
4
Supporting Implementation: Tools, Resources, and Teacher Preparation
To implement high-quality data science education in K–12, tools, resources, and teacher training will be needed. This chapter summarizes the presentations and discussions from two sessions, one on tools and resources, and one on teacher preparation.
TOOLS AND RESOURCES
This workshop session explored the tools and data sets that currently exist or that are needed to support data science learning in K–12 education. Tim Erickson (Epistemological Engineering) moderated the session by posing questions to the panelists, followed by a Q&A discussion with workshop participants.
Unplugged Data Science Learning
When we think about tools for data science education, said Erickson, we usually think about computational tools and computer programs. However, there are also offline tools that can be a useful entry point into data science; Erickson asked panelists to describe their experience with unplugged data science learning. Rolf Biehler (Paderborn University, Germany) shared his experience with the use of data cards in primary and middle school classrooms. Data cards, he explained, are cards that each represent an object and have a list of variables and their values for that object (see Figure 4-1). Students can use these cards as data representations to group, separate, and rearrange data, and these physical operations can be transferred

SOURCE: Presentation by Rolf Biehler, September 13, 2022. See also www.prodabi.de/en and Podworny et al., 2021.
to digital operations, in particular in the software TinkerPlots.1 One use for these cards is to introduce students to decision trees as a machine learning method; this topic is part of the required curriculum in fifth and sixth grade in some states in Germany. Biehler described how the cards are used. There are around 50 cards that each represent a food; the cards contain nutritional information such as calories, fat, and sugar per 100g. Students label the cards with colored paper clips to represent whether the food is rather recommendable (green) or rather not recommendable (red) by using the values of the variables on the cards. Students then sort, separate, or stack the cards by various criteria and see the patterns that develop. This is done for data analysis and visualization purposes. What is a new use is that they can be used to create decision trees. For example, a two-step decision tree could be made that sorts the foods first by fat content and then by sugar content (Figure 4-2). The students decide which splits have a low number of misclassifications. This activity is used as a jumping-off point for a discussion about how machines would construct decision trees automatically, said Bieher, by systematically checking which data splits have the lowest number of misclassifications.
___________________
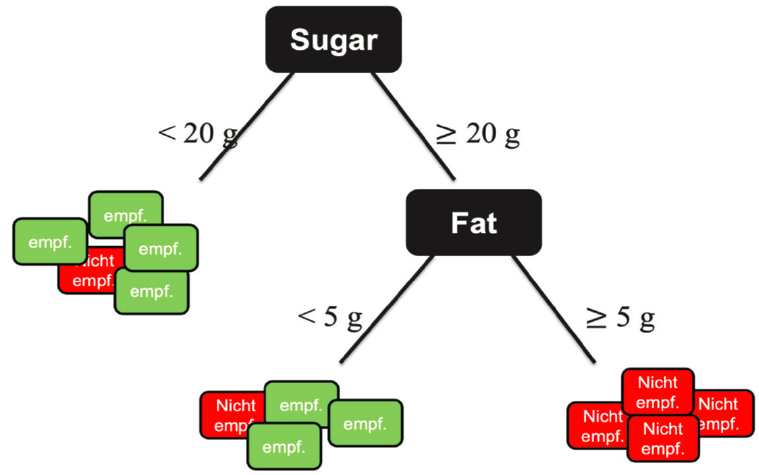
NOTE: “< 20 g” means less than 20 g per 100 g food. Rather recommendable: “empf.”; rather not recommendable: “Nicht empf.” The classification is done by a majority vote in each subgroup. In this case two items out of 13 will be misclassified.
SOURCE: Presentation by Rolf Biehler, September 13, 2022. See also www.prodabi.de/en and Podworny et al., 2021.
V. Lee said that unplugged data science learning can be done even without specialized materials like data cards. Teachers already have tools—such as Post-it Notes, magnets, and whiteboards—that can be used for data visualizations. These low-tech tools present a rich opportunity to talk about computational thinking and algorithms through discussions of where the next data point should go, what choices are being made, and how different choices result in a different visualization. There are a lot of accessible tools that facilitate powerful learning without the need for expensive technology, said V. Lee. Rubin added that another low-tech option for data visualization is using participants’ bodies; for example, participants can make a “graph” by lining up their bodies according to different variables. These visualizations can be mirrored in programs like TinkerPlots or the Common Online Data Analysis Platform (CODAP),2 she said, making for a clear demonstration of the relationship between analog and digital data analysis. V. Lee said that when teachers are asked what technology they are most inclined to use when discussing data in the classroom, they generally are most comfortable
___________________
with spreadsheet programs. There is a need to advocate for the use of other visual tools such as CODAP and TinkerPlots, he said, but also important to consider how to meet teachers where they are most comfortable and with the tools they have in front of them.
Common Data Analysis Tools
Erickson asked panelists to comment on their use of common data analysis tools in the classroom, and the capabilities and challenges of each.
R and RStudio
Programming is a big part of how we engage with data science right now, said V. Lee, and the programming language R and the integrated development environment RStudio are used by professional scientists, analysts, and industry. However, R can be a “little unwieldy for newcomers,” and may require installations that are complicated for school district IT. V. Lee said it is important to consider when and why programming is necessary, and how it might support learning or create a hindrance. At the same time, he said, students shouldn’t be graduating without preparation and experience with tools that are common in the workplace.
Python and Jupyter Notebook
For many computer science educators, said Biehler, R is not an acceptable tool for the classroom; they are looking for programming languages that fit into their world. Python is well received as an attractive programming language that is accessible and interactive, and German computer science programs use Python, along with Jupyter Notebooks, at various levels. In the most elementary level, students use Jupyter Notebooks in a “manual-driven system” that allows for the manual manipulation of certain graphs; Biehler said this is the easiest entrance point. As students advance, educators open cells to show the code and use it to introduce students to simple coding for graphs.
CODAP
Our computer science education always begins with CODAP, said Biehler, which can be used to introduce data exploration in a simple way. Rubin said that CODAP is a “perfect tool” for her work because in short-term courses or out-of-school contexts, it allows students to get up and running with data science. CODAP is web-based, free, and open source, as well as allows drag and drop direct access with “really wonderful” visualization
capabilities. Randy Kochevar (Education Development Center) said he is a “huge fan” of CODAP because it was designed from the ground up as an instructional tool. CODAP gives users a “tangible relationship” with the data, facilitates an understanding of the relationship between “case values and data populations,” and allows users to look at trends in a way that is simple and user-friendly. Kochevar said that he has used CODAP with students as young as fifth grade to visualize Earth science data or biology data. Rubin cautioned, however, that CODAP is not a perfect tool for all uses; for example, reproducibility, generalizability, being able to use something over with a new set of data are really hard to do in CODAP.
Fathom and TinkerPlots
Fathom and TinkerPlots are two other software packages for data exploration, said Chad Dorsey (Concord Consortium). Fathom is appropriate for high schoolers, whereas TinkerPlots is designed for middle school and younger students.
Progression of Tools
Several speakers have alluded to a progression from simple, web-based tools like CODAP to more programming-oriented software, said Erickson; he asked Dorsey to comment on how this progression works. Dorsey explained that the process starts with a fundamental concept that “a data point is a thing.” Data might be viewed in different ways, but the data point never changes or disappears. By foregrounding this concept, students gain the ability to engage with and understand data. Learning tools like CODAP are designed intentionally to highlight these fundamental aspects of data and habits of mind that are necessary for data science education, said Dorsey. The other important component of early data science education, he said, is an “intentional little bit of delight” that entices students to start exploring, to find insights, and to realize that there are multiple insights to be found in data.
Rubin said that progression in data science tools is a research area that is understudied; important questions that need to be answered include the following:
- What does the progression of tools look like?
- How can we help students move from a tool like CODAP to one like R or Python?
- What are the critical changes in the way students think about data or the new skills that they need in order to make the transition?
Considerations for Younger Students
If data science is to be implemented all along the K–12 continuum, said Erickson, there is a need for attention to the younger grades. Kochevar shared his experience working with younger students, saying that developing the habits of mind and fundamental concepts of data at younger ages will facilitate greater gains down the road. However, he noted that there are important considerations when teaching younger students and limits to what can be covered. He gave the example of a project for fourth and fifth graders that used data on rainfall and stream flow. He and his colleagues had their plans reviewed by a teacher, who pointed out that these students hadn’t yet covered decimals. One of the challenges in younger grades is remembering where students are and what they have been exposed to previously, said Kochevar. It is important to work closely with educators in order to make sure that the material is appropriate and relevant. Another challenge, he said, is that K–12 educators do not have much personal experience working with data and doing scientific research. There is a need to meet teachers where they are and provide professional development so that teachers can gain the knowledge, experience, and comfort that they need. Dorsey went on to say that there is a tension between using more professional tools and more accessible tools. If data science education is not accessible to people—either teachers or students—it will put people “off right from the get-go.” Students who succeed with less accessible tools will succeed no matter what, he said, but it is critical to draw all students in with easy-to-use tools that get them “excited about data.”
Diversity, Equity, and Inclusion
V. Lee observed that nearly all of the tools discussed during this session are visualization-intensive and assume a very particular ability. “It behooves us to explore a whole range of ways of data expression using sound, texture, human body,” and other ways to explore data that are not solely visual. Unique approaches like the Dance Data project shared by DesPortes (Chapter 3) are critical for bringing all students into data science, regardless of abilities. Students also vary in terms of their backgrounds, interests, and goals, said V. Lee. It is important to consider how data science education is being connected to the specific technologies that students already are interested in—for example, using TikTok videos as data. While some students want to focus narrowly on traditional data science areas or want to learn to program, all students should get a broad view of all of the tools and opportunities that exist.
Datasets
What does it mean to have an appropriate dataset for students? Rubin said that she likes to use the Goldilocks analogy. Many of the datasets that have been used until recently are like the small chair: they are accessible but small and boring. Large datasets are rich with data but are so complicated that students can get lost in them. Our goal, said Rubin, is to find datasets like the middle chair: just right for the purpose and the user. She shared the criteria that she considers when trying to find the right dataset. First, the number of variables matters. Sometimes this decision is made by the tools that we use, but in general Rubin said that she finds that “a screen’s worth” is the right number of variables because it allows for easily visualization and manipulation. Rubin said that the number of cases is less important than whether students understand the definition of the variables and cases and can relate to possible relationships among variables. A second criterion is whether a dataset has “something there for them to discover”––that is, whether there are interesting patterns or relationships that students can investigate. A third consideration, she said, is whether the format of the dataset is appropriate for the analysis; she gave an example of a wide format compared to a long format for data on three species of shrimp in several pools in the Puerto Rican rainforest and said that in one case it is easy to compare across species and in another format it is not. This issue was discovered through trial-and-error: students were given the datasets and asked to answer questions that were difficult to investigate the way the data were formatted. V. Lee said that another consideration for datasets is whether they are “too tidy and too clean.” Although datasets may require cleaning and simplifying to be usable, students need to be prepared to look at data that are messy. Finding datasets that work for teachers is hard, he said, and is an area that is ripe for progress. Teachers need access to “abundant and continually replenishing datasets that are good for pedagogical purposes.”
Wraparound Needs
Erickson asked Kochevar to discuss the need for wraparound resources that help teachers and students use data science tools. Kochevar said that he began teaching in January 2020, which meant that within a few months, he needed to be able to teach everything remotely and sometimes asynchronously because of the COVID-19 pandemic. To do so, he needed more resources than just the data science tool. He needed a place where students could find the instruction set and could record their work and turn it in, and where he could review the work, evaluate it, and give feedback. As wonderful as these tools are, said Kochevar, there is a need for them to be surrounded by resources and other tools that support student learning
and teacher instruction. There have been efforts made in these areas, but there is a need for further work to develop wraparound resources that are engaging and accessible.
New Tools
Erickson asked panelists what new tool, or new feature of an existing tool, they would like to see in the future. Biehler responded that he would be happy if CODAP could do everything that Fathom can do. Fathom, he explained, supports data exploration as well as activities such as simulation, understanding probability, randomization, and resampling. He said it is important to be able to combine probabilistic simulation with data exploration. Rubin responded that she would be happy if CODAP could do everything that TinkerPlots does, in particularly segmenting distributions with movable lines. Dorsey stated that he would like a tool that can do things that CODAP, Fathom, and TinkerPlots cannot yet do; specifically, there is a need for tools that can deal with spatio-temporal data. This is a burgeoning area for industry and science, and students need to be prepared.
Audience Q&A
Erickson moderated a Q&A session, taking questions from both in-person and virtual workshop participants.
Selection of Tools
Hollylynne Lee (North Carolina State University) asked panelists about selecting tools for various data science education purposes. Specifically, she wondered what characteristics of tools were useful in forming good data habits and good data practices. V. Lee responded that there is a need to think carefully about how different data science tools connect to the kinds of evidence-based discourse in particular fields. For example, one field may value novel visualizations, so it is important to pick a tool that is well suited for that. Another discipline may require quantitative summaries, and other tools may be more appropriate. Tools should be selected according to how well they fit the norms and style of the discipline in which they will be used. Kochevar added that it is key to be explicit about learning objectives, and tools should be chosen that will allow students to focus on those objectives; “don’t put barriers in the way of them doing the thing that you want to have them do,” he said. Biehler agreed and noted that students and teachers often need case studies to demonstrate how to use a tool for a certain type of data exploration. In addition, students need worked examples to
scaffold, for example, a visualization that they can edit, change, and adapt to their own dataset.
Drozda added to the discussion by noting that there are other tools that have not been mentioned at the workshop, including SAS, Tableau, Stata, Sequel, DataClassroom, and Deepnote. He encouraged educational researchers to look into paid tools that might bring value, as well as ways to make paid tools more affordable for K–12 settings.
Disability Inclusion
Davis Johnstone (Data Science 4 Everyone) said that there has not been enough conversation about disability inclusion in data science, particularly in the area of tools. Current tools often use accommodations that do not work well (e.g., screen readers in coding platforms). Dorsey agreed that this is a major challenge and said that while there are people making an effort in this area, it is a complex and difficult issue to solve. In addition, there is a lack of funding, research, and incentives to make progress. Erickson noted that Tuva has been making strides in accessibility, and Rubin added that several researchers are working on data sonification.
Data Literacy to Data Science Spectrum
Much of the discussion in this session has been focused on tools for data science such as investigation of individual data points, graphing, and other technical practices, observed DesPortes. However, in the real world, the focus is more on data literacy—skills and understandings that are applied in everyday life—rather than data science. For example, when people gather information from news sources, they are selecting data sources, deciding what sources to trust, building arguments based on curated data, and making decisions. She asked panelists if there are tools that can help students develop these types of data literacy skills, or if there are innovations being made in this area. Dorsey agreed that data literacy is essential and argued that data literacy cannot be separated from data science; data exploration is a key part of developing these skills and understandings. Biehler gave an example from Germany, in which students discussed news stories about the gender pay gap and then were given the data to explore themselves. The combination of reading the news and exploring the data, he said, gave them a very different view of the news and how the data were transformed into the stories. Rebecca Nugent (Carnegie Mellon University) agreed with DesPortes that we need more tools and resources to support data literacy, and that it is critical to teach both data literacy and data science. She noted that some students “are incredible technical coders and can’t explain anything to anyone.”
TEACHER PREPARATION
The role of teachers has been discussed throughout this workshop, said H. Lee. This session was designed to focus on teachers and their preparation to teach data science. Panelists described the current status of preparation, the skills and knowledge that teachers need to have, and ways to incorporate data science into teacher education and professional learning. H. Lee asked the panelists a series of questions, then moderated a discussion with workshop participants.
Current State of Teacher Preparation
What do teachers already know about data science education, asked H. Lee, and how did they develop their knowledge, skills, and dispositions? Stephanie Casey (Eastern Michigan University) responded that teachers believe in making learning experiences meaningful for students, and they can see that incorporating data investigations about topics that are meaningful to students is a powerful way to do this. They know these things, she said, based on their own educational experiences, the pedagogy classes they have taken, and their own teaching experiences. Many teachers are already using data in their classes, said Joshua Rosenberg (University of Tennessee, Knoxville). A survey found that 80 percent of K–12 science teachers already use student-collected data, and teachers also use primary source data and curated data. They work with data of varying sizes and use a variety of tools to support this work. Only a very small percentage of teachers (3.9%) report being not interested in professional development related to working with data. However, said Rosenberg, there are opportunities to do more. These opportunities include using tools other than spreadsheets, expanding beyond visualizing data and toward modeling data, and using data as a bridge between math and science classes. On the last point, Rosenberg said that while it takes time and effort to co-develop materials that are both mathematically and scientifically meaningful, data science is an effective way to serve the learning objectives of both math and science. Leticia Perez (WestEd) said that when it comes to data science, science teachers “don’t need to buy in.” Once teachers are introduced to tools and techniques they can use to bring data to life in the classroom, they are excited and willing. The key, said Perez, is to support natural entry points and areas in which data science connects to the existing goals and learning objectives of the class.
Vision for Teacher Preparation
Given the current state, H. Lee asked panelists to envision what teacher preparation should look like, and to identify the skills and practices teachers need to effectively teach data science. Anna Bargagliotti (Loyola Marymount University) began by noting that K–12 data science looks different than undergraduate or professional data science; the goal is to develop some level of data acumen in all students. Bargagliotti said that the framework of the Pre-K–12 Guidelines for Assessment and Instruction in Statistics Education II (GAISE II)3 is relevant to this goal and highlighted a few specifics. First, GAISE II emphasizes the importance of working with multiple variables and multivariate thinking as early as kindergarten, she said. Second, the framework promotes the concept that data science is a process that can be guided by “questioning, questioning, questioning” throughout the data cycle. When focusing on teacher preparation, said Bargagliotti, it is important to build these skills and give teachers these experiences, with data that are relevant to them. She noted that just as data science education needs to be engaging and relevant for students, the same is true for teachers. There are opportunities in all disciplines to find rich and interesting data for teachers to manipulate, investigate, and interrogate.
Anne Leftwich (Indiana University Bloomington) said that in her experience working with teachers, many do not believe that data science, computer science, or technology apply to them or their classes. For example, a primary school teacher might say that data science is more appropriate for secondary school, while a social studies teacher might say that data science is more appropriate for a science or math class. Due to this challenge, Leftwich agreed with Bargagliotti that teacher preparation must be relevant to teachers’ content area and grade level and must show examples that they can achieve. For example, teacher preparation for elementary teachers can emphasize how data science can help young students process the world around them and lead to a stronger understanding of math and problem-solving practices, whereas teacher preparation for physical education teachers can emphasize how data science can help students improve their understanding of their own health. This can be accomplished all in one class, said Leftwich, but it is critical to have accessible tools, appropriate datasets, and subject-specific examples that are relevant to each area.
Before teachers can teach data science, said Gemma Mojica (North Carolina State University), they need experience engaging with data. They need to engage in the entire process, from asking questions, to collecting or considering data, to exploring the data with tools, and to using the data to answer questions and communicate what they have found. Speakers at the
___________________
3https://www.amstat.org/asa/files/pdfs/GAISE/GAISEIIPreK-12_Full.pdf
workshop have discussed the need for students to be “awash in data,” to explore complex and messy datasets, and to learn how to use data science tools, said Mojica. These are the same skills and experiences that teachers need to have themselves before they can envision how to create a learning environment that engages students in these practices.
Perez added that part of teacher preparation is creating awareness around where and how data science can be brought to the classroom. She noted that domains are often siloed in elementary school; for example, students are looking at bar graphs in math class and six months later are looking at the same types of data visualizations in a science unit on the weather. This is a missed opportunity, said Perez, and there is a need to help teachers become aware of the potential for alignment and synergy between domains.
Preservice Teacher Education
H. Lee asked panelists to comment on how the pipeline of new teachers can be prepared to teach data science by participating in preservice teacher education. Casey said that there are three key areas in which change is necessary to effectively train the next generation of teachers. First, teacher educators—including content course teachers, methods course teachers, and mentor teachers—need professional development. Second, preservice teachers need meaningful clinical experiences involving the teaching of data science. Casey noted that it is extremely challenging to find placements with a mentor teacher who can help develop the preservice teacher’s skills, knowledge, and disposition in data science, let alone in a school that includes data science in the curriculum. Third, teacher preparation standards largely drive what happens in teacher preparation programs, and teachers take assessments at the end of their program to demonstrate their competency in teaching. If data science is not included in the standards or the assessments, it will remain challenging to incorporate it in preservice education. Bargagliotti agreed that accreditation and licensure standards are a barrier to training preservice teachers in data science education. She put out a “call to action” to workshop participants who are in math departments to do their best to build data science and statistics curriculum into preservice teaching curricula so that teachers begin to see the value in data science and demand professional development in this area. However, to make progress, said Bargagliotti, “we are at a point” where there is a need to push for accreditation standards to include statistics and data science.
In-service Teacher Education
H. Lee asked, once teachers are licensed and in the classroom, what are some creative ways that practicing teachers can gain skills and knowledge
about data science education? Mojica observed that there are a number of different models that can be used to engage teachers in professional learning. There is evidence that supports very intense work at a local level with small groups of teachers. However, she said, some teachers may be the only teacher of data or statistics in the entire district, or may be a long distance from colleagues, so other models are needed. Massive open online courses (MOOCs) have been created for teacher educators, and there is evidence that these courses had a positive impact on teachers’ confidence, beliefs, and practices. There is a need to consider these types of alternate models for professional development instead of pursuing a one-size-fits-all approach, said Mojica. There are opportunities for hybrid approaches that blend online learning experiences with face-to-face engagement, and for using other platforms and spaces to personalize learning for teachers in a way that is accessible and meets their needs. Perez said that in order to engage teachers in in-service preparation for data science education, there is a need to reach out and communicate with stakeholders such as administrators and district leadership. Intentional conversations with leaders at different levels, she said, will help them understand the connections between data science and educational standards. Further, conversations and professional development need to happen in a transdisciplinary space and need to include a broad group of stakeholders.
Research on Teacher Preparation
H. Lee asked panelists to describe the existing research on teacher preparation for data science education and to identify areas where there are research gaps. One thing we know about teacher learning, said Leftwich, is that teachers want to find ways to make an impact on their students and their learning. If teachers believe that data science is important and it will help their students engage in and learn the subject matter, teachers will want to incorporate it into their classroom. She emphasized that while conversations about preparation tend to focus on the knowledge that teachers need, it is just as important to improve their attitude and self-efficacy. Particularly at the elementary level, said Leftwich, teachers can be hesitant about their ability to teach technology or data science; it is critical to build confidence and provide them with tools and models that allow them to easily move ideas into practice.
Rosenberg said that there are research findings from other fields that can illuminate our understanding of how to best prepare teachers for data science education: for example, teachers do well when they have a chance to try activities with supportive peers, when they have sustained opportunities to receive feedback from peers or a coach, and when they can adapt curriculum materials. H. Lee shared other findings from research on teacher
learning. First, teachers learn best when the subject is connected to their practice and their goals for their students. Second, teachers care about student learning, so it can be useful to have examples that show what is possible and how an activity might look in the classroom. Third, said H. Lee, research shows that teachers find frameworks “incredibly useful.” Professional learning is most successful when teachers can situate their learning within a framework and can see how their professional learning goals and progress fit within the framework. H. Lee encouraged those who design teacher professional learning to make the underlying framework explicit to the teachers rather than keeping the design at the design table.
Challenges and Barriers
H. Lee asked, what are the challenges and systematic barriers that need to be addressed in order to make progress in teacher learning for data science? Casey focused on one specific aspect of the educational system that is creating barriers for data science: college admissions. She noted that colleges have long privileged calculus when making decisions about admissions and that students need calculus on their transcript to be competitive whether their program of study in college requires calculus. This is a big barrier, said Casey. In addition, colleges also look closely at how many AP classes a prospective student has taken, and there is currently no AP data science class. Although there is an Advanced Placement (AP) statistics class, it is “certainly not the type of data science we’ve been talking about at this workshop.” Perez added that we need to expand the conversation and think about administrators and school site district leadership to help them understand connections to the standards.
Perez said that another challenge is a lack of stable descriptions of concepts such as data acumen, data habits of mind, and data fluency. There is a need for shared understanding so that teachers can communicate across disciplines and projects. Rosenberg agreed that clarity is needed on what data science is; for example, teachers may want to do more than data visualization but aren’t sure what the next step is. Leftwich said that in order to move data science forward, there is a need for more readily accessible and free software that allows students and teachers to use and manipulate data easily. Particularly at the elementary level, there is a need for user-friendly tools that allow students to upload their own data and manipulate the data to tell a story.
Audience Q&A
Existing Courses
Strode asked panelists about the specific courses that are being offered to preservice teachers in universities around the country and in which departments they are situated. Mojica said that there is a class at North Carolina State University that is in both the College of Education and the Department of Statistics, and it focuses on the teaching and learning of statistics. Creating a class like this requires talking to colleagues in other departments and being creative, she said, but this type of collaboration is necessary for a transdisciplinary subject like data science. Bargagliotti said that she has heard from several educators who are teaching classes in colleges to future teachers based on her book Statistics and Data Science for Teachers; these classes are situated in statistics, education, and math departments. Casey said that she is aware of data science being integrated into a number of different courses, including classes on statistics, teaching with technology, social context of education, and education equity. In some of these classes, data science is a “grain-sized” module that is integrated, and in others, data are used as an integral part of learning throughout. For example, preservice teachers may use tools like CODAP to investigate real data (e.g., data on inequality in education). Research has shown that these experiences are meaningful and can improve teachers’ confidence and knowledge, said Mojica. The particular classes and departments where data science is taught can vary widely depending on programs and interest of faculty members, said Leftwich. Ultimately, if teacher educators buy in to the importance of data science and understand what it can look like in the classroom, data science can be integrated in multiple ways and areas, she said.
Shifting Course Requirements
Given the discussion earlier in the session about how requirements for teacher education largely drive the curriculum, Melville asked panelists if and how these requirements might be changed to require courses in data science education. “Is that something worth making a noise about,” she asked, or is it best to continue on the path to infusing it into existing courses? Melville noted that in her personal experience, required courses outside her subject matter felt contrived and like tasks that just needed to be checked off her list. What kind of work is being done to shift that perspective and to embrace and value transdisciplinary practices? H. Lee said that in North Carolina, the state requires secondary teachers to take a computing course. Historically, North Carolina State University required it
to be a course in Java programming, but recently it has opened up to allow courses on R or Python. Sometimes there are broad recommendations at the state level, said H. Lee, that can be creatively interpreted by the university. Rosenberg added that he would like to learn from the computing education world how it has addressed the issue of state requirements to see if lessons could be applied to data science education. Perez noted that there is a critical teacher shortage right now, and while this is an unfortunate situation, it opens up potential opportunities. She explained that nontraditional routes toward licensure have more flexibility than traditional teacher preparation programs and requirements, and there may be opportunities to infuse data science in these spaces. Rosenberg agreed and added that attention should be paid to teachers who are being prepared outside of teacher education programs.
















