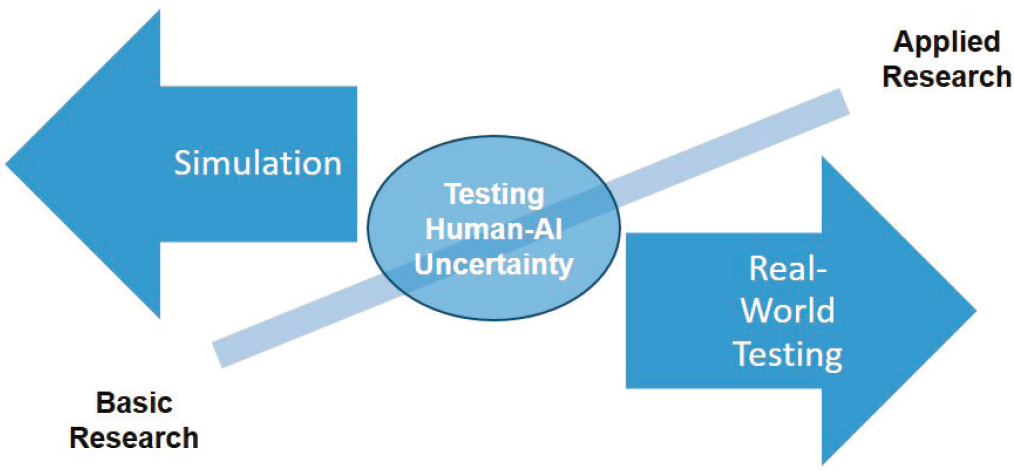
To address the numerous complexities inherent in human-AI research, the committee finds that there needs to be substantially improved testbed availability, above and beyond what the USAF currently has. One of the core issues at the heart of human-AI experimentation is the role of simulation versus real-world testing (Davis and Marcus, 2016). As seen in Figure 10-3, simulation is generally thought to be the appropriate testbed for basic research, while a shift toward real-world testing (or approximations of such) is needed for more applied research. While these principles are also valid for human-AI research, there is a clear need to consider the role of uncertainty, as previously outlined.
Because uncertainty is a potential “unknown unknown” that can come from the design of AI systems, the environment, humans, and the interplay of these factors (Figure 10-2), the committee believes that much greater emphasis is needed on studying this effect in human-AI research. To that end, Figure 10-3 illustrates that, while some human-AI testing can occur in simulations, testbeds that cannot incorporate elements of real-world uncertainty will necessarily miss a critical element of research.
Regardless of whether the testbeds are in simulations or with real-world elements, they need to be designed to support the multi-disciplinary efforts outlined in Figure 10-1. This means it would likely be beneficial for testbeds to support different kinds of users (e.g., researchers who code as well as researchers studying people). The committee believes that, ideally, testbeds would be modular so that, for example, different datasets, algorithms, or decision-support systems could be substituted as needed, without requiring major system overhauls. In addition, given the realistic constraints of a post-Covid-19 world, testbeds would ideally be usable both in person, for those researchers who need physical access to the testbed, and remotely.
Key Challenges and Research Gaps
The committee finds that testbeds for human-AI teaming are needed that can support relevant interdisciplinary research, challenging scenarios, and both pre- and post-deployment testing needs.
Research Needs
The committee recommends addressing the following research objective for developing testbeds to support human-AI teaming research-and-development activities.
Research Objective 10-7: Human-AI Team Testbeds.
Given the changes that AI is bringing and will continue to bring to both the design of systems and their uses, flexible testbeds for evaluating human-AI teams are needed. It would be advantageous to use these testbeds to examine relevant research questions included throughout this report. The testbeds need to allow for multi-disciplinary interactions and inquiry and include enough real-world data to allow for investigation on the role of uncertainty as it relates to AI blind spots and drift. It would also be useful for testbeds to accommodate the need for routine post-deployment testing, including person-in-the-loop evaluations, anytime meaningful software changes (which need to be defined) are made, or whenever environmental conditions change, which could lead to latent problems.
HUMAN-AI TEAM MEASURES AND METRICS
The establishment of appropriate evaluation measures and metrics is an important element in evaluating human-AI teams (see Chapter 2). Measures typically refer to the measurement scale used for evaluation, and metrics typically refer to the threshold levels on the measurement scale that serve as reference points for evaluation judgments (Hoffman et al., 2018). Multiple types of measures are relevant for evaluating human-AI teams, including individual cognitive process measures, teamwork measures, and outcome performance measures. Although some measures are highly mature, others are just emerging and in need of further study.
Cognitive process measures such as workload and situation awareness have been extensively studied and validated in the context of human-automation interaction (e.g., Endsley and Kaber, 1999) and continue to be relevant
for evaluating the cognitive impact of human-AI teaming on human team members (Chen et al., 2018; Mercado et al., 2016) (for reviews of situation awareness and workload measures, see Endsley, 2020b, 2021a; Kramer, 2020; Young et al., 2015; Zhang et al., 2020.)
Because AI systems exhibit complex behavior and, in some cases, provide explanations for their performance, new measures are being developed that are particularly applicable to human-AI teaming. One of the most prominent new measures relates to trust in the AI system. A variety of rating-scale measures of trust have been developed that vary in the number and type of items included, as well as the rating scale used (see Hoffman et al., 2018 for a review of representative measures of trust).
There is growing interest in measuring people’s mental models of AI systems to assess their understanding of those systems. There have been a variety of approaches developed to assess mental models of AI systems, including think-aloud protocols, question answering/structured interviews, self-explanation tasks, and prediction tasks that ask people to predict what an AI system will do in various situations (see Hoffman et al., 2018 for a review of representative measures). With the recent emphasis on generating AI systems that are explainable, interest has also emerged in developing measures of explainability. Hoffman et al. (2018) present a questionnaire that can be used to measure people’s assessment of explanation satisfaction, which is defined as the degree to which they feel they understand the AI system or process being explained. Sanneman and Shah (2020) propose a measure of explanation quality that is based on the situation awareness global assessment technique (Endsley, 1995a).
Measures of teamwork processes that have been used in all-human teams have been adapted for measuring teamwork in human-AI teams. These teamwork processes include communication, coordination, team situation assessment, team trust, and team resilience. Though scales exist for self-assessment of team process or observer-assessment of team process (Entin and Entin, 2001), there is a growing trend toward measuring teamwork in an unobtrusive manner, in real or near-real time (Cooke and Gorman, 2009; Gorman, Cooke, and Winner, 2006; Huang et al., 2020). These measures rely heavily on communication data, which is readily available from most teams. However, communication flow patterns are used more than communication content. McNeese et al. (2018) found that the communication patterns displayed by the AI system were less proactive than those of human teammates and, over time, the human-AI team’s coordination suffered, as even the humans became less proactive in their communication. Physiological measures of teamwork such as neural synchrony have also been used (Stevens, Galloway, and Lamb, 2014); however, these present a challenge in terms of identifying the sensor that is the AI counterpart. Though a challenge, the prospect of collecting sensor data from an AI system that is akin to human physiological signals is, in the committee’s judgment, more promising than measuring AI teamwork through survey data.
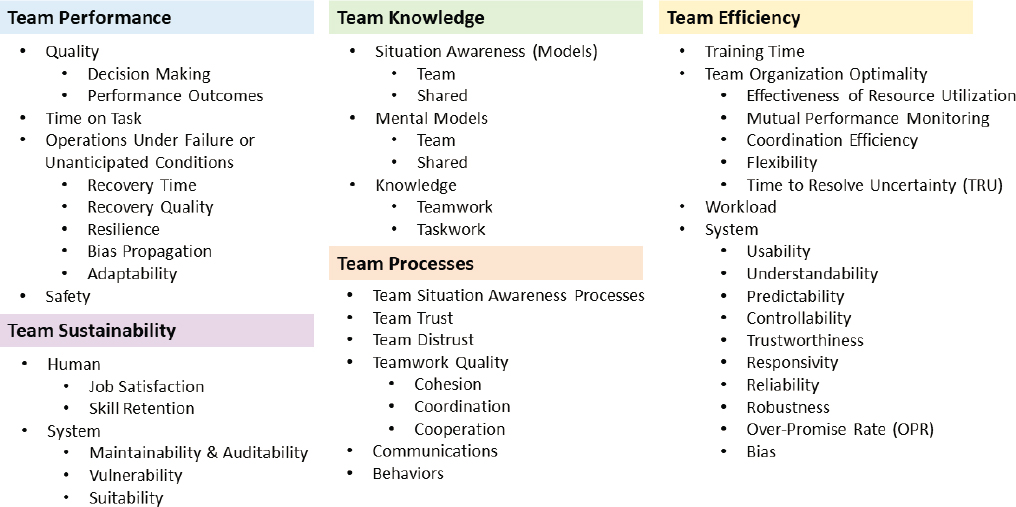
Another important set of measures for evaluating human-AI teams relates to the objective performance of the human-AI team on specific tasks. Traditionally, outcome measures have included quality of performance and completion time. It is possible that human-AI team performance may be objectively worse than the performance of the human(s) working without AI support (e.g., Layton, Smith, and McCoy, 1994; see Chapter 8 for additional discussion). It is possible that human-AI team performance may be objectively worse than the performance of the human(s) working without AI support (see Chapter 8). Figure 10-4 shows pertinent measures for evaluating human-AI teams, including overall team performance, team knowledge structures, team processes, team efficiency measures, and team sustainability considerations.
The ability of the human-AI team to perform effectively in unanticipated conditions at or beyond the boundaries of the AI system is an important concern in measuring human-AI team outcome performance. This is often measured in terms of out-of-the-loop recovery time (Endsley, 2017; Onnasch et al., 2014). There are also ongoing efforts to develop methods for measuring resilience (Hoffman and Hancock, 2017; Neville, Rosso, and Pires, 2021). More research is needed to provide practical measures and metrics that can be used to assess human-AI team resilience as part of performance-evaluation efforts.
Key Challenges and Research Gaps
The committee finds four key gaps related to metrics for human-AI teaming.
- Although emerging measures of trust, mental models, and explanation quality are important additions for evaluation of people’s understanding and level of trust in AI systems, there is a growing proliferation of alternative methods for measuring each of these constructs. The reliability and validity of these alternative methods need to be determined.
- The impact of AI systems to bias human performance, resulting in negative impacts, is an important concern. Practical methods for assessing such biases are needed.
- Although there are ongoing efforts to develop measures of the resilience of the human-AI team, these efforts remain in the early stages and more research is needed.
- In real-time measurement of human-AI teams, there is a need to understand the best source of signals from the AI agent, and to be able to interpret human-AI interaction patterns in terms of team state.
Research Needs
The committee recommends addressing the following research objective for improved metrics relevant to human-AI teaming.
Research Objective 10-8: Additional Metrics for Human-AI Teaming.
There is a need for more research to establish the reliability and validity of alternative methods for measuring trust, mental models, and explanation quality. Ideally, the research community would converge on a common set of methods for measuring these parameters, to facilitate comparison of results across studies. This research also needs to develop (1) methods to measure the potential bias that AI agents can have on human decision-making processes and overall quality of performance; and (2) methods to measure human-AI team resilience in the face of unanticipated conditions that require adaptation.
AGILE SOFTWARE DEVELOPMENT AND HSI
Agile software processes first emerged more than 20 years ago, with the goal of developing quality software more rapidly, to increase responsiveness to dynamically changing user needs (Dybå and Dingsøyr, 2008). Typically, agile software-development processes occur through multiple short sprints (each on the order of weeks), with the idea of delivering usable software early, followed by the delivery of incremental improvements generated through subsequent sprints. More recently, the trend toward agile software has been extended into software-development operations (DevOps) for more seamless, continuous delivery of quality software (Allspaw and Hammond, 2009; Ebert et al., 2016). DevOps represents a new paradigm with associated tools and processes intended to tighten the loop between software development and operations. The goal is to shorten the cycle time for delivery of software and upgrades as well as enable software to be easily changed during operations (not just prior to deployment).
Agile software-development processes and DevOps have been widely embraced by industry and more recently by government and DOD operations (Sebok, Walters, and Plott, 2017). DOD Instruction 5000.02 lays out policies and procedures for implementing an adaptive acquisition framework to improve acquisition process effectiveness (DOD, 2020). It specifically calls for the use of agile software development, security operations, and lean practices to facilitate rapid and iterative delivery of software capability to the warfighter.
Adopting agile software approaches has many important benefits. Particularly, it results in more rapid delivery to users than has been possible with traditional waterfall-engineering and acquisition approaches. Equally important, the agile software approach allows the software-development process to be more responsive to changing user needs (or changing understanding of user needs). Unlike traditional approaches, requirements need not be fully defined at the start of the program but can emerge while working in collaboration with the user community. These are important attributes of effective software development that were explicitly called for in the National Research Council Human-System Integration in the System Development Process: A New Look report (2007) on HSI. Further, agile development approaches make auditability of the software easier.
The committee finds that, although agile approaches to software development have clear benefits, there are also significant challenges that will be particularly relevant to the development of AI systems that can work effectively as teammates with humans. There is growing recognition that the focus on delivering software quickly can incur technical debt. Technical debt refers to design or implementation choices that may be expedient in the short term but may make future changes more costly or impossible (Boodraj, 2020; Kruchten, 2016). A literature review examining causes and consequences of technical debt in agile software development found that, for architecture and design issues, “a lack of understanding of the system being built (requirements), and inadequate test coverage” were among the most cited causes of technical debt (Behutiye et al., 2017, p. 154). The committee acknowledges that technical debt can arise with any software-development approach, including waterfall methods. Our point in raising a concern with respect to technical debt in the case of agile software relates to the specific types of technical debt documented in the literature—most particularly lack of understanding of system requirements and inadequate test coverage. These are precisely the concerns that were expressed in presentations to the committee.
Similar conclusions were drawn from a review of agile development processes used for safety and mission-critical applications (Sebok, Walters, and Plott, 2017). Among the challenges identified in the use of agile methods was the limited opportunity to develop a consistent, coherent vision for the overall system. These researchers recommended including a “sprint 0” that involved more extensive analysis of the demands of the work domain and the needs of the user, as well as development of an integrated design concept to provide a larger, coherent structure to inform later sprints. They also emphasized the need for more holistic verification and validation processes of the larger system, as well as more comprehensive documentation.
These findings highlight that, if not conducted in a thoughtful manner, agile software processes may limit the ability to produce coherent, innovative software solutions that depend on a comprehensive understanding of mission and performance requirements. By emphasizing rapid sprints without the benefit of a big-picture understanding of the larger problem space, there is a real risk of missing important mission requirements or opportunities to dramatically improve performance. The potential to miss mission-critical requirements is a particular concern in MDO, in which there are myriad sources, complexity, constraints, and objectives to be satisfied, and where the evolving concept of operation can result in system deficiencies. The committee acknowledges that completely bug-free and
surprise-free software is an unattainable goal, and that missing requirements and failing to anticipate all edge-cases can occur with any software-development approach, not just agile. Our point is the need to develop more effective and efficient approaches for capturing critical system requirements early in the development process. The objective is to impose some upfront, high-level analyses to reduce the chance, of missing important requirements early in the design process that may be much harder, and more expensive, to accommodate later in the design process. This is particularly important in complex systems such as MDO, in which there are many roles, each with interrelated functionality and information needs.
In recognition of these concerns, the Human Readiness Level Scale in the System Development Process (HFES/ANSI 400-2021 standard) has developed guidance for more effectively incorporating HSI approaches into the agile development process that are highly relevant to AI and MDO (Human Factors and Ergonomics Society, 2021). These include the following:
- Agile software should only be applied when “human capabilities and limitations are known and design guidelines for software system are established” (p. 28).
- While, in agile processes, user requirements are typically determined during each sprint for small portions of the system, for complex and safety-critical systems (such as military operations), “more upfront analysis of human performance requirements may be needed” (p. 28).
- “Cross-domain and cross-position information sharing requirements may need more extensive upfront analysis of user needs” (p. 28), which certainly applies to MDO command and control.
- “Graphical user interface design standards must be established and applied consistently across software iterations and design teams, enabled by human factors engineering and user experience style guides” (p. 28). This is especially important for multiple-position operations, such as in MDO command and control.
- Objective and comprehensive testing is required, involving human factors in the development teams, and considering both normal and off-normal events.
The committee recognizes that the HFES/ANSI recommendations represent an ideal that is not always completely achievable. For example, while it is important to strive for objective and comprehensive testing, we recognize that there are no known methods that guarantee complete test coverage or guarantee that all problems will be caught. Nevertheless, this report highlights areas in which more attention is needed to insure that HSI concerns are adequately addressed within an agile development process.
Key Challenges and Research Gaps
The committee finds that best-practice HSI methods are currently not incorporated into the agile development process. This can lead to a failure to systematically gather user performance requirements, develop coherent innovative solutions that support human performance, and conduct comprehensive evaluations to ensure effective performance across a range of normal and off-normal conditions.
Research Needs
The committee recommends following research objective to address the incorporation of HSI into agile software development, particularly as it relates to human-AI teaming and MDO.
Research Objective 10-9: Human-Systems Integration for Agile Software Development.
There is a need to develop and validate methods for more effectively integrating human-systems integration (HSI) best practices into the agile software-development process. This may include identifying and building upon success stories in which HSI analyses have been successfully inserted into agile processes, as well as developing and testing new approaches for incorporating HSI activities into agile development processes as called for in HFES/ANSI 400. HSI standards, tools, and methodologies need to be explicitly incorporated into agile software-development processes for AI and multi-domain operations.
SUMMARY
The development of AI systems that can work effectively with humans depends on meeting a number of new requirements for successful human-AI interaction. A reliance on good HSI practices is essential, as is improving analyses, metrics, methods, and testing capabilities, to meet new challenges. A focus on testing, evaluation, verification, and validation of AI systems across their lifespans will be needed, along with AI maintenance teams that can take on relevant upkeep and certification processes. Further, HSI will need to be better integrated into agile software-development processes, to make these processes suitable for addressing the complexity and high-consequence nature of military operations. The committee believes that all these suggestions should be applied to the development of AI systems.
The committee also suggests that the AFRL put into place best practices for AI system development based on existing HSI practice guidelines and current research. These include the following:
- Adopting DOD HSI practices in development and evaluation;
- Adopting human readiness levels in evaluating and communicating the maturity of AI systems;
- Conducting human-centered, context-of-use research and evaluations, prior to and alongside more formal technical performance evaluations;
- Including a focus on systems engineering of human-AI teams within the USAF HSI program;
- Establishing an AI maintenance workforce;
- Establishing an AI TEVV capability that can address human use of AI, and that would feed into existing development and operational test efforts;
- Documenting and assessing the data and models used in developing AI systems to reveal possible biases and concept drift;
- Continuing to monitor performance of the human-AI team after implementation and throughout the lifecycle, to identify any bias or concept drift that may emerge from changes to the environment, the human, or the AI system;
- Incorporating and analyzing real-time audit logs of system performance failures throughout the lifecycle of an AI system, to identify and correct performance deficiencies; and
- Assessing the state-of-the-art in agile software-development practices in the DOD and in industry, and developing recommendations for more effective processes for incorporating agile software methods into the DOD HSI and acquisition process.
This page intentionally left blank.
















