
Appendix H
Topic Analysis of NIH Autoimmune Disease Research Grant Abstracts
Authored by:1 Chris Barousse2,3
INTRODUCTION
In 2019, Congress tasked the National Academy of Sciences, Engineering and Medicine (the National Academies) to evaluate National Institutes of Health (NIH) research on autoimmune disease. The scope of work for the committee included a review of trends in the focus (topics) of autoimmune disease research. The goal of this paper is to provide insight into the most popular research topics associated with 8,470 NIH autoimmune disease research grant abstracts using latent dirichlet allocation (LDA), a statistical modeling technique used in natural language processing.
BACKGROUND
LDA is a popular, well-documented statistical method used in natural language processing (NLP) settings. LDA groups what the NLP field refers to as a corpus of texts by “latent” topics, which are found by looking at the similarity of the texts’ contents (Blei et al., 2003). As of 2021, the original paper describing LDA methodology has been cited 5,714 times. Several software packages in the R statistical language can implement LDA, and this method has been applied specifically to scientific abstracts to analyze funding patterns and trends in research (Bittermann and Fischer, 2018; Park et al., 2016; Porturas and Taylor, 2021).
An LDA model consists of probabilities for each word belonging to each topic, and probabilities of each document belonging to each topic. LDA makes several assumptions about the corpus. First, it assumes that
each document is a collection of words and disregards the sequence and grammar of the document; this is called the bag-of-words model. Second, LDA assumes that the corpus contains knowledge about many topics k and that the user has already removed words that are either too rare or too common and stopwords, which are words that do not provide any meaningful information and in most situations include pronouns, prepositions, articles, and conjunctions. If words are sparse throughout the corpus, the model will take a long time to search through the corpus finding the rare words. Including words that are too common will generate topics that are too similar to each other and make discerning between them difficult. LDA sees documents as consisting of one or more words, and words can belong to one or more topics with a different probability of belonging to each topic.
The LDA algorithm is iterative, meaning that the user must decide how many times it is run on a corpus. Running it more increases the chance of finding distinct topics, but running LDA is time and computationally intensive. First, each word is randomly assigned a probability for belonging in topic t. The code then goes through each word w belonging to document d and computes the proportion of words in the document d that are assigned to the topic t, the proportion of assignments to topic t over all the documents that contain the word w, and the updated probability of the word w belonging to topic t. Averaging the probabilities of each word belonging to a specific topic gives the topic probabilities for each document.
Methods
LDA works well to “assess trends in the focus of NIH research and address whether the trends are reflective of the changes in epidemiology as compared to other factors such as availability of research tools and technologies, and emerging biomedical knowledge and concepts” (NASEM, 2021). Given a set of 8,470 NIH research grant abstracts related to autoimmune diseases that were funded between 2008 and 2020, topic modeling using LDA was implemented to discern which topics are prevalent within the abstracts.
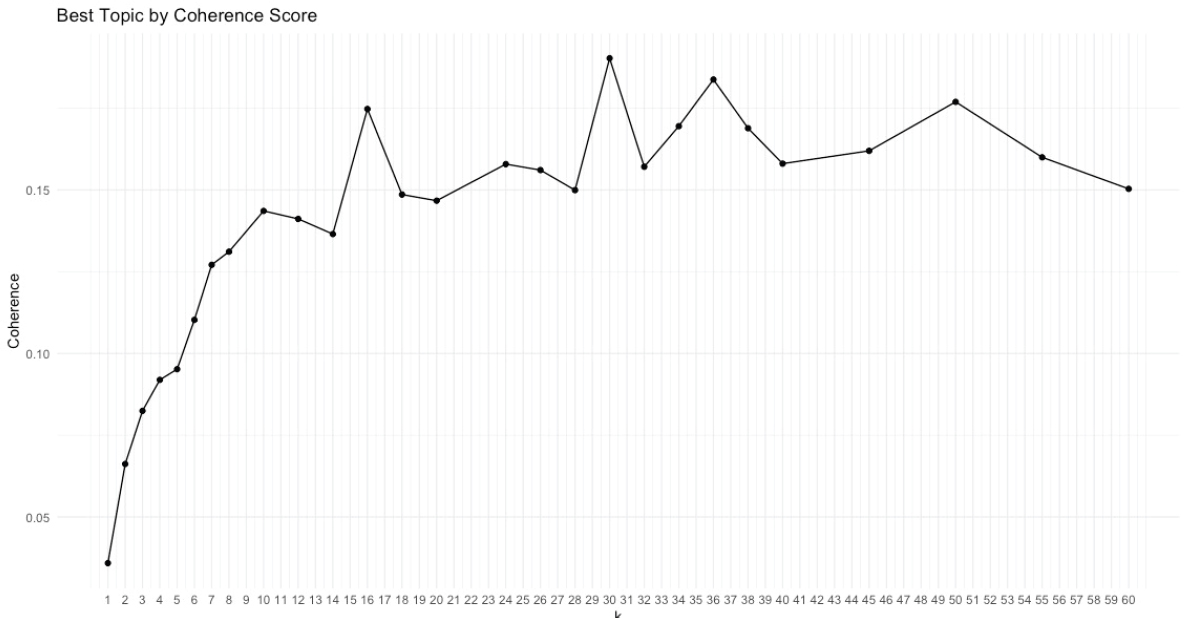
In preparing the grant abstracts for analysis, words that were too common in the abstracts, including the words research and studies, were removed. Because there was no pre-determined value of k to use, coherence scores were calculated to determine an optimal number of topics (Syed and Spruit, 2017). Coherence is a measure of how similar words within a topic are and how distinct topics are from each other. Coherence is calculated on a full LDA model; this means that the LDA algorithm was run 60 times to compare 60 values of k. Figure H-1 is a plot that calculates
the coherence of models fit using various values of k, the number of topics. A higher coherence score implies that the topics generated using k number of topics fit the data well. In consultation with the committee, it was decided to use the model specified with 30 topics.
Once the LDA model was chosen, the names of the 30 topics needed to be determined. LDA does not assign a name to the topics, and it is common practice to look at the top words assigned to each topic to determine what ideas each topic is trying to convey. There is no significance in the numbers associated with each topic or the order of topics given by the model. Figure H-2 shows the top 10 most frequent words assigned to each topic. In consultation with committee members, a name was assigned to each topic. Table H-1 lists the final topic names; some topics were given the same topic name because they were deemed too similar, and their topic assignments were combined in the later plots.
Final Results
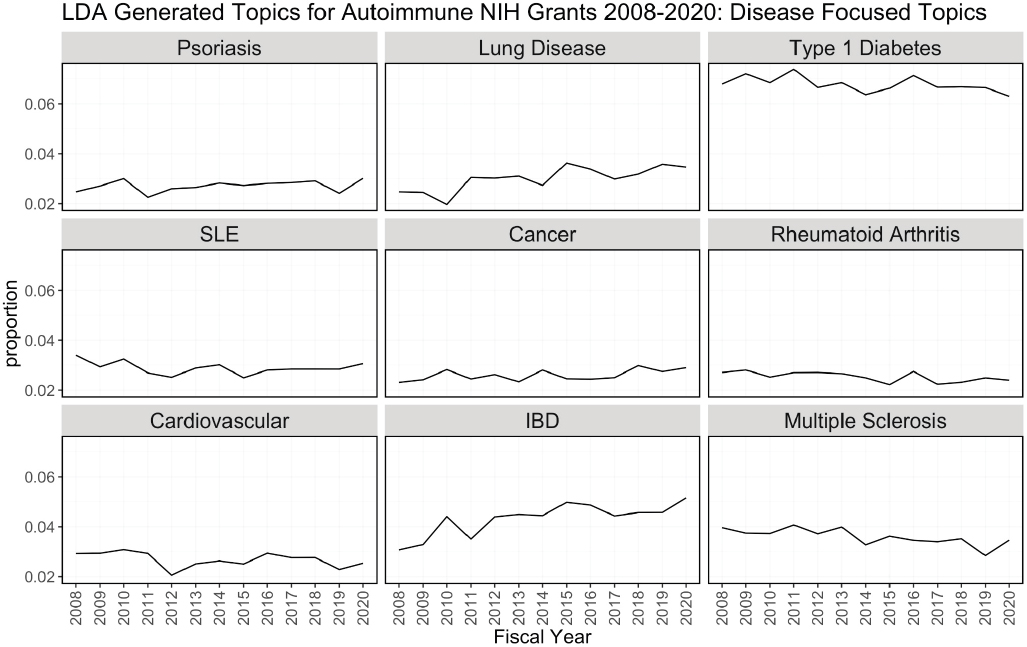
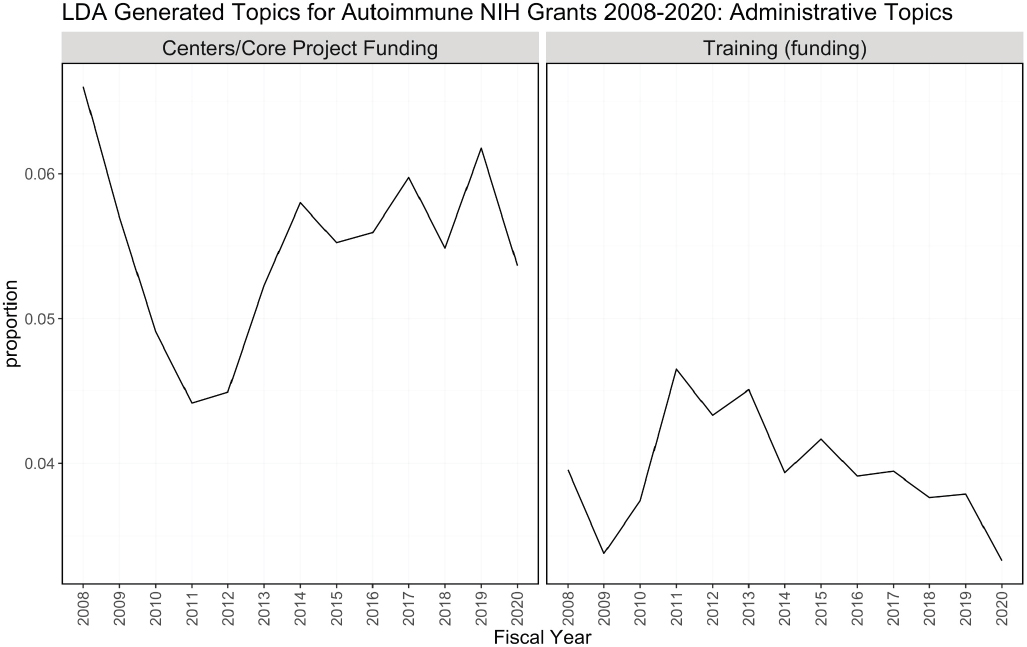
One of the outputs of the LDA model is the theta matrix, which shows the proportion of topics assigned to each abstract. For example, 30 percent of an abstract may be attributed to topic 1, and 70 percent of it may be attributed to topic 2. Theta has N (the number of abstracts) rows and K (the number of topics) columns, and each row in the matrix sums to 1. For each fiscal year, the proportion of each topic attributed to all abstracts funded that year was summed and a separate plot was made for each topic. In other words, the y-axis is the proportion of abstracts funded in a given year that was attributed to that topic. Figure H-3 groups the topics by theme: immune response related, clinical, disease focused, and administrative.
Conclusion
Figure H-3 can be used to determine trends in topics over time using the LDA model. Treatment/therapy, lung disease, diagnostic [tools], imaging, and inflammatory bowel disease have trended upward from 2008 in contrast to animal models, genetics, and pathogenesis, and diabetes is consistently prevalent among topics over time. Cancer, multiple sclerosis, cardiovascular, psoriasis, lung disease, and rheumatoid arthritis are also consistent over time but not as popular as diabetes. It is difficult to explain the spikes in popularity in administrative topics. This could be related to NIH funding policies or other funding pattern changes.
One of the downsides of using LDA for topic modeling is that the topics must be discovered “latently” within the texts; the topics cannot be inputted into the model algorithm. Furthermore, it would have been
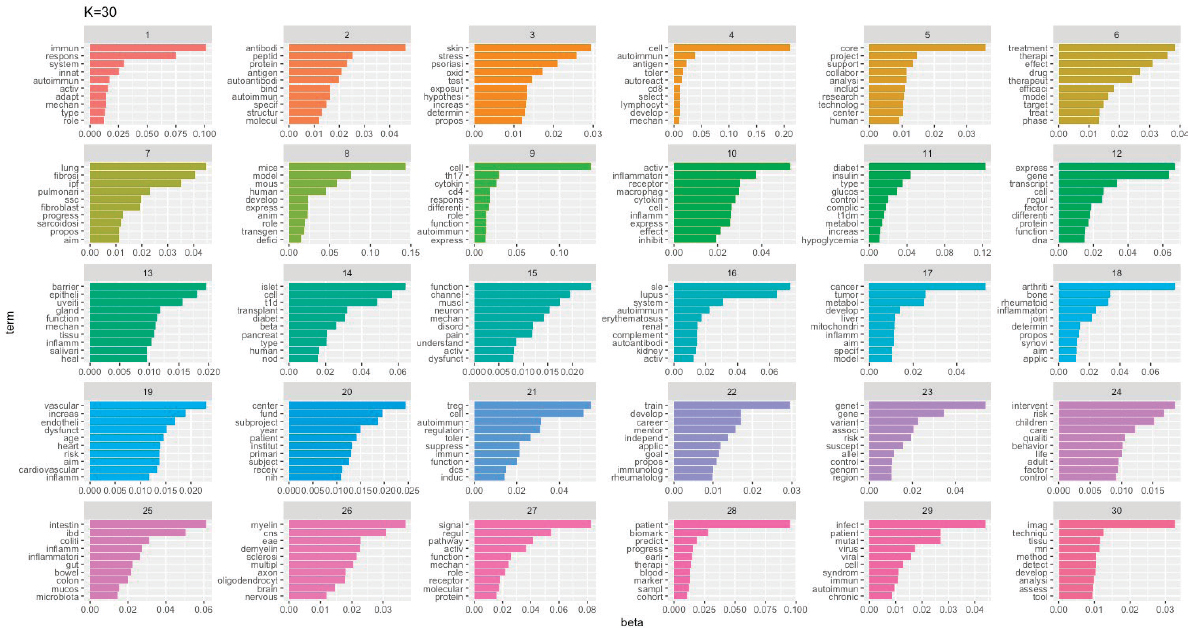
SOURCE: NIH, 2021.
TABLE H-1 LDA Generated Topics for NIH Autoimmune Disease Grants, Fiscal Years 2008–2020
| Topic Number | Topic Name |
|---|---|
| 1 | Immune Response (innate immunity) |
| 2 | Immune Response (adaptive immunity [antibodies]) |
| 3 | Psoriasis |
| 4 | Other (non-antibody) Mechanisms of Adaptive Immunity |
| 5 | Centers/Core Project Funding |
| 6 | Treatment/Therapy |
| 7 | Lung Disease |
| 8 | Animal Model |
| 9 | Adaptive Immunity |
| 10 | Inflammatory Response (innate) |
| 11 | Type 1 Diabetes |
| 12 | Gene Expression |
| 13 | Epithelial Barrier |
| 14 | Type 1 Diabetes |
| 15 | Disease Progression |
| 16 | SLE |
| 17 | Cancer |
| 18 | Rheumatoid Arthritis |
| 19 | Cardiovascular |
| 20 | Centers/Core Project Funding |
| 21 | Adaptive Immunity |
| 22 | Training (funding) |
| 23 | Genetics |
| 24 | Quality of Life |
| 25 | Inflammatory Bowel Disease |
| 26 | Multiple Sclerosis |
| 27 | Pathogenesis |
| 28 | Diagnostic |
| 29 | Virus (infectious etiology) |
| 30 | Imaging |
SOURCE: NIH, 2021.
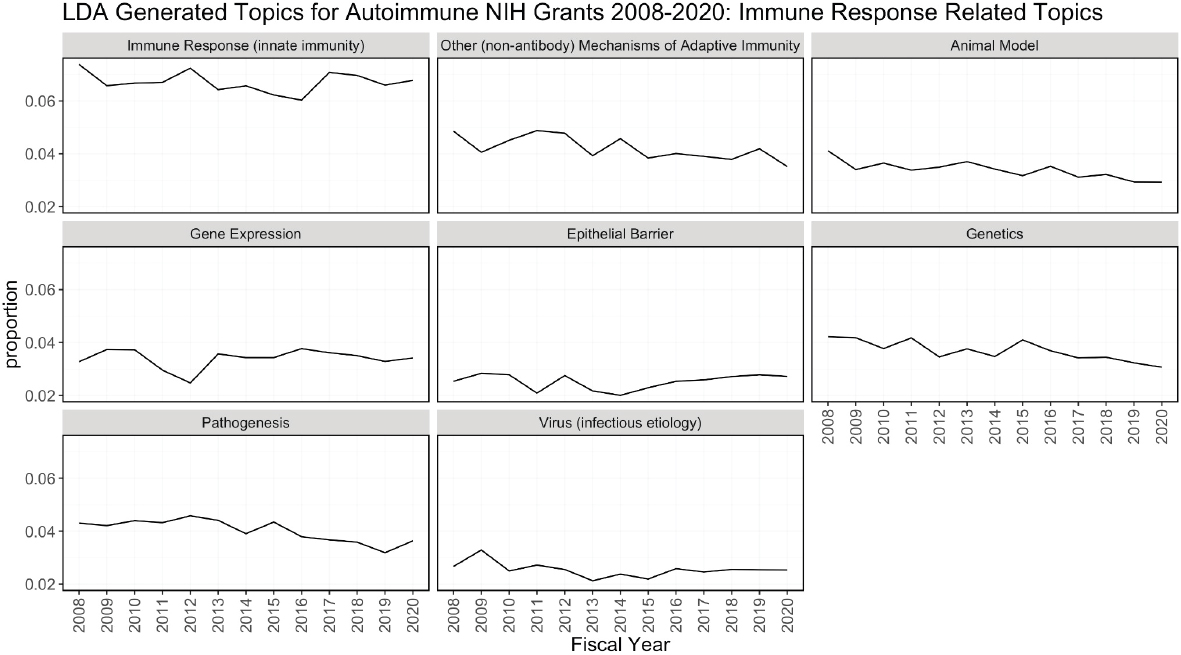
NOTES: FY, fiscal year; LDA, latent dirichlet allocation.
SOURCE: NIH, 2021.
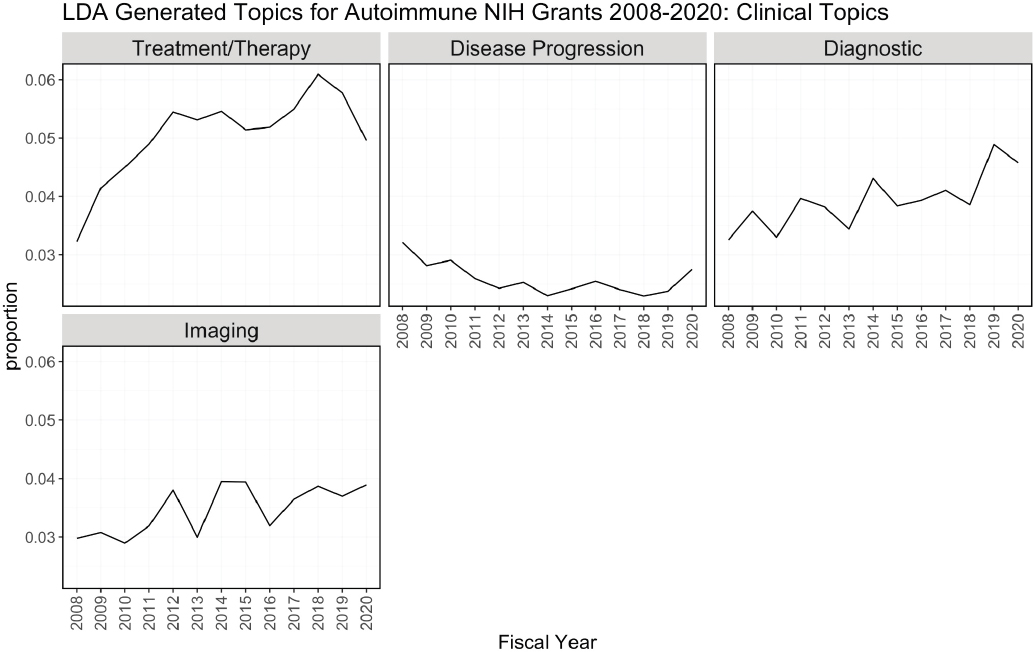
NOTES: FY, fiscal year; LDA, latent dirichlet allocation.
SOURCE: NIH, 2021.
NOTES: FY, fiscal year; LDA, latent dirichlet allocation.
SOURCE: NIH, 2021.
NOTES: FY, fiscal year; LDA, latent dirichlet allocation.
SOURCE: NIH, 2021.
interesting to see how popular specific diseases of interest, including celiac disease, autoimmune thyroid disease (consisting of Hashimoto and Graves’ disease), antiphospholipid syndrome, primary biliary cholangitis, and Sjögren’s disease, are over time. If the LDA model had been allowed to include a greater number of topics as input, the likelihood of seeing smaller, more specific topics would increase. However, increasing the number of topics could also allow the algorithm to detect groupings of words that are not meaningful as it tries to find more topics within the texts. It can be concluded from the omission of specific diseases from the final list of topics that they are not well represented within the abstracts analyzed.
REFERENCES
Bittermann, A., and A. Fischer. 2018. How to identify hot topics in psychology using topic modeling. Zeitschrift für Psychologie 226(1):3–13.
Blei, D. M., A. Y. Ng, and M. I. Jordan. 2003. Latent dirichlet allocation. Journal of Machine Learning Research 3:993–1022.
NASEM (National Academies of Sciences, Engineering, and Medicine). 2021. Assessment of NIH research on autoimmune diseases. https://www.nationalacademies.org/our-work/assessment-of-nih-research-on-autoimmune-diseases#sectionWebFriendly (accessed January 3, 2022).
NIH (National Institutes of Health). 2021. NIH RePORTER database.
Park, J., M. Blume-Kohout, R. Krestel, E. Nalisnick, and P. Smyth. 2016. Analyzing NIH funding patterns over time with statistical text analysis. Association for the Advancement of Artificial Intelligence.
Porturas, T., and R. A. Taylor. 2021. Forty years of emergency medicine research: Uncovering research themes and trends through topic modeling. American Journal of Emergency Medicine 45:213–220.
Syed, S., and M. Spruit. 2017. Full-text or abstract? Examining topic coherence scores using latent dirichlet allocation. Paper read at 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), October 19–21 2017.
This page intentionally left blank.












