
3
Automated Research Workflows in Action
The committee explored a number of examples of research drawn from a range of disciplines in order to understand how automated research workflows (ARWs) are being implemented as well as the factors that facilitate and hinder their adoption. Most of the use cases were discussed at the March 2020 workshop, while several others were examined through a literature review and interviews. The use cases were selected to provide a broad perspective of ARW implementation. In some cases, the implementation of ARWs is fairly advanced, whereas in others only certain components or aspects of ARWs—such as advanced computation, use of workflow management systems and notebooks, laboratory automation, and use of AI as a workflow component as well as in directing the “outer loop” of the research process—are currently being utilized.
The purpose of examining these specific areas of research was not to develop a comprehensive census of projects and initiatives, and these examples do not represent a complete picture of relevant work in general or in the disciplines that are represented. Rather, the goal was to learn through these use cases how ARWs are changing research at present and to understand their future potential. This exploration of use cases shows the tremendous potential of next-generation workflows to enable and catalyze new approaches to research across multiple, varied fields. Table 3-1 provides a snapshot of the issues and barriers raised in the use cases. Several challenges identified across the domains, such as institutional culture and training needs, are discussed further in Chapter 5.
TABLE 3-1 Use Cases Illustrating the Promise of ARWs and Challenges to Implementation
| Use Case | General Characterization | Opportunities | Challenges and Barriers |
|---|---|---|---|
| Astronomy | History of big data, open data, and cyberinfrastructure is creating the potential for ARWs | Opportunities to use machine learning are expanding |
|
| Particle physics | Established history of using big data and creating sophisticated cyberinfrastructure exists | New opportunities exist for artificial intelligence (AI) approaches, such as simulation-based inference |
|
| Materials science | Approaches are appearing that integrate robotic laboratory instruments, rapid characterization, and AI | Opportunities exist to link workflows and implement closed-loop systems |
|
| Biology | Biomedical research has been overturning reductionist paradigms as they have lost predictive power, paving the way for empirical data to guide discovery | Potential for drug discovery approaches using automated experiments and AI is growing |
|
| Biochemistry | Tighter coupling between data science and chemical synthesis can accelerate optimization in drug discovery | Automation of high-throughput synthesis and screening can accelerate the design–make–test cycle |
|
| Use Case | General Characterization | Opportunities | Challenges and Barriers |
|---|---|---|---|
| Epidemiology | COVID-19 experience has catalyzed initiatives to implement workflows | New data resources could be used to better understand disease interactions and improve treatments |
|
| Climate science | Improving climate models partly depends on the ability to understand and simulate small-scale processes | ARWs hold the promise of rapidly improving the accuracy of model predictions |
|
| Wildfire detection | Interdisciplinary field combines modeling, remote sensing, data science, and other fields | New tools and capabilities using AI can support decision making by public- and private-sector users |
|
| Digital humanities | Increasing use of computational tools and large data sets is expanding the sorts of research questions that can be addressed | New digital data and AI tools can be used to analyze big data (e.g., Latin texts) |
|
| Social and behavioral sciences | Access to large amounts of high-quality data is available at relatively low cost, transforming a number of fields | Real-time access to data and analysis can deliver actionable information |
|
PHYSICAL SCIENCES
Astronomy
Astronomy has long been driven by big data, and the amount of data available from telescopes on the ground and in space is rapidly increasing. Automation and increasingly fine controls on telescopes now make it possible not only to collect data after a careful (human) target selection, but also to close the loop between data acquisition and selecting the next target that is optimally informative given the observational constraints and scientific objectives. Astronomical surveys, such as the Large Synoptic Survey Telescope, Palomar Transient Factory, Catalina Real-Time Transient Survey, and Zwicky Transient Facility, have demonstrated the effectiveness of machine learning (ML) for extracting knowledge from astronomical data sets and streams (Juric et al., 2019). ML has also been used for new astronomical discoveries, including “finding new pulsars from existing data sets; identifying the properties of stars and supernovae; and correctly classifying galaxies” (Royal Society and Alan Turing Institute, 2019). The University of California, Santa Cruz, recently developed a new computer program called Morpheus that “can analyze astronomical image data pixel by pixel to identify and classify all of the galaxies and stars in large data sets from astronomy surveys” (Stephens, 2020).
At the workshop, Szalay (2020) discussed how automated workflows in astronomical research have evolved over the last 20 years and might advance in the future. The Sloan Digital Sky Survey (SDSS),1 one of the largest and most often cited surveys in the field, has revolutionized the interactions between a telescope, its data, and its user communities (NAS, NAE, and IOM, 2009; NASEM, 2018a; Szalay, 2017). All SDSS data, including SDSS-I (2000–2005), SDSS-II (2005–2008), SDSS-III (2008–2014), and SDSS IV (2014–2020), are publicly available, and SDSS-V will start observations in summer 2020. There are more than 8,000 articles published with well over 400,000 citations, 3.5 billion web hits during the past 18 years, 480 million external SQL queries, and 7 million distinct users with 15,000 astronomers (Szalay, 2020). The data obtained from the project were available at the SDSS SkyServer (a public database managed by the Johns Hopkins University), which has been converted to the SciServer framework, a more collaborative platform with system-capturing interactivity and increasingly complex analysis patterns (Szalay, 2020). SciServer currently supports additional scientific disciplines, such as genomics, turbulence/physics, material sciences, and social sciences.
Szalay (2020) stressed the importance of prioritizing data, which requires tradeoffs between scientific value and costs of data management or preservation. There is a need for more relevant data (instead of just larger amounts of data) and
___________________
1 See https://www.sdss.org.
SOURCE: Szalay, 2020.
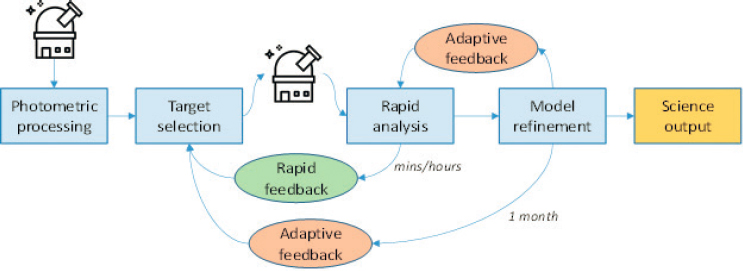
dramatically improving experimental design for using AI to conduct large-scale scientific experiments. One example includes the Next Generation Astronomical Surveys, since observing the spectra of thousands of stars is far more expensive than imaging. For the Subaru Prime Focus Spectrograph project, Johns Hopkins University and Princeton University, with support from the Schmidt Family Foundation, are examining how to use AI feedback from observed targets to improve target selection via reinforcement learning (Figure 3-1).
There is also a need for active curated services to enable scalable data access and analysis. For example, Szalay (2020) compared the evolution of the music industry with the evolution of data science. For the music industry, a traditional long-playing record (LP) or compact disc (CD) has been replaced by download services with apps such as iTunes and online personalized music streaming services. For data science, the equivalent of LP or CD is the process of downloading data (and analyzing them on personal computers); the equivalent of iTunes is the use of data queries to connect to project servers; and the equivalent of music streaming services is that everything will run in the cloud in the next 10 years at an accelerated pace of deployment. According to Szalay (2019), “Algorithms are making the decisions, and soon we will see AI tools setting adaptive choices about survey strategies, including target selection. This may be the beginning of the Fifth Paradigm of Science, where computers decide objectively which experiments will yield the biggest gain in our knowledge.”
Looking forward, deep-learning software will become a commodity as users demand AI-ready data sets to conduct AI-driven scientific experiments and build faster proxy simulations (Szalay, 2020). Manual approaches cannot keep up with the sheer volume of astronomical data, and long-term access to data must be FAIR, open, free, and sustainable at the same time (Szalay, 2020). With regard to using automated workflows and data science tools, Szalay (2020) stated that it would be useful to consider active learning for experimental design from
planning to execution, the use of AI in analyses with explainable inference, and automated workflows for rapid follow-up of transients.
Barriers to progress include the challenge of ensuring steady, long-term support for preserving irreplaceable data. With increased expectations for open or free access to scientific data, what happens to large, high-value data sets when they are completed? Who should be entrusted with these irreplaceable data and how should the decision be made about what to preserve? He suggested the need for a new trusted intermediary to replace the publishers, akin to a “Smithsonian for Digital Data” with endowments partially supported by the federal government. It would be useful to consider the Smithsonian model for preserving and using long-term data on a 30- to 50-year horizon. Funding agencies could become proactive rather than reactive with a 10-year time delay. Although more are needed, he pointed to an increasing number of trusted, archival data repositories that have developed succession plans for stewardship of their data beyond the life of the specific repository and in some cases are certified using the CoreTrustSeal.2
Particle Physics
Modern particle physics involves large collaborations of up to 10,000 researchers structured around very expensive instruments such as the CERN Large Hadron Collider (LHC). Confirming the existence of the Higgs boson, which was announced in 2012, involved combining numerous sources of evidence (Cranmer, 2020). Groups of 10–50 physicists analyzed data from A Toroidal LHC ApparatuS (ATLAS) and Compact Muon Solenoid experiments at the LHC, each group using its own workflow. A technical solution enabling collaborative statistical modeling was developed, and teams were able to combine their data to estimate the probability of generating the actual experimental results given their preexisting theoretical assumptions.
This approach allowed for rapid confirmation of the existence of the Higgs boson and publication of results. However, it was not possible to reproduce the results from what was reported in the original articles, and it took some years to publish the various complex analyses required to do so. Ultimately, physicists began sharing their likelihood scans, allowing others to derive the reported results. Such sharing also allows theorists to test new hypotheses against the experimental results without the need to share the underlying data (Cranmer and Yavin, 2010). The release of full analysis likelihoods from ATLAS reflects this shift in approach (Anthony, 2020).
Looking to the future, active learning and other AI approaches can help power simulation-based inference in physics and potentially in other fields (Cranmer et al., 2020). Researchers faced with inverse problems (i.e., where causal factors are derived from observations, rather than deriving experimental results from
___________________
experiments designed to test specific hypotheses or theories) have until recently been limited to labor-intensive approaches relying on expert-generated summary statistics that are not well suited to high-dimensional data (Cranmer et al., 2020). Advances in active learning enable new approaches to drawing inferences from simulators, with the most promising approach in a given case depending on factors such as the inference goals, the dimensionality of the model’s parameters, the characteristics of the simulator, and so forth. These capabilities can be combined in workflows that implement various inference algorithms. The new approaches hold the possibility of significantly advancing the productivity of research by allowing experiments to achieve, for example, a given sensitivity using half the data.
Taking full advantage of these new techniques will require rethinking many aspects of the research process (Chen et al., 2019). For example, large facilities might be planned and constructed to advance several scientific goals, rather than a single goal, at the outset, given the broader potential for reusing outputs (Cranmer, 2020). If researchers actively encourage reuse of existing workflows, new theories could be explored more efficiently (Strassler and Thaler, 2019). Embedding support for developing tools that advance simulation-based inference in particle physics within specific projects can speed the emergence of tools and systems that attract broader use.
However, there are barriers to progress in advancing active learning approaches that utilize workflows to physics discovery. For example, sharing data can power these new approaches, but attitudes about data sharing vary widely across subfields (Nature Physics, 2019). Given the lack of consensus on data-sharing requirements for publication and whether embargoes on data should be allowed to give data exclusivity to the original research group for months or years, it is not possible for journals to adopt uniform standards. In addition to researcher concerns about being “scooped,” there are significant levels of conservatism in senior faculty which, through their control of promotion or tenure and funding decisions, can hamper progress that might be made from the typically more open attitudes of early career researchers (Cranmer, 2020). The link between new techniques and publishing or reporting is especially significant, since publishing is tightly linked to advancement and other rewards that motivate individual researchers and teams.
Materials Science
Materials research “is strongly focused on discovering and producing reliable and economically viable materials, from super alloys to polymer composites, that are used in a vast array of products essential to today’s societies and economies” (NASEM, 2019a). The materials discovery process involves the conception of materials on the basis of models, synthesis of new materials, and testing or characterization of these new materials. Traditionally, these steps have been
carried out in sequence, with human interventions that have limited throughput. According to Aspuru-Guzik and Persson (2018), it is now possible to close the discovery loop in materials by
integrating automated robotic machinery with rapid characterization and AI to accelerate the pace of discovery. [This] will unleash a “Moore’s law for scientific discovery” that will speed up the discovery of materials at least by a factor of ten—from 20 years to 1 to 2 years. This will catalyze a transition from an Edisonian approach to scientific discovery to an era of inverse design, where the desired property drives the rapid exploration, with the aid of advanced computing and AI, of materials design space and the synthesis of targeted materials.
Service (2019) describes several material science efforts that are pioneering closed-loop experimental workflows. These processes combine automated mixing, preparation, and testing of samples with AI algorithms that evaluate the sample testing results and then decide which materials should be synthesized and tested next. Processes that used to require 9 months for one lab now take 5 days.
McQueen (2020) outlined how ARWs in materials research might evolve. Routine processes will increasingly be automated. Yet, contrary to skepticism in the community, the potential for advances goes beyond optimization or achieving greater throughput and speed. The use of AI in evaluating results and identifying the next set of experimental processes has the potential to qualitatively expand the possibilities of true discovery. Many workflows for analyzing a particular type of characterization exist in isolation, but new value could be unlocked by linking them together. At the same time, it will be necessary to preserve the ability of human researchers to make unexpected observations (McQueen, 2020). Having a “human in the loop” is essential both for making scientific progress and for convincing the materials science community that this is the right way forward.
McQueen identified three interrelated challenges and obstacles to this vision of future materials research: (1) lack of data sharing and access, (2) shortage of researchers who can bridge the gap between materials research experimentalists and those who are developing the necessary software tools, and (3) inertia within the community and resistance to pursuing automated approaches to research powered by AI.
Source data in materials research generally are not shared. This makes it difficult for the community to develop larger-scale shared data resources, as opposed to individual labs relying mainly on the data that they generate themselves. Access to more data is particularly important for identifying the best way to produce a given material by characterizing precisely what was done in one lab and comparing that process with what was done in other labs. Another factor that limits data sharing and reuse is that many instruments used in materials research, such as electron microscopes, generate data only in the proprietary formats unique to each manufacturer.
Regarding human resource needs, there is a gap between the scientific questions being asked and the questions that the data can answer. A translation step is needed, requiring experts with knowledge of data science and material science. However, it is difficult to convince particularly senior researchers of the value of such experts. It will require additional time and effort to arrive at the point where data science and material discovery are no longer regarded as separate activities.
Finally, McQueen said that change is hampered by the fact that current academic reward systems and research assessment approaches generally undervalue creation, sharing, and curation of data or the creation of software that facilitates automated experimentation and AI-facilitated discovery. The peer review process often makes it difficult to get funding for data stewardship or workflow systems innovation. One way to mitigate this problem could be enhancing the collection capabilities of national facilities or multi-institutional consortia.
Kristin Persson (2020a) described one such effort, the Materials Project,3 which provides open web-based data on known and predicted materials and analysis tools to those searching for novel materials for batteries, solar cells, and computer chips (Persson, 2020b). The project uses high-performance computing within a sophisticated integrated infrastructure consisting of Pymatgen (an open-source Python-based analysis library) and Fireworks (automated open-source workflow software) to determine structural, thermodynamic, electronic, and mechanical properties of most known crystalline inorganic compounds (Hill et al., 2016). A high-level interface to the Materials Application Programming Interface has been built into the Pymatgen analysis library that allows users to programmatically query and analyze large quantities of materials information. To create a more closed-loop workflow, tools are needed to aid in dynamic rerouting, error management, flexibility, and constant communications among domain scientists (Persson, 2020a). Lack of data availability for data-hungry methods limits the use of deep learning.
The Clean Energy Materials Innovation Challenge Expert Workshop in 2017 highlighted the need to develop the materials discovery acceleration platforms that integrate automated robotic machinery with rapid characterization and AI (Aspuru-Guzik and Persson, 2018). Since then, several institutions have been working to advance the field. For example, the University of British Columbia focuses on advanced robotics with synthetic organic chemistry (Hein Lab, 2020), the Air Force Research Laboratory leads research on carbon nanotubes, and the National Institute of Standards and Technology is designing robots that automatically perform experiments recommended by AI with minimal human intervention (Hattrick-Simpers, 2020).
While there are many notable materials data resources (Hill et al., 2016), a centralized repository of information about materials science, similar to the Protein Data Bank that archives information related to the three-dimensional
___________________
structures of large biological molecules, would be useful (Persson, 2020a). Stable and adequate funding is needed for maintaining and curating data, as data curation emerges as key to progress. Although several federal government initiatives, such as the Material Genome Initiative in 2011 and the Materials Science and Engineering Data Challenge in 2015, have been implemented to encourage the use of publicly available data to model or discover new material properties, additional open data policies are needed to accelerate discovery. There is a need to develop multidisciplinary international teams of scientists and engineers with expertise in chemistry, materials science, advanced computing, robotics, AI, and other relevant disciplines (Aspuru-Guzik and Persson, 2018; Persson, 2020a).
BIOMEDICAL SCIENCE
Biology
According to Murphy (2020), closed-loop experimental systems relying on automation and AI can advance experimental biomedical research. The last several decades have overturned reductionist paradigms in biology, challenging the belief that the functioning of living organisms can best be understood by breaking them down into systems and components that operate according to fixed rules.
For example, conventional understanding of the relationship among DNA, RNA, and proteins is that messenger RNA (mRNA) transcribes information from DNA and then serves as a template for the assembly of a protein that carries out a specific cellular function. However, some exceptions to what was thought to be a fixed relationship among sequence, structure, and function have emerged, such as reverse transcriptase, in which an enzyme (protein) uses an RNA template to generate complementary DNA. Retroviruses use reverse transcription to replicate their genomes. Other exceptions and complexities include transposons (DNA segments that move between different positions in a gene), introns (DNA sequences that are “spliced out” in the formation of the final mRNA), and prions (misfolded proteins that can transmit their shape onto normal proteins of the same type and are hypothesized to be the cause of some diseases). The result is that reductionist paradigms have lost their predictive power in understanding the complexity of cells, tissues, and organisms.
The development of systems biology, which involves building predictive models based on a block of experiments, has been one response. At the workshop, Murphy (2020) argued that systems biology approaches are limited because empirical models cannot be proven correct; they can only be refined and improved over time with more and better data. Given the inherent complexity, absence of fixed rules, and inability to characterize and measure the effect of every biological change on every variable, human understanding is not possible. Thus a new approach is needed in which empirical data are gathered through automated experiments selected by AI.
This approach is being tested in drug discovery (Murphy, 2011). Normally, candidate compounds are screened according to whether and how strongly they affect the biological target associated with a disease. However, choosing the compound with the strongest effect on the target requires additional screening steps to determine whether it acts on other targets that produce toxic side effects. Being able to test all candidate compounds against all targets to find the optimal compound (i.e., strongest effect with no side effects), rather than testing each compound against each target in sequence, will accelerate discovery in this space. Researchers will be able to build empirical predictive models that generate faster, more efficient results.
Use of AI-selected, automated experiments is potentially very powerful. General-purpose tools can be used, in a situation analogous to self-driving cars. The AI is told where to go, not how to get there. As an example, a retrospective test of an approach utilizing active ML yielded promising results (Kangas et al., 2014). The test utilized data from PubChem and involved 177 assays, 133 unique protein targets, 20,000 compounds, and about 1 million experiments. An active learning algorithm was tested against other algorithms to identify compounds affecting the target through simulation of a series of experiments, with the relevant database information hidden from the algorithms. In this analysis, 57 percent of the active compounds were identified by performing 2.5 percent of the possible experiments by the active learning algorithm, compared with 20 percent identified through a traditional approach of building a model for each target. More recently, a prospective study was undertaken in Murphy’s laboratory at Carnegie Mellon University using laboratory automation to execute experiments selected by AI to model complex phenotypes (Naik et al., 2016). There was no human in the loop in this case. By performing 28 percent of the possible experiments, the model was 92 percent accurate, about 40 percent more accurate than what was achievable using random selection.
Murphy identified several barriers to progress, beginning with a shortage of experts who can bridge the gap between disciplinary and laboratory automation expertise. Autonomous laboratory automation and standards are also needed. Several companies are now providing services in this space, such as Emerald Cloud Lab4 and Strateos,5 that perform experiments on demand. Real-time primary data sharing from individual labs, and the infrastructure to do so, are also needed. National research resources that execute particular types of automated experiments on request—analogous to what exists in astronomy and physics—are also needed. The ability to test alternative approaches through such facilities will enable cost-sensitive, proactive learning.
Finally, researcher training will need to change. Currently, graduate students in biology are taught to pipette and manipulate experimental conditions by hand.
___________________
In the future, it will be more important that researchers are able to choose the overall goals of their research and design a campaign using diverse technologies to reach the goal. Humans will also need to invent new measurement technologies, and to develop and improve AI methods.
Biochemistry
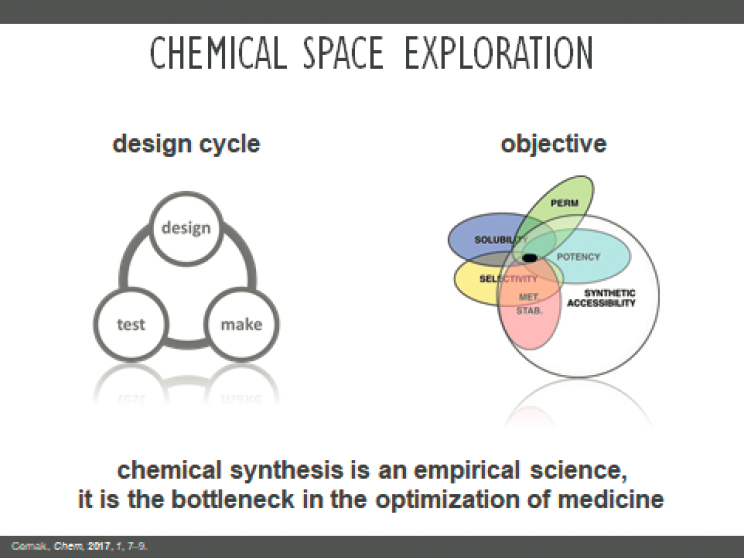
Chemical synthesis is a two-centuries-old empirical science and is the bottleneck in the optimization of drug discovery, a process that typically takes years (Cernak, 2020). A tighter coupling between chemical synthesis and data science would accelerate this process. The COVID-19 pandemic illustrates the urgent need for rapid development and testing of novel medications in times of viral outbreaks.
Cernak (2020) identified high-throughput synthesis and screening as areas ripe for new advances. Small molecules used in pharmaceutical applications, including antiviral medications such as those needed to treat COVID-19, are difficult and time-consuming to manufacture and screen. They require multistep reactions to synthesize. The objective is to use this design–make–test cycle to identify molecules that combine multiple properties such as permeability, solubility, selectivity, stability, potency, and synthetic accessibility (see Figure 3-2).
Manufacturing, in particular, is a critical bottleneck in this cycle. Researchers are working to accelerate chemical synthesis through automated reaction equipment and in-line/in-situ analysis tools. For example, Timothy Cernak’s lab at the University of Michigan is able to perform 1,500 experiments rapidly through nanoscale synthesis using robotics (Cernak, 2020). This provides a systematic snapshot of the reaction landscape. Reaction enumeration, which involves transforming the chemical reaction into a machine-readable form, such as a graph, is another important step. The ultimate aim is to automate the process of retrosynthetic analysis through data science (Cernak, 2016).
An example of efforts along these lines is the Center for Computer-Assisted Synthesis,6 supported by the National Science Foundation. Companies are also working within this new paradigm for drug discovery. Insitro7 seeks to “leverage the tools of modern biology to generate high-quality, large data sets optimized for machine learning.” X-chem is a premier DNA-encoded library technology company that announced a spinout company called ZebiAI8 to work in partnership with an ML group at Google.
Barriers to progress within the community include resistance and lack of large-scale resources to enable automation. Regarding the former, chemical synthesis has traditionally been considered something of an artisan process, and so
___________________
6 See https://ccas.nd.edu/.
SOURCE: Cernak, 2020.
gaining acceptance for automating important components of the process is difficult. The challenge is to “teach data science to organic chemists” (Cernak, 2020). The lack of large-scale resources for automation, such as sufficiently characterized data, is another obstacle. Cernak’s lab generates its own data since much of the data openly available in the literature may be noisy or lack sufficient metadata for machine readability. Proprietary database software systems such as Reaxys or SciFinder limit the volume of entries that can be accessed without buying access to the entire database, which academic labs might find prohibitively expensive.
HEALTH AND ENVIRONMENT
Epidemiology
The pandemic induced by COVID-19 has touched all aspects of society. It has also created opportunities to assess the capabilities of modern scientific workflows and to innovate new paradigms. In this respect, it is important to recognize that the appearance of COVID-19 coincides with the rise of cheap ubiquitous sensors and the big data revolution, such that actions are increasingly
collected, stored, and made accessible for analytic investigation in a digitized form. By combining modern workflow systems with large amounts of personal data, drawn from a wide variety of domains, there is an expectation for breakthroughs in public health policy and assessment, rapid refinement of guidelines for clinical care, repurpose of known drugs for treatment, and crafting of novel vaccines.
Many examples of rapidly organized scientific endeavors associated with COVID-19 have emerged. For instance, various consortia, such as the National COVID Cohort Collaborative (N3C) funded by the National Center for Advancing Translational Sciences of the National Institutes of Health, have been formed to collect and make accessible clinical data about individuals infected with COVID-19 (NCATS, 2021; Rubin, 2020). The Global Platform for the Analysis of SARS-CoV-2 Data was launched by an international collaboration on the Galaxy platform (Galaxy, 2021b; Maier et al., 2021). The Virus Outbreak Data Network is a coordinated effort to allow observational patient data from various heterogeneous information systems to be made FAIR and machine actionable (Queralt-Rosinach et al., 2021). From a discovery perspective, AI-driven workflows have been applied to sift through large lists of drugs to search for those that could interfere with mechanisms by which COVID-19 infects cells. It was further shown that workflow automation could be combined with techniques from network science to search for drugs that would interact with groups of proteins associated with the disease.
These efforts have generated promising results. For example, a 2021 article reports on a team that used N3C to assemble the largest nationally representative cohort of patients with cancer and COVID-19 and are using this cohort to better understand the effects of COVID-19 on cancer outcomes and improve treatments (Sharafeldin et al., 2021). Another team used N3C to compare the effects of alternative treatments for hyperglycemia in SARS-CoV-2–positive adults (Kahkoska et al., 2021).
However, the extent to which these breakthroughs could lead to actual treatments and, more generally, to solutions to pandemics is dependent on a number of factors. This is because the search for answers is not simply a matter of collecting vast amounts of data and subjecting them to continuous automated analysis. Rather, it requires addressing a complex combination of technical, legal, and social affairs that need to be resolved in order to be successful. For instance, in the context of clinical care, the gold standard by which care routines, interventions, and treatments are assessed is the randomized clinical trial, which reduces sample bias. Yet the data currently being collected in the clinical domain with respect to COVID-19 are not the outcome of a randomized clinical trial and are thus subject to certain biases. For example, patients that present to health care facilities generally only present when they have symptoms that are recognizable and have the ability to access a testing facility (whether it be at a large medical center or a smaller stand-alone testing center).
One of the challenges in attempting to rapidly respond to an emergency is the potential to shirk provenance. In scientific investigation, particularly when the investigation is in the general public interest, it is critical to ensure that the data collected for the investigation are correct. This does not mean that the data must be made publicly available for all to inspect and scrutinize, particularly when there are competing interests (e.g., privacy concerns for patients who did not consent to the public disclosure of their identities), but that there must be proof that the data are not fabricated and have not been doctored. Unfortunately, in the case of COVID-19, there have been clear cases where the rush to collect and analyze data has led to questionable results.
These cautionary tales are not indications that the system for data collection, management, and analysis is fundamentally broken. Rather, it provides an illustration of what can go wrong when a system is hastily erected. As we work toward the development of automated methods for pandemic detection and subsequent mitigation, it will be critical to ensure that the data have clear provenance, that the workflows and analytics conducted within them are verifiable, and that plans for data sharing, access, and accountability for abuse and misuse of the data, as well as findings from such workflows, are established from the outset. In this respect, it is critical to continue to create common data models, promote approaches to mitigate bias in data collection and analysis, and support the infrastructure necessary to support—if not in real time, at least in near real time—scientific investigation that leads to guidance on how best to mitigate public health threats.
Climate Science
Climate change is upon us. Even with mitigation strategies, it requires adaptation to a new normal, but what that new normal will be remains unclear. Some large-scale features of climate change, such as the more rapid warming of continents relative to oceans, are well understood and well simulated by models. But projections of climate change and the associated risks, for example, of flooding, wildfires, and high-impact weather events, continue to be marred by large and poorly quantified uncertainties that hamper informed decision making and make it more difficult to adapt proactively and effectively (e.g., Schneider et al., 2017b; Global Commission on Adaptation, 2019; Hill, 2021; IPCC, 2021).
The principal source of uncertainties in climate projections is small-scale processes, such as the turbulent motions and microphysical processes controlling clouds, turbulent mixing in the oceans, or small-scale frictional or rheological processes at the base of or within ice sheets. These small-scale processes are too costly to compute globally, yet are crucial for modeling climate (NASEM, 2012). High-resolution simulations in limited areas have been used for some time to inform reduced-order models of clouds and of atmosphere and ocean turbulence, which are used in global models. Typically, the high-resolution simulations are
carried out in a few locations, at selected times of year, for example, at locations and times when data from field campaigns are available (e.g., Siebesma et al., 2003; Stevens et al., 2005). This approach has provided a limited sample of computationally generated data.
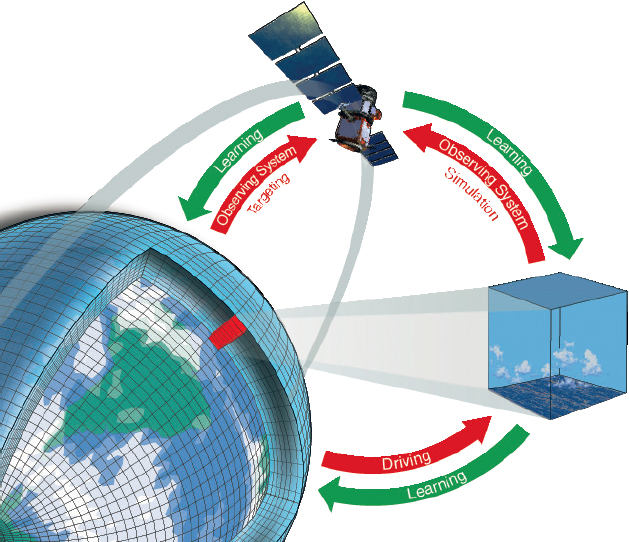
The workflow for carrying out high-resolution simulations, calibrating reduced-order models of small-scale processes, and quantifying their uncertainties can now be automated and accelerated by orders of magnitude. Targeted high-resolution simulations can be spun off from a global climate model on the fly, wherever and whenever needed, to provide detailed information that the global model on its own is unable to provide (Schneider et al., 2017a). Spinning off such high-resolution simulations lends itself well to distributed computing approaches and hence is very scalable. Instead of exploiting such high-resolution simulations in only a few locations and at selected times of year, experimental-design algorithms can be used to optimize the placement of high-resolution simulations to be maximally informative about small-scale processes in global models. Tools from data assimilation, pioneered in weather forecasting (Kalnay, 2003), can be combined with newer techniques from ML to accelerate learning about small-scale process models in computationally expensive climate models (Cleary et al., 2021). More data-hungry, deep-learning methods can also be used in place of process-based, reduced-order models (e.g., Rasp et al., 2018; Yuval and O’Gorman, 2020).
Additionally, similar tools can be used for a global climate model to learn automatically from the plethora of global climate data that are now available, be they from space, the ground, or autonomous ocean vehicles (Schneider et al., 2017a). Conversely, a climate model that learns automatically from observational data can help determine the value that new observing systems would provide, for example, in terms of reduced uncertainties in climate projections. Gaining such insights “in observing system simulation experiments (OSSEs) is increasingly required before the acquisition of new observing systems (e.g., as part of the U.S. Weather Research and Forecasting Innovation Act of 2017)” (Schneider et al., 2017a). More generally, automating the workflow for learning from observational data makes it possible to quantitatively pose the experimental design question about what kind of observations would be maximally informative to reduce climate model uncertainties further. Figure 3-3 illustrates a model–learn loop for climate modeling.
Weather forecasts have made great strides over the past decades, thanks to improvements in the automated assimilation of observations (Bauer et al., 2015). Climate projections can now advance similarly, by simultaneously harnessing observations and data generated computationally in high-resolution simulations. The acceleration in the rate of improvement of climate models has the potential to lead to a qualitative leap in the accuracy of climate projections.
Unlike in other fields, climate sciences and weather forecasting data have been open, accessible, and widely shared worldwide, going back to global data-sharing frameworks developed in the 1950s. This openness facilitates the development of ARWs and quality control of data by cross-checking among
SOURCE: Schneider et al., 2017a.
disparate data sets. However, the openness and the benefits that accrue from it are now under threat because government agencies are beginning to purchase data from commercial providers under restrictive licenses.
Wildfire Detection
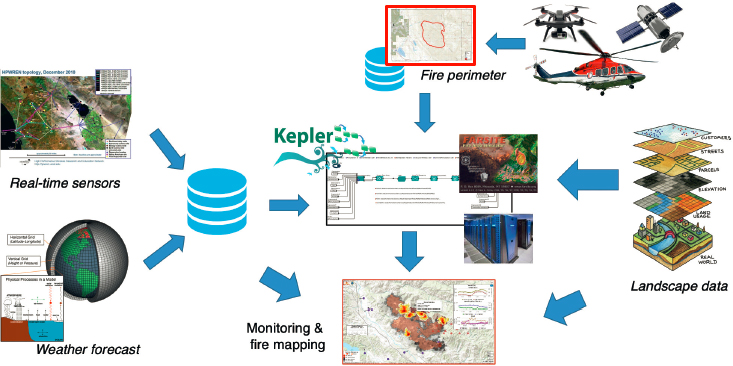
There is an urgent need for better modeling of a range of environmental hazards, including societal impacts, and innovative approaches combining advanced computing, remote sensing, data science, and the social sciences hold the promise of mitigating hazards and improving responses. In pursuing these advances, “there are still challenges and opportunities in integration of the scientific discoveries and data-driven methods for detecting hazards with the advances in technology and computing in a way that provides and enables different modalities of sensing and computing” (Altintas, 2019). The National Science Foundation–funded WIFIRE project9 created an integrated system with services for wildfire monitoring, simulation, and response, providing an end-to-end management infrastructure
___________________
9 See wifire.ucsd.edu.
SOURCE: Ilkay Altintas.
from data sensing and collection to modeling efforts using a continuum of computing methods that integrate edge, cloud, and high-performance computing (see Figure 3-4). The multidisciplinary team formed significant partnerships with data providers, science communities, fire practitioners, and government organizations to solve problems in wildland fire. The WIFIRE project is used for data-driven knowledge and decision support by a wide range of public- and private-sector users for scientific, municipal, and educational purposes.
The integrating factor in WIFIRE is the use of scientific workflow engines as a part of the cyberinfrastructure to bring together steps involving AI techniques on data from networked observations (e.g., heterogeneous satellite data and real-time remote sensor data and computational techniques in signal processing, visualization, fire simulation, and data assimilation) to provide a scalable, repeatable, and customizable closed-loop capability.
In addition, WIFIRE represents a common theme of applications using ML on top of nontraditional hardware and making use of the new processors that have emerged in recent years, including graphics processing units, field programmable gate arrays, and edge accelerators. The common theme of these applications, integrating AI workloads, is “their need to run in specialized environments for reasons such as the on-demand or 24x7 nature of the tasks they are performing, and difficulties regarding their portability, latency, privacy, and performance optimization” (Altintas, 2020a). Moreover, there is a need for composable systems where these applications are integrated with high-performance computing or high-throughput computing tasks.
A typical example of these applications is the role of real-time edge processing and the use of ML and big data in wildfire behavior modeling applications
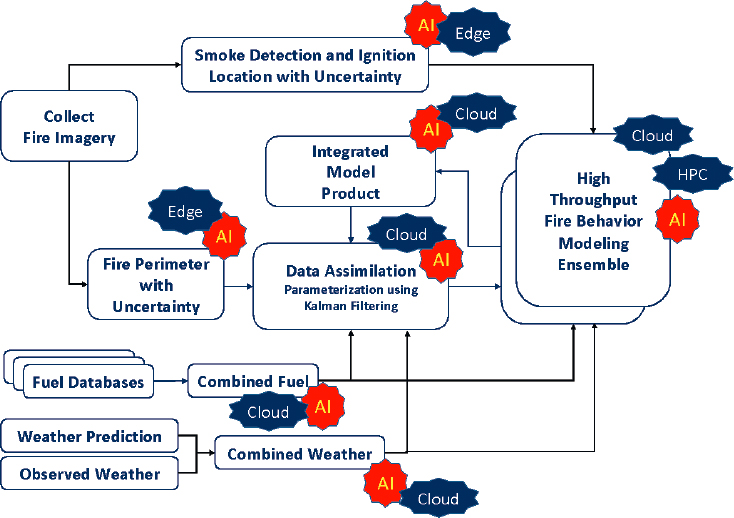
SOURCE: Ilkay Altintas.
within the WIFIRE cyberinfrastructure. WIFIRE’s dynamic data-driven fire modeling workflows depend on continuous adjustment of fire modeling ensembles using observations on fire perimeters generated from imagery captured by a variety of data sources including ground-based cameras, satellites, and aircraft. Typically, perimeter generation is performed in a big data and/or edge computing environment while fire modeling is performed in an HPC or HTC environment, depending on which fire modeling codes are executed (Altintas, 2020b). Figure 3-5 illustrates an integrated workflow with the various steps marked with the execution infrastructure required.
Learning from imaging to decide on parameterization of simulations and combining this learning with the insights gained from analyzing the time-series output of simulations promise many benefits ranging from shorter runtimes and time to discovery, to decision support for urgent applications, and less energy usage for computing.
Currently, there are many new tools and technologies (e.g., for scheduling and resource monitoring) to scale and manage the components of these application workflows homogeneously. However, these application workflows are composed of steps that require a heterogeneous cyberinfrastructure ecosystem that involves
dynamic resource management and coordination. Current cyberinfrastructure lacks an integrated environment that can pull data from a number of resource monitoring tools and turn these federated data into predictive intelligence needed to steer application workflows in a dynamically scalable and data-driven fashion at the time of workflow execution.
DIGITAL HUMANITIES
Digital humanities make use of computational tools to conduct textual search, visual analytics, data mining, statistics, and natural language processing (Biemann et al., 2014). Similar to applications in science and engineering,
the processing of large data sets with appropriate software opens up novel and fruitful approaches to questions in the “traditional” humanities. Thus the computational paradigm has the power to transform them. One reason is that this kind of processing opens the way to new research questions in the humanities and especially for different methodologies for answering them. Further, it allows for analyzing much larger amounts of data in a quantitative and automated fashion. (Biemann et al., 2014, pp. 80–81)
The past decade or so has seen development of capacity and expertise in the creation of workflows for the humanities, which require “abstract representations of research phases, taxonomies of scholarly activities, in conceptual frameworks, or in scholarly ontologies” (Koolen et al., 2020). Subdisciplines have both the benefit and the challenge of ever-growing amounts of data, the quantity of which no human (or group of humans) could digest in analog format. Examples of digital repositories to collect and make use of data include the Open Islamicate Texts Initiative10 and the Chinese Text Project,11 both of which contain 1 billion words and are growing.
One notable example of a leader in the field is the King’s College London Digital Lab.12 A team of about 15 research software engineers and other experts support the research conducted by other academic departments, including cultural heritage, history, and archeology, as well as outside organizations. Examples range from a project to determine the origins of the Gough Map (the first known map of the British Isles) to archiving and making accessible the roughly 100 different digital research projects that the lab inherited upon its creation in 2015 (Smithies et al., 2019). Another relevant project is the Machine Learning for Music project, “a community of composers, musicians, and audiovisual artists, exploring the creative use of emerging Artificial Intelligence and Machine Learning technologies in music.”13
___________________
10 See https://iti-corpus.github.io.
11 See https://ctext.org.
As the field has emerged, the Alliance of Digital Humanities Organizations (ADHO)14 formed in 2005. It now comprises 10 professional societies worldwide, including the Association of Computers and the Humanities, based in the United States, and the European Association for Digital Humanities, among others. Its mission is to promote and support “digital research and teaching across all arts and humanities disciplines, acting as a community-based advisory force, and supporting excellence in research, publication, collaboration, and training.” ADHO members publish peer-reviewed journals (such as DSH: Digital Scholarship in the Humanities), contribute to reference books developed for the field, and host discussion forums and conferences.
Efforts to integrate digital arts and humanities across Europe include two initiatives: DARIAH-EU (Digital Research Infrastructure for the Arts and Humanities)15 and the Common Language Resources and Technology Infrastructure.16 In the United States, the Office of Digital Humanities within the National Endowment for the Humanities offers grants to digital projects, many of which produce white papers for further knowledge sharing. These efforts could contribute to the integration of resources necessary to apply next-generation workflows to humanities research.
A case study presented at the workshop involved philology to show the potential and challenges of ARWs in the humanities. Philology involves linguistic or textual records to reconstruct “anything that happened in the human mind or outside in the world, from understanding a Cuneiform text from the ancient world to how Iranian, Farsi-language newspapers are reporting on the coronavirus today” (Crane, 2020). While philology predates the use of digital tools by centuries, in recent years, computational approaches have had the potential to transform what researchers can learn through textual records.
In addition to the sheer number of words in any one language, researchers are faced with the multitude of languages, ancient and modern, through which people have communicated ideas over the centuries. Crane (2020) acknowledged that a principal challenge is not “1 billion words of English language newspapers but 1 million words of poetry in 100 languages,” which calls for networks of deep annotation, that is, machine-actionable representations of fine-grained judgments about a source. The ability to provide precise citations across texts is also aided by digital tools, a need that also exists in the sciences. Tools can now reference any word, symbol, or element in any surviving text-bearing object.
AI-enhanced tools are also allowing researchers to see patterns never visible before. For example, the Viral Texts Project17 is mapping networks of the reprinting of articles in 19th-century newspapers and magazines. Text is generated from scans of newspapers, with their millions of words, even in cases where the texts
___________________
14 See https://adho.org/.
15 See https://www.dariah.eu/.
16 See https://www.eudat.eu/use-cases/common-language-resources-and-technology-infrastructure.
are degraded and barely legible for humans to read. Thus, researchers can trace the spread of ideas, such as abolition of slavery, to understand how certain ideas became “viral” in a historic context.
The vast amount of material written in Latin pre-1750 represents a great understudied collection of materials that AI can address, according to Crane. Through that time, Latin was the majority language of scholarship in most European countries, no matter the everyday spoken language, and was used in dissertations, scientific publications, and other materials. Millions of documents are lying unread in libraries and archives. Digitizing the materials, and then setting up workflows to allow for search and extraction can provide clues to the development of European thought. A particular quotation about a concept used in one book can be searched for in 3 million other books to understand how it is used in different times and contexts. Similarly, an amorphous concept such as “honor” can be traced to see the meaning placed on it by different cultures.
Similar to the sciences and engineering, ARWs in the humanities result in a hybrid environment that integrates human feedback and contributions with ongoing automated analysis of linguistic sources. The machines can mine data, but a human in the loop must provide the training material that drives the artificial intelligence systems and corrects raw material that gets fed back into the system. While ARWs can mine data, suggest patterns, and point to new directions, humans are a critical part of the ecosystem. According to Crane, the digital humanities are at a pivotal moment, as a new generation of scholars engages in research. “There is a gap between traditional research and these new tools,” he said at the committee’s March workshop. “What faculty are trained to do and what graduate students are equipped to do is different.”
SOCIAL AND BEHAVIORAL SCIENCES
The factors that are driving and facilitating the implementation of ARWs in the social and behavioral sciences (including economics, sociology, political science, and psychology) are broadly similar to those operating in other domains. These include the rapidly growing ability to access large amounts of high-quality data—particularly streaming data—at relatively low cost, the advance of ML tools for deriving insights from those data, and the urgency and importance of the questions that can be addressed using these approaches. At the same time, researchers in the social and behavioral sciences face some of the same barriers to the advance of ARWs as those faced in other domains, as well as some distinct issues.
Traditionally, researchers in the social and behavioral sciences have mainly worked with small or medium-size data sets, such as survey data collected by researchers themselves, or data generated by government statistical agencies on a scale allowing their downloading and analysis by the researchers themselves using standard statistical software (Turner and Lambert, 2014). The sorts of questions addressed include how tax policy changes affect gross domestic product
growth and income distribution and how the policy positions of political parties affect voter preferences. Increasingly, statistical agencies such as the Census Bureau, Bureau of Labor Statistics, and Social Security Administration are making larger data sets available. Researchers are also able to access data from private companies such as Google, Amazon, and credit card companies through special agreements (Einav and Levin, 2014).
There is growing recognition of the potential for new data resources to deliver real-time, actionable information. The Foundations for Evidence-Based Policymaking Act (Public Law 115-435) received bipartisan support when it passed Congress in 2019. It requires “agency data to be accessible and requires agencies to plan to develop statistical evidence to support policy making”. As Julia Lane commented at the committee’s workshop, “We are at a golden moment in which lots of people care. . . . Data sits at the core of what federal agencies, and state and local agencies, are asked to do.”
The following examples illustrate how new data resources and advanced analytics are being applied in the social and behavioral sciences. While these approaches do not constitute ARWs as such, they involve innovative uses of information technology that will likely facilitate the use of AI in research and future implementation of ARWs. The first example is Opportunity Insights, directed by economist Raj Chetty at Harvard University. This project identifies barriers to economic and social mobility in the United States. An Opportunity Atlas considers more than a dozen neighborhood-level characteristics, drawn from multiple data sets, to answer a basic but critical question: Which neighborhoods in America offer children the best chance to rise out of poverty? Opportunity Insights not only shares its publications on its website,18 but also its data sets and replication codes, as well as the lectures, slides, and other materials used in Chetty’s course on using data to solve economic and social problems.
Another example is urban informatics, which harnesses public data to improve services and empower communities. In one application, Daniel O’Brien of Northeastern University analyzed a data set of calls to Boston’s 311 system (in which citizens can report non-emergency needs to city officials) to draw conclusions for city leaders and community groups (O’Brien et al., 2017). He has emphasized the millions of interactions captured in digital records, including birth, marriage, and death certificates; school test scores; and building permits, to name a few.
Some social and behavioral sciences researchers are explicitly applying ARWs in their work. Wu et al. (2020) have developed a workflow that they suggest has broader applicability in order to study the impact of Chinese migration patterns, specifically on children who are left behind in China’s provinces while their parents work elsewhere. The workflow allows for feature selection criteria through ML approaches not bound by the researchers’ knowledge. In addition,
___________________
the ARW proposed by the authors more fully deals with dynamically changing, complex variables than standard regression methods. Similarly, Cedeno-Mieles et al. (2020) proposed a system for networked social science experiments that automates the steps involved in analyzing experimental data, building models to capture the behavior of human subjects, and providing data to test hypotheses. Finally, Bergmann et al. (2021) have developed a tutorial to help economists use the Snakemake tool for managing reproducible data analysis workflows.
As in other disciplines, the amount of data becoming available to social and behavioral scientists presents challenges related to the size of the data sets, as well as ensuring the integrity of identifiable personal information, reproducibility of results, and archiving. According to Lane (2020), the massive scale and dispersed location of data sets, as well as lack of clarity about the level of expertise behind their production, limit their potential contribution and broader use. To overcome this challenge, the Coleridge Initiative19 (of which Lane is a cofounder) has as its goal to “change the empirical foundation of social science, statistical and public agencies in the United States and transform understanding of how our society works.” Among other efforts, the initiative sponsored a Rich Context competition during 2018 and 2019, with a focus on the social sciences, that aimed “to implement AI to automatically extract metadata from research—identifying data sets in publications, authors, and experts, and methodologies used” (Lane et al., 2020). Twenty teams from around the world participated in a first phase of the competition, and four finalists (one from the United States, one from South Korea, and two from Germany) participated in a second phase in 2019 (Lane et al., 2020). The great challenges of our time are human in nature—climate change, terrorism, overuse of natural resources, the nature of work, and so on—and these require robust social science to understand their causes and consequences. Effective use of data for social science research depends on understanding how data sets have been produced and how they have been used in previous works. The opportunity at hand is to leverage ML advances to create feedback loops among the entities involved: researchers, data sets, data publishers, publications, and so on (Nathan, 2020).
Although social and behavioral scientists have embraced many new technologies, some have not taken full advantage of automation but continue to rely on manual and ad hoc techniques (Yarkoni et al., 2021). The five core investments in automation that Yarkoni et al. (2021) recommend extend to other disciplines, but they presented their case through a social science lens:
- Standardization: Recognizing that a single standard is neither possible nor desirable in the social sciences, they suggest “an efficient way to ensure commensurability while encouraging innovation is to develop meta-standards that support common access to different standards.”
___________________
- Data access: Given the nature of the field, data on human subjects provide critical insights—but the reuse of those data are often restricted. Automated data extraction may facilitate both safer and increased access to data.
- Search and discoverability: Adapting existing techniques from other fields can help social scientists in overcoming the challenge of finding the relevant findings among an overwhelming number of articles and data sets.
- Claim validation: Automation related to enumeration of statistical assumptions, sensitivity analysis to assess assumptions that support a result, and creation of checklists of researchers to verify in-progress work.
- Automated insights: In keeping with the focus of this study on ARWs to contribute to new discoveries, the fifth and final area particularly merits attention. As they wrote, “Perhaps the most tantalizing opportunities for automation-related advancement of social science lie in the area of scientific discovery and insight generation.” Examples include signal discovery and hypothesis generation, automated meta-analysis, and development of reasoning systems or inference engines.
The social and behavioral sciences have several existing practices and institutions that can help facilitate the development and implementation of ARWs. For example, there are established organizations charged with data stewardship and related training such as the Inter-university Consortium for Political and Social Research and the National Opinion Research Center. Finally, the American Journal of Political Science requires that the data supporting published articles undergo an independent verification process.
This page intentionally left blank.


























