
5
Data Linkage and Innovation
This chapter summarizes the presentations and discussions in the workshop sessions on data linkage and innovation. Jennifer Madans chaired the session on data linkage, and Michael Davern chaired the innovation session. Discussion followed each session.
DATA LINKAGE
Challenges to Connecting Data Across Agencies
Beth Virnig is a professor at the University of Minnesota and director of the Research Data Assistance Center (ResDAC) at the University of Minnesota, which is funded by a contract from the Centers for Medicare & Medicaid Services (CMS) to provide assistance to academic, government, and nonprofit researchers interested in using Medicare and Medicaid data for their research. Virnig clarified that she is not speaking for CMS but drawing on her experience using CMS data. She also explained that CMS manages the Medicare program, but works with states to manage the Medicaid programs. Medicaid is a partnership between CMS and the states, and each state is a little different. While CMS distributes Medicaid data, it does not directly collect the data.
One of the advantages of CMS data is its strong enrollment information, Virnig noted; information on everyone enrolled in each program is provided on a monthly basis, which provides a denominator for this population as well as some demographic information, and dates of birth and death. CMS has health claims data that include records—depending
on the file, they are called bills, claims, or encounters—for health services limited to covered benefits. Some patients also have assessment data if they are in skilled nursing facilities, receive home health care visits, or receive inpatient rehab services.
Virnig reminded workshop participants about CMS’s strict policies around linkage: There are a limited number of possible matching variables, and CMS will not release names or exact addresses. CMS conducts the linkage by sending a “finder file” to a contractor, and the CMS contractor returns validated matches. She noted that the contractor will return a validated match if a single match in the CMS file is identified, but if two or more potential matches are equally likely identified, then no data will be provided. Thus, the quality of the matching variables is very important, she stressed.
Virnig said that for linking to Medicare data, the best linking variable is a Social Security number (SSN), which is defined as either the personal SSN or the SSN to justify benefits. A Medicare Beneficiary ID was assigned to all beneficiaries after 2018, because of concerns about fraud and the elderly losing Medicare cards that revealed their SSNs. For matches prior to 2018, there is a Health Insurance Claim number, which is the SSN plus a couple of digits. She reminded researchers that if they are collecting this information over time, the meaning of the information has changed. A link can also be made on a name plus date of birth, but a name can be problematic as a linking variable.
Matching to state Medicaid data is different than Medicare. Virnig explained every state uses its own Medicaid ID that can be problematic to link to. There is no national standard and in some cases, people have IDs in more than one state or multiple Medicaid IDs in the same state. Virnig noted that while an SSN is often a preferred linking variable, not all states collect SSNs and not all states send SSNs to CMS. She said it is also possible, but problematic, to match using name plus date of birth.
Virnig shared examples of alignment of Medicare data with data from several studies to illustrate how Medicare complemented or supported the data collected in a survey. Figure 5-1 shows the Iowa Women’s Health Study, which started in 1987. The red line shows mortality; the black line shows survey respondents; the blue line shows Medicare enrollments, some of whom aged into the program; and the light gray shows people who were both a current respondent and a current Medicare enrollee. According to Virnig, this figure illustrates a more dynamic way of thinking about linkages and the fact that surveys and linkages each work on their own rhythm and it is important to think about how the rhythms fit together.
Virnig noted that one of the challenges of linkages with Medicare data is a left truncation, which is the gap before a person is on Medicare. It is unknown what happened before the person was 65 years old; after age 65,
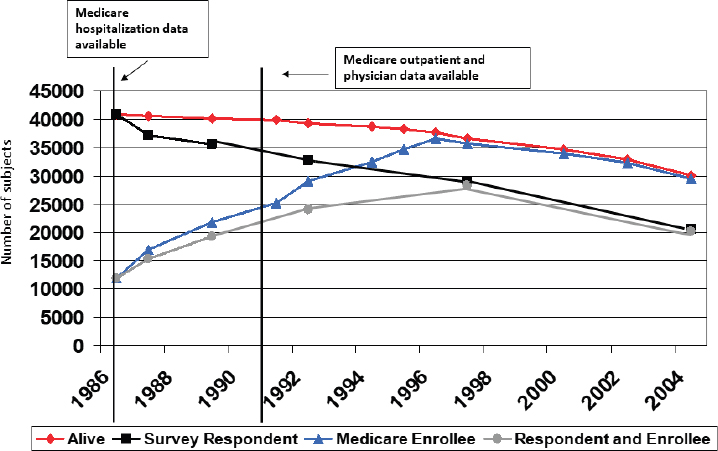
SOURCE: Beth Virnig workshop presentation, September 27, 2021.
their Medicare data are available. She said it is important to keep this in mind when trying to use Medicare data to assess attrition or look at nonresponse, as it may affect different parts of the population over time.
Another challenge with Medicaid data, Virnig said, is interval censoring, which is a mix of observations and gaps when people become enrolled on Medicaid, then may lose their eligibility and disappear. Later, they get their eligibility back, and their data can again be seen. She posited that people who cycle in and out of Medicaid may be of interest, and perhaps many of them are survey nonrespondents.
In addition to left truncation and interval censoring limiting the usefulness of linking to Medicare and Medicaid data, Virnig added that another area that likely needs more investigation is the impact of linking on survey sampling weights.
Virnig highlighted important issues for researchers when using Medicare claims data. These issues include some key variables, including demographic variables; coverage options, which identifies whether the person is enrolled in a managed care plan or has “fee for service”; diagnosis codes, using ICD (International Classification of Diseases)-9 or ICD-10; the dates of service; procedures performed, using ICD-9/ICD-10 or Current Procedural Terminology (CPT)/Healthcare Common Procedural Coding System (HCPCS) codes; types of care received, such as emergency
room services, hospice, or rehabilitation services; and providers and locations of care. The data are collected in real time, and are not subject to recall bias like survey data can be, she pointed out, but there is no correction of past errors such as misdiagnosis. For example, there is no way to go back to January 2020, when COVID-19 diagnosis codes did not exist, to identify deaths that may have been due to COVID-19.
In addition, Virnig pointed out the data record what was done, and not what should have been done or what was intended to be done; as she said, one knows what happened but one does not know what did not happen. She also cautioned about using claims-based measures. For example, the codes for smoking are required to access smoking cessation services but not required otherwise, so they may not be a reliable indicator of smoking behavior. Conditions that are underdiagnosed in clinical settings, such as dementia, will be underrepresented in claims, she added.
Virnig described the need to create variables from the claims data, and noted some advantages and disadvantages. The flexibility provides tremendous opportunity but can be overwhelming. The dates of a survey can be used to sequence the survey with the claims. The claims data can show what was happening around the time that a survey was sent, and may reveal reasons for survey nonresponse. For example, a study that showed a hip fracture occurred around the time of the survey was very strongly associated with nonresponse.
Virnig briefly outlined the structure of different Medicare files, including the percentage of beneficiaries who have records in a given year and the median number of records per beneficiary. The Master Beneficiary Summary File has one record per enrollee per year, but other files are structured to provide one record per hospitalization or per bill, plus additional segments. The structure provides tremendous richness but can be overwhelming to manage, she commented.
To conclude, Virnig noted that payment and reporting policies change, codes change and are updated, and policies vary by state and time. She also pointed to the CMS reuse policy, and said it was particularly important to review for collaborative projects. ResDAC, the center at the University of Minnesota that she directs, can help researchers interested in CMS data.
The NCHS Data Linkage Program: Connecting Data Across Agencies
Lisa Mirel is the chief of the Data Linkage Methodology and Analysis Branch at the National Center for Health Statistics (NCHS), the nation’s principal health statistics agency. In describing the data linkage program at NCHS, Mirel provided four examples of pressing policy questions that require complex and detailed data that NCHS has addressed by combining survey and administrative data:
- Do Social Security Disability Insurance beneficiaries have access to care during the waiting period before Medicare entitlement?
- Are there adverse health effects associated with the mandatory folic acid fortification policy for grain products?
- How effective are health and housing policies in reducing lead exposure?
- How likely are women and children who receive federal assisted housing to participate in the Special Supplemental Nutrition Program for Women, Infants, and Children?
Mirel said that data linkage is a very powerful mechanism that can provide policy-relevant information in an efficient way. She explained NCHS collects survey data to gather information about people’s health status, health behaviors, and health care access. Administrative data are collected for programmatic purposes. NCHS then links data from the surveys with different sources of administrative data to create opportunities to answer key health and policy-relevant questions.
Surveys in NCHS linkage program include the National Health Interview Survey (NHIS), which is a nationally representative cross-sectional household survey that serves as an important source of information on the health of the civilian noninstitutionalized population in the United States; the National Health and Nutrition Examination Survey (NHANES), which is also a nationally representative, cross-sectional sample of the U.S. noninstitutionalized population that combines household-collected interview data with data collected at a mobile examination center; and the National Health Care Survey, which is a family of data collection efforts that gather information about providers, health care services, and patients across the health care spectrum.
Mirel described the key data elements that are collected as part of NCHS surveys, focusing on the household surveys, NHIS, and NHANES. Information is collected on health behaviors, including dietary intake, exercise, consumption of alcohol, and smoking; information on health conditions, based on what a doctor told the respondent in NHIS or actual physical measures in NHANES; socioeconomic information, including education and income; and information about health care access and utilization.
Mirel described some of the key sources of linked administrative data. The addresses of survey participants are geocoded to add in contextual information obtained from standard Census geocoded areas. Person-level data have been linked to data from the Department of Housing and Urban Development to identify survey respondents who are receiving federal-assisted housing, as well as the timing and type of housing assistance. Linkages with CMS data provided information on health care utilization and expenditures for survey participants who are receiving benefits from
CMS. The most utilized linkage is mortality, in which data from survey respondents are linked with the National Death Index (NDI) maintained by NCHS. This linkage can provide longitudinal follow-up for someone who was surveyed earlier to find out whether or not the person has died by the end of the follow-up interval. The NDI also contains information about the cause of death.
Mirel also described upcoming linkages, such as linking to data from the Department of Veterans Affairs (VA), with the hope those data are available for researchers in early 2022. She noted that researchers could use these linked data to answer questions about the health characteristics, health outcomes, and health care utilization for veterans who are using services within and outside the VA health system.
Mirel said that they will also link to the Transformed Medicaid Statistical Information System (T-MSIS) data from CMS, with an expected released in early 2022. She noted that they have previously linked Medicaid data through 2014, and T-MSIS will provide more recent data. Researchers can look at effects of changes in health care policy on the health status of Medicaid recipients.
In the next month, Mirel continued, a file will be released that includes survey participants who linked to end stage renal disease (ESRD) data from the National Institute on Diabetes and Digestive and Kidney Diseases. Although a very small subset of the population, as less than 1 percent have ESRD, it is a very important group because they account for about 7 percent of all Medicare spending. Researchers could use these data along with NHANES to examine the association of dietary intake with diagnosed ESRD.
Mirel said that the linkage program has been spending a lot of time to try to create sources that will support evidence building and make those data available to researchers. Also taking time are documentation and providing support to researchers about the linkage methodology to provide transparency into how these files are created. An assessment of the quality of the linkages is shared so researchers can assess potential linkage errors. NCHS also provides analytic guidelines for researchers on key variables and sample weights. Documentation is included on how these weights could be adjusted given the linkage, and how to interpret the findings based on the sample weights being representative at the time when the survey was conducted.
NCHS releases curated data files that can be used for many different research questions and more than 1,000 publications have been based on NCHS linked data, Mirel said. Each linked data file has a bibliography on the NCHS website. She highlighted the availability of NCHS linked data from NHIS and NHANES and the amount of follow-up longitudinal information: for the NDI, close to 35 years for participants who were in
NHIS in 1986; for NHANES, about 30 years. Mirel showed that for the linkages with Medicare and Medicaid data, there are about 25 years for some survey participants from NHIS and 20 years for NHANES. Similarly for linkages with the HUD data, they have almost 20 years of follow-up for both surveys.
Mirel next focused on challenges and opportunities in linking data. Agreements for data sharing are often one of the biggest challenges. Issues that arise in discussions about linkages with other agencies include who will own the final linked dataset, where the dataset will reside, how the linkage will occur, and where the linkage will occur.
Another challenge is linkage methodology, Mirel said. NCHS collects personally identifiable information (PII) as part of its survey and the administrative record has that information as well, so they usually link based on PII. Some privacy concerns arise about sharing direct identifiers, and her group has looked into privacy-preserving record linkage (PPRL) approaches that would mask the PII and create hash tokens so an exchange of PII to do the linkage would never occur. She said that they have validated the results of the PPRL methods against their standard methodologies and are hoping to use this validation to expand the data sources for linking.
In terms of the quality of linked data, Mirel stressed the quality of the PII reported in the surveys is very important, so they look at some standards and assessment tools when doing the linkage. Machine learning techniques are improving linkage efficiency and external sources can help validate the linkages. In addition, NCHS has examined selection bias for cases that are eligible for linkage in the NHIS and suggested ways to mitigate that bias through adjusting sample weights.
The final challenge that Mirel touched on was accessibility of the linked data files. Because linked data put participants at a greater risk of re-identification, NCHS has been working on creating more publicly available linked data sources using synthetic data and then setting up a validation server so that researchers could validate their results from the synthetic data against the true data. She said that they are hoping to conduct meetings with researchers to identify key variables and create analytically useful datasets. Interactive data visualization tools and other ways to increase accessibility of these linked data for evidence building are also under consideration.
In Mirel’s opinion, successful data linkage rests on three main factors: support and adequate resources from both entities that are going to be involved in the linkage process, consensus on data management responsibilities, and agreement on where researchers can obtain secure access once the files are put together. She concluded by noting some additional uses of linked data, including using information from administrative sources to improve survey operations, such as by improving questionnaire design or
identifying people who had died in advance of data collection for potential follow-up studies.
Discussion
Jennifer Madans, noting that both presenters mentioned challenges as well as opportunities that address the future of data linkage, asked Virnig and Mirel what they think is most important to address now to take full advantage of linkage, both to enhance the availability of data for substantive analysis and to address selection bias.
Mirel replied that agreements for data sharing are one of the biggest obstacles; she suggested using PPRL could open the door to linking to potentially many more sources without needing the direct exchange of PII.
Virnig suggested developing ways to help build teams to work on complex projects involving surveys and administrative data linkages. People typically know only one of the data sources, yet expertise is required for both the survey and the administrative data, which each have their own complexities. John Phillips commented that many longitudinal studies sponsored by the National Institute on Aging (NIA) have long provided linkages to Social Security Administration (SSA) records and to CMS records. Although documentation exists, he acknowledged those data files are not easy for researchers to use and agreed that team building and networks could help facilitate research.
Phillips asked Mirel about the consent process for NHANES with the biological data and administrative linkages: that is, whether it is a general consent or multiple consents for the different linkages and biodata collection. A number of questions for consent are placed at the beginning of the household survey, Mirel replied, including a specific question to ask for consent for linkage when participants are invited to take part in the survey. Madans confirmed that there are multiple consents, very similar to other surveys described, and that consent to one piece does not automatically mean consent to all.
Phillips inquired about the success of the NHANES or NHIS consent process for administrative data. Requirements from SSA for consent has been a challenge for many NIA-supported studies, he said. Mirel responded that her group has spent a lot of time researching those issues, and that for NHIS prior to 2007, consent for linkage was implicit if respondents provided their SSNs, which they were told could be linked to other records. The procedure was changed in 2007, because in the years leading up to 2007, many more respondents refused to provide their SSNs. Based on research, the questionnaire in the NHIS was changed and participants were told about the linkage, the possible sources, and health-related research that could be done, then asked to provide the last four digits of their SSNs.
If respondents refused to provide the last four digits, they were asked for consent to link without an SSN. Prior to 2007, the consent rate for linkage was around 50 percent, whereas now it is in the high 80s, with about half providing the last four digits of their SSN and half consenting to linkage without providing an SSN. She noted that having all nine digits of the SSN makes linkages easier, but having limited PII can still work, although it required changes in the linkage methodology. In response to a follow-up from Phillips, Mirel said the last four digits of an SSN provide reasonably accurate linkages with other identifiers. She pointed to a research paper that looked at linkage eligibility bias for the people in the survey for whom they had all records, assessed what the bias was, and posited how to mitigate it with some adjustment to the sample weights.
Madans shared the difficult experience in negotiating for each administrative data source, noting each agency poses different and sometimes contradictory requirements. She wondered whether implementation of the Evidence Act would create the potential for stronger coordination and could provide a forum to bring together agencies with administrative data to work out agreements with statistical agencies. She also asked about any unintended consequences, and who could lead a coordination effort.
Phillips built on that question. He noted that some of the legal discussions around this issue equated an understanding of the consent process and the risks involved with the provision of a full SSN. He questioned this premise, pointing out SSA warns people not to give out their SSN. The Department of Health and Human Services Data Council might be an arena to have a discussion for standardization of study consent forms, he said.
Related discussions are taking place as part of the implementation of the Evidence Act and the National Secure Data Service, Mirel said, but the focus is on bringing different data sources together to answer specific questions. They have implications for studies that create curated files to address a wide variety of questions, but further discussions will be needed, she observed. Virnig added the Health Insurance Portability and Accountability Act (HIPAA) is another law important for CMS data and that some HIPAA requirements have been an impediment to linking data.
LOOKING AHEAD: APPLYING INNOVATIVE STRATEGIES TO IMPROVE CONSENT AND RESPONSE
Some Reflections on Improving Response and Consent
Annette Jäckle said although the theme of this workshop has been about how to improve consent and response in longitudinal studies of aging, she suggested reframing it around how to reconcile increasing demands for more data with what respondents are willing and able to
provide. Understanding and meeting respondents’ needs and preferences are necessary, she stressed.
Jäckle urged an understanding of what respondents think they have signed up for when they participate in a survey. She hypothesized that when participants agree to take part in an initial interview that is part of a panel study, they have an idea of what they think they have agreed to do. That perception influences what they think is an acceptable request or not and whether or not they will do additional things for the study. She also hypothesized that these perceptions are at least in part influenced by the design of the original survey.
If these hypotheses are true, Jäckle continued, then it is important to think about how to design the study for these additional tasks, including the survey, the consent question, and the incentives. The goal would be to design surveys to increase acceptability of additional requests that conform with what respondents think they signed up for so they agree to do the additional tasks.
Jäckle described results from methodological studies over the past years that point to these hypotheses, although research studies to explicitly test them have not yet been designed.
The first study was from the Innovation Panel of Understanding Society, a sample of 1,500 households in Great Britain in which all household members aged 16 and over are interviewed once a year (see Chapter 4). Part of the sample is allocated to computer assisted personal interview first and to web first; in both modes, there is a follow-up of nonrespondents in the other mode. Respondents were asked to download an app to record their spending every day for one month. They included an experiment on how respondents were invited to the app, with half the sample invited during the annual interview and half sent a letter several weeks after their interview.
Jäckle said that they saw no differences for the web respondents in the proportion who participate in this mobile app study regardless of how they were invited. Her interpretation is that people who do the survey by web see themselves as participating in a self-completion study, and the app is just one more item for completion; it is consistent with what they think they have signed up to do. Although participation was low (16 percent), how they were asked made no difference. The results were very different in face-to-face interviews. Only 9 percent responded to the mailed invitation, but 29 percent of respondents who received the invitation during the interview downloaded the app and provided spending data. She observed if the request was in the interview, it was seen as part of what they have agreed to do, whereas the mailed request was seen as something extra and different from what they think they agreed to do.
In a second study, also using the Innovation Panel, respondents were asked to download an app and use it every day for 14 days to
answer questions about their experiences that day and their well-being. In this study, everyone was invited during their annual interview, but the researchers experimentally varied where in the interview the invitation occurred: half the sample got the invitation to the app relatively early in the questionnaire and the other half at the end. She reported a big difference: 33 percent of the respondents asked at the end of the interview agreed to download the app and logged in, but 44 percent of those asked earlier in the interview did so.
A COVID-19 study was conducted on the main sample of Understanding Society, Jäckle continued. Starting in April 2020, the study sent additional questionnaires about respondents’ experiences during the pandemic (initially monthly, then every 2 months). In March 2021 they asked people for consent to link their survey data to health records, and they experimentally varied where in the survey respondents were asked for consent. Similar results were seen as the previous study: asking early in the survey yielded higher consent rates (76 percent) than asking at the end (68 percent). Among the people who were asked late and did not consent, 54 percent said it is because it was “Too personal, I’ve shared enough information with this survey.” For those who were asked early, a smaller proportion (50 percent) gave that reason. Jäckle noted the consistent pattern of findings across different types of tasks suggest that if asked early in a survey, people are more willing to do additional things than if asked late. Although this may be fatigue, it may be that they feel they have already done enough.
Jäckle’s last example was an experiment on incentives from the COVID-19 study. This study asked respondents for permission to send them a serology testing kit to check for COVID-19 antibodies, which they completed and returned. She focused on results comparing participants who received either £2 to complete the survey plus £5 if they returned the serology sample to those who received £7 pounds for the survey, with no bonus for returning the serology sample. Jäckle said that in the group that received £2 for the survey plus £5 for returning serology, 52 percent of respondents returned the test kit compared to 48 percent of those who were just promised £7 if they completed the survey. However, she noted that when they looked at the issued sample, they did not see any difference between the two because the response rate was higher in the £7 group. Higher participation occurred in the survey when they offered £7 than when they offered £2 plus £5.
To Jäckle, the question is what to place value on and how to communicate that value to respondents, whether the survey that includes the additional tasks or the individual tasks. She shared she has been reflecting on how the response to additional requests might be influenced by the design of the study in which the additional requests are made (Figure 5-2). Starting in the top left-hand corner of the figure, she directed workshop participants’
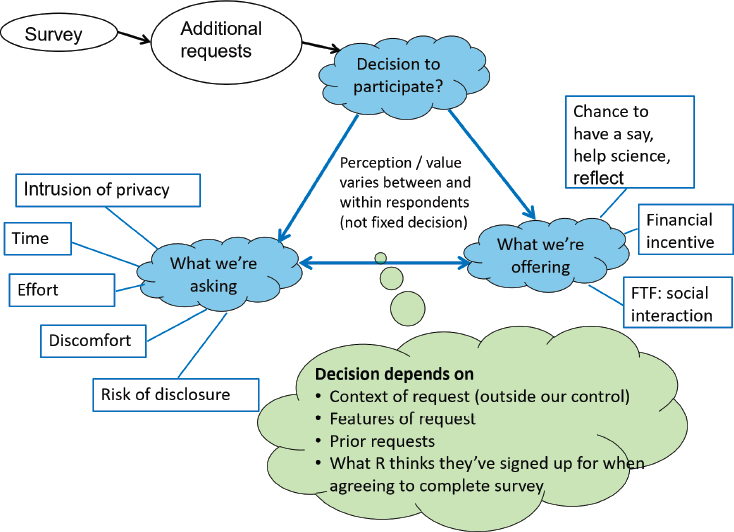
SOURCE: Annette Jäckle workshop presentation, September 28, 2021.
attention to the survey questionnaire, then the additional requests made, such as for biosamples, additional measurements, and additional questionnaires. The respondent then has to decide whether or not to participate for each additional request.
Jäckle noted respondents are being asked for their time, their effort, and acceptance of some intrusion of privacy. Sometimes they must agree to accept some discomfort or do something that might trigger a fear (for example, if it involves needles), as well as accept a risk of disclosure, even if small. They are being offered a chance to have a say, help science, and receive a financial incentive. A face-to-face survey also offers a social interaction. She noted that each respondent will place a different value on each aspect, and people are willing to tolerate different amounts of burden and discomfort.
Jäckle noted that the decision whether or not to participate in these additional tasks depends on contextual factors outside of researchers’ control and influence. However, the features of the request itself, such as wording of the request and the incentives provided, have an impact on consent for additional tasks. In addition, the tasks that respondents have already done
and their perceptions of whether the additional request is consistent with what they think they have signed up to do also influence their decision.
Jäckle concluded that the goal is to design surveys in such a way that people find additional requests acceptable. The next steps are to think the process through theoretically; talk to respondents, including both people who consent and do not consent to additional requests; feed the comments into a theoretical framework; develop hypotheses; and test them experimentally.
From Consent to Linkage: New Data Infrastructure Payoffs
Timothy Smeeding is the Lee Rainwater Distinguished Professor of Public Affairs and Economics at the School of Public Affairs at the University of Wisconsin-Madison. In recent years, Smeeding has worked with CNSTAT and the National Academies committee members to develop the American Opportunity Study (AOS), which was the focus of his talk.1
Smeeding began by highlighting the payoffs from new data infrastructure and the issues of consent and linking to these resources. Smeeding said the AOS is quickly becoming a reality. He said that one of the biggest keys to linkage is Title 13 of the United States Code, which is the statute authorizing the Census Bureau and all of its work. The law prohibits disclosing or publishing private information that identifies individuals, or businesses, including names, addresses, SSNs, and telephone numbers. After 72 years. the data are released from Title 13 protection, and data from the 1850 to 1940 Censuses can and have been linked. He described how people use these 10-year panels for genealogy purposes. He shared a link to the Census Linking Project, which offers researchers information to create longitudinal datasets using historical Census data back from 90 years.2 He noted that the 1950 Census reaches 72 years in 2022, at which time those data will be released publicly. More recent data and linkages are currently available only inside the Federal Statistical Research Data Centers (FSRDCs). Specifically, he said, data from the 2000 and 2010 Censuses are linked, and the linking for the data from the 1960 to 1990 Censuses is in progress.
A group of researchers have explored the historical linked data to examine the effects of the Civil War on intergenerational mortality and other topics, Smeeding said. He cited an article by Abramitzky et al. (2021) in the Journal of Economic Literature on automated linking of historical data, which looked at several different ways to do this linkage that provide 90 to 95 percent certainty of match. He called this an extraordinary opportunity
___________________
1 For more information on the AOS development, see Grusky, Smeeding, and Snipp (2015), and Grusky, Hout, Smeeding, and Snipp (2019).
to create large, longitudinal datasets by linking individuals from one Census to another or from other sources like a survey through the Census Linking Project. A number of research papers are using these data, such as a paper on intergenerational mobility by race using data going back to 1850 (Ward, 2021).
Smeeding provided additional background and context about linking more recent Census data. The AOS was initiated in 2009 by Smeeding, David Grusky, Matt Snipp, and Mike Hout, with inspiration and funding connections from Bob Hauser, Sean Reardon, David Johnson, and Rob Mare. The goal of AOS is to take a current sample of people and look at their mobility over time, with data on their occupation, industry, income, and living arrangements. He noted that the way researchers have examined intergenerational mobility to date is to find people who were born in the 1950s, 1960s, and 1970s, and then wait until they are 45 or 50 and compare them with their parents. The Panel Study of Income Dynamics (PSID) and National Longitudinal Surveys (NLS) are examples. The AOS provides an alternative by starting in the present and looking back in time. The key is linking the 1960 through the 1990 Censuses, which are handwritten, and translating and digitizing them, Smeeding explained.
This would also open the chance to trace immigrant mobility of current cohorts by determining when their parents first emerged in the decennial Census, he continued. Every longitudinal survey begins with a given population, hence people first surveyed in the 1960s (PSID) or 1970s (NLS) form the core, and anyone who migrates to the United States after this start can only enter the survey by marriage or cohabitation with an original survey respondent.
The AOS standing committee at the National Academies conducted a study with Johnathan Fisher and others that found that records could be digitized with 93 percent accuracy. Raj Chetty helped raise money for this work, and the Decennial Census Digitization and Linkage (DCDL) project is under way.3
In summary, Smeeding explained that at an early meeting of a standing NAS committee on the AOS, David Johnson, who was chief of the Social, Economic and Housing Statistics Division in 2008, created a slide to show the possibilities of a Survey of Income and Program Participation gold standard file that could be linked to the decennial censuses and the American Community Survey (ACS), as well as tax data from the SSA and the Internal Revenue Service (IRS).4 Because there is a parent-child link of
___________________
3 See https://www.census.gov/library/working-papers/2019/econ/adep-wp-dc-digitizationlinkage.html.
4 For Smeeding’s full set of slides on this topic, see https://www.nationalacademies.org/event/09-27-2021/improving-consent-and-response-in-longitudinal-studies-of-aging-a-workshop.
SSNs through the IRS and since all children have had SSNs since 1987, all of these data can be linked inside an FSRDC and be protected. This opened up the possibility of linking the 1990 Census and earlier data and kick-started plans for the AOS.
Smeeding showed a summary slide of the current status of the AOS (Figure 5-3), which has three layers: Census data, administrative data, and potential linkages to different surveys. The Census data from 2000 and ACS data from 2008–2012 and 2013–2018 have already been linked. What is missing is in the red box of Figure 5-3: the 1960 to 1990 Censuses short and long forms. Some key variables, including income, education, occupation, work status, and family composition, are only available on the long form, which was administered to one in every six households. However, even the short form gives location, family, and occupation of parents.
In the second layer, Smeeding noted possible linkages to SSA earnings records, as well as program data from the Supplemental Nutrition Assistance Program, the Unemployment Insurance program, the Temporary Assistance for Needy Families program, Social Security programs, and Veterans’ benefit programs. The IRS 1040 data from 1995 to 2012 are also available to link. Smeeding noted that the potential exists for linking with surveys of aging. He said that consent would be needed to link the survey to other sources, but much could be learned about the respondents with the high accuracy of Census linkages to the administrative data.
According to Smeeding, following the work and report of the Commission on Evidence Based Policymaking, attention has turned to a National Secure Data Service (NSDS), which would temporarily link these different data sources in a secure cloud environment for specific analyses, rather than creating a large linked dataset that would reside somewhere. He said NSDS could enable linkages to data from other agencies, such as the Centers for Disease Control and Prevention or other medical records and program data from the Veterans’ Administration.
Smeeding said that consent would be needed to link to these data sources, as well as a personal identification key or SSN, after which the desired data could be extracted from the larger files and stored in a Research Data Center. He characterized this as the dream to which researchers are headed. He reiterated that links can be made from the 1850 to the 1940 Census, with the 1950 Census soon available. AOS can continue this linkage up through the 2010 and soon the 2020 census, so 170 years of American demographic history should be available.
Smeeding concluded with two discussion questions. First, he asked, “How can we interest survey responders to give broad consent to data linkage?” He suggested offering respondents a personal genealogy report. Respondents who are 70, 60, or older can be asked where they were living in 1950 or 1940, their parents’ names, and their parents’ location in 1940
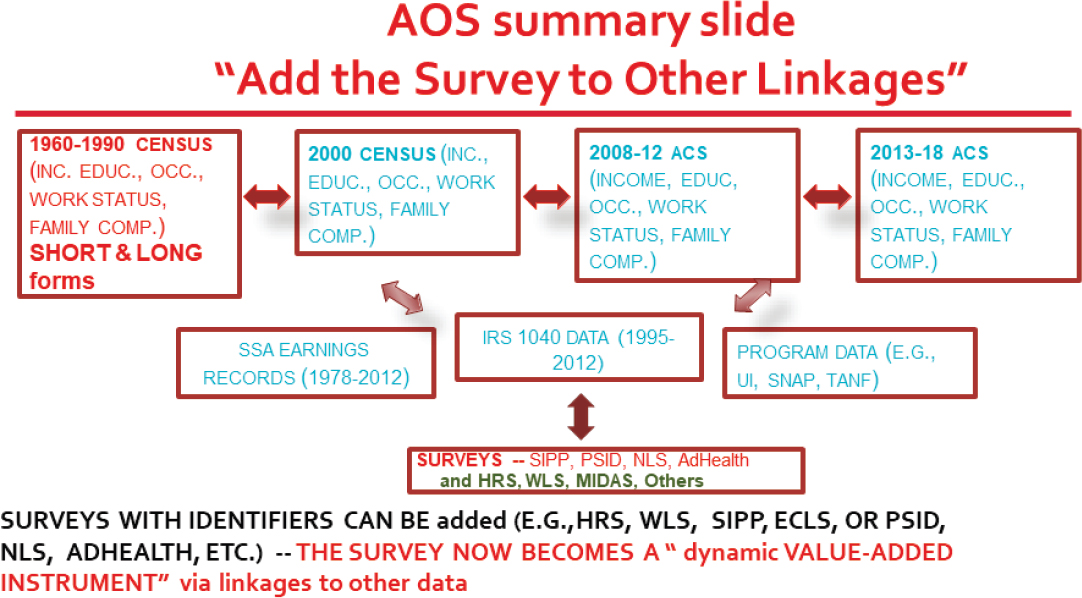
SOURCE: Timothy Smeeding workshop presentation, September 28, 2021.
or 1950. That information can be used to link them back generation to generation using the Census link file.
Second, he asked, “What incentives can help respondents allow you to go forward, linking their records to those of their offspring?” The goal would be consent of the children of the survey respondents, who will be in some of the Censuses between 1950 and 1990, and be able to link to their Social Security, Census, Veterans, IRS, and other records. He said that these possibilities can enrich the current survey dataset by getting more data on the children or on the predecessors of the elderly.
Bias Propensity to Inform Responsive and Adaptive Survey Design in a Longitudinal Study
Andy Peytchev commented on the emergence of many interesting developments and innovations with longitudinal panels. He described what he characterized as an exciting study because its design is flexible and adaptable to other settings and demonstrates the reduction of bias, which is often difficult to do without an experimental design.
Peytchev defined responsive designs as a type of phased design in which different protocols are introduced in stages where researchers monitor different outcomes and obtain cost and error tradeoffs. By contrast, adaptive designs are different and come from a literature on clinical study designs. Adaptive designs tailor the protocols to particular sets of cases/individuals. He said that both of these designs come into play because the researcher can tailor phases of the design and target individual groups of cases.
Responsive and adaptive designs have been increasing in popularity because of increasing nonresponse, Peytchev said. They tend to be more advanced than normal survey designs, he explained, and require statistical models to target more expensive efforts to reduce error in the surveys without implementing a costly protocol for the full sample. The more information available for the models, the more effective they can be, at least theoretically.
Peytchev noted that longitudinal studies offer an opportunity to use these designs because of the availability of information on sample cases from prior waves or from the sampling frame. A variety of modeling approaches have been used, including machine learning approaches. He advocated taking a social science perspective and being careful and deliberate about what variables are used and what exactly is being modeled.
Peytchev described the way response propensity models have been used in surveys to reduce bias due to departures from probability-based designs and survey nonresponse. In this approach, one predicts the probability of being a respondent or nonrespondent using all the possible information that one has to predict how likely they are to participate. While machine
learning methods are a good fit with this approach, he cautioned that implementation can be flawed when it becomes a blind pursuit of maximizing the prediction of whether a person would be a respondent with variables that are not associated with the survey variables of interest.
Propensity models can be used during data collection to identify nonrespondents for alternative treatment regimens or to reduce the risk of nonresponse bias, he continued. Some researchers have targeted the lowest response propensities, those who are the most difficult and necessary cases. Others have used response propensities at later stages in the data collection to identify high-propensity cases among the remaining nonrespondents.
Peytchev introduced the notion of bias propensity. Bias propensity is not simply maximizing the prediction of nonresponse, but including variables that are associated with the survey variables of interest or variables that are close approximations of the things that researchers want to measure as well as demographic characteristics, which are often related to many survey variables. He defined bias propensity as one minus the response propensity based on variables of substantive interest.
Peytchev described research using data from the 2013 Update of the High School Longitudinal Study of 2009. Ninth-graders were originally recruited in schools in 2009, and information on these students was available from multiple sources, including their baseline interviews, follow-up surveys, and some administrative data from the schools. Strengths of this study, he said, were that they had measures of nonresponse bias based on the three different sources of information; they created a simulated control condition using propensity scoring, so that a sample of cases did not receive the experimental treatment; and they evaluated survey outcomes before and after the intervention phase rather than after multiple additional follow-up phases.
Peytchev described the phased design of the study. In Phase 1, an email invitation and postal invitations were sent for a self-administered web survey, followed by telephone interviewers calling sampled members. In Phase 2, which was the focus of this research, a $5 prepaid incentive was offered to cases with the highest bias propensity who had not participated by the end of Phase 1. Additional phases included $15 and $25 promised incentives and abbreviated interviews, which were used as benchmarks to evaluate how well the intervention had worked.
In describing the results, Peytchev said the $5 prepaid incentive had an impact and resulted in a higher response rate. Bias propensity was estimated using a logistic regression model that had two vectors: one with demographic variables and one with substantive variables. To simulate the control condition, a logistic regression model with paradata was fit to data from cases that were not targeted in Phase 2, and used to estimate Phase 2 response propensities without the prepaid incentive for cases in the
treatment group. He said that cases that were predicted to not have participated without the treatment were included in the control group.
Peytchev described the key results (Figure 5-4). The first yellow bar in the figure shows the average absolute bias of 3.6 percent, which was averaged across the multiple estimates from the prior round data, baseline interviews, and administrative data. This number represents a comparison of the estimate from the full sample to those who responded at the end of the main data collection (Phase 1). The second yellow bar (end of Phase 2 control) represents what the bias would have been if they had continued data collection without targeting sample cases with higher bias propensity: the bias would have remained essentially the same. However, the intervention in Phase 2 reduced the average absolute bias by about 1 percentage point, as seen in the third yellow bar (end of phase 2 treatment). He said that about one-quarter of the bias is being removed by this targeting based on predicted bias. The last yellow bar (with all follow-up phases) shows how effective all the other subsequent interventions were in reducing bias and that the average absolute bias drops down to about 1 percentage point.
Peytchev said that the fourth bar could be viewed as a gold standard, which is what the blue bars represent. The third blue bar shows that
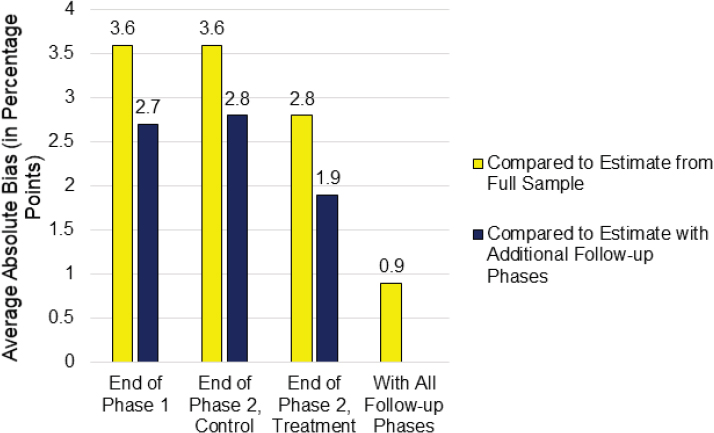
SOURCE: Andy Peytchev, workshop presentation, September 28, 2021, and Peytchev et al. (2020); reprinted with permission.
targeting cases based on bias propensity reduces the average absolute bias from 2.8 to 1.9. Using variables that came from the 2013 survey itself, so there is no assumption about lack of change over time, Peytchev showed that the pattern of results is essentially the same: average absolute bias decreased 0.7 percentage points with the intervention compared to the control condition.
Peytchev concluded by saying that the treatment condition was effective in reducing nonresponse bias compared to the control condition for most estimates, regardless of whether follow-up data, frame data, or baseline data were used. The treatment condition reduced the average absolute bias by approximately one percentage point, or roughly about one-quarter of the estimated bias. Similar reductions in average absolute bias reduction were achieved on the survey variables as well.
Discussion
Davern asked Phillips to start the discussion. Phillips noted that Jäckle’s sample was of the entire adult population, with participants of varying ages, and asked about age effects in the results of the two different interventions she described as more or less important depending on the respondent’s age. Jäckle replied that the consent research deliberately did not focus on social demographic predictors of consent because many previous studies have done so and found inconsistent results. She said that they have seen older participants are much more likely to make a trust-based decision than younger participants, and age effects could be studied further. In the study she described in this session, she pointed out younger groups are more likely to participate in studies involving mobile apps. However, she continued, whether or not people are already doing similar kinds of things for their own purposes is a bigger predictor than their social demographic characteristics. For example, if the respondent was already using a mobile app to check their accounts or bank, then they had a much higher probability of participating in the spending study than those who did not use an app, and this effect was larger than the age effects.
Phillips asked Smeeding about the match rates of Census panels to population surveys and what consent requirements are required to link a survey to link to these data in the FSRDCs. He also asked where researchers can access those data once matched. Smeeding referred to an article by Abramitzky et al. (2021) with information on the linkages, algorithms, and quality of the matching back to 1850. He noted that Steve Ruggles and Rob Warren, both at the University of Minnesota, pioneered the digitizing and matching of the Censuses that go back to 1850. Data linkage is the new science, he said, and, similar to addressing nonresponse in a survey through weighting, a nonmatch across administrative records or across long
panels also needs to be addressed, which Abramitzky et al. (2021) discuss. In terms of consent, Smeeding suggested offering to provide respondents with Census information that would trace their genealogy as a motivating factor. The DCDL project he highlighted in his presentation provides more information on using data in the FSRDCs.
Davern posed a question to Smeeding from Robert Hummer about suggested language for consent to link to the AOS family of surveys. Davern further asked about the most critically important fields to collect in one’s own survey to be able to successfully link. Smeeding suggested talking with Census Bureau staff and looking at the variables used to link the data from the Censuses. He noted Abramitzky et al. (2021) discussed the variables to use for the linkage, but added that asking such questions as “where did you live in 1950; what was your street address; what were your parents’ names” could be useful. He also pointed out that use of administrative data is becoming much more common in the research literature, and about half of data-driven papers in the American Economic Review now use some sort of linked data. He is seeing increased interest and directs researchers to the experts who are creating and making available the linked data.
Phillips asked Peytchev the degree of nonresponse acceptable for some of the approaches he discussed. For example, he asked whether a study that had a 35 percent response rate could use Peytchev’s approach to produce a representative sample, or would a higher response be needed to make those techniques feasible. Peytchev responded that a survey with a 35 percent response rate is a perfect case with a lot of potential for nonresponse bias. He said one could calculate it by multiplying the nonresponse rate times the difference between the respondents and nonrespondents on a survey variable, so a 35 percent response rate would be a multiplier of .65 for any differences that one has between the means. He noted in the 1980ss and early 1990s, when face-to-face surveys had response rates in the 90 percent range, there was little concern for bias. Now, however, every survey is in the realm where nonresponse bias is a real threat.
Peytchev said that he tried to convey that it matters how resources and extra effort are spent to increase the response rate. Rather than spending across the full sample equally, he advocates using resources more strategically to deploy additional effort on the part of the sample that may be more biasing. He noted longitudinal studies can provide a lot of information to inform these designs. He added that the response propensity example is a relatively simple approach that does not require advanced modeling methods, but is more about carefully selecting variables to reduce bias.
This page intentionally left blank.





















