
IDR Team Summary 3
Develop and validate new methods for detecting and classifying meaningful changes between two images taken at different times or within temporal sequences of images.
CHALLENGE SUMMARY
If a picture is worth a thousand words, multiple pictures of the same object are often worth a million. By comparing PET/CT images taken before and after chemotherapy or radiation therapy, a physician can often tell with high certainty whether a tumor is responding to the therapy. A military analyst looking at synthetic-aperture radar (SAR) images of an airfield can discern that a new type of plane has been deployed. A set of Landsat images taken weeks apart can be used to determine if a crop is flourishing or withering. An astronomer comparing serial images may discover a supernova or a gamma-ray burst.
Yet not all change is meaningful. Two digital images of the same object are never identical, on a pixel-by-pixel basis. The ambient lighting may change between aerial photographs; the patient might lose weight or lie on the scanner bed in a different position, or the crop images might be taken at different times after irrigation. Technical factors can also change: the magnification might be slightly different between two aerial images, or a different X-ray tube voltage or amount of contrast agent might have been used for two different CT images. These kinds of change are easily detected simply by subtracting two images, but the resulting difference image could still convey no meaningful information about the important changes for which the image are being compared. Focus is needed on change and how best to interpret change.
Current approaches to change detection are surveyed in the references below. Radke, for example, describes many sophisticated ways of
normalizing images so that trivial changes in lighting or technical factors will not be called a change, and he introduces advanced concepts from statistical modeling and hypothesis testing; yet he stops short of application-specific “change understanding,” his term for classifying changes as meaningful to the end user.
There is a strong need for developing rigorous methods not only for detecting changes between images but also for using them to extract meaningful information about the objects being imaged. One approach is the use of statistical decision theory, where the statistical properties of images of normally evolving spatiotemporal objects are modeled, and “meaningful” is defined in terms of deviations from these normal models. Alternatively, specific statistical models can also be devised for various classes of interesting changes, and in this case “meaningful” can be defined in terms of classification accuracy or costs assigned to misclassification.
A different approach is to recognize key components of the evolving images and their spatiotemporal relation to one another. This semantic approach is similar in spirit to what the human visual and cognitive system does in analyzing scenes containing well-delineated, temporally varying object components, but computer implementations can take into account the noise and resolution characteristics of the images.
For statistical or semantic approaches, or any synthesis of the two, there is a pressing need for assessing the efficacy of the change detection and analysis methods in terms of the specific task for which the images were produced. This assessment could then be used to optimize both the algorithms themselves and the imaging systems that acquire the spatiotemporal data.
KEY QUESTIONS
-
What fields of application, within the expertise of the participants, require careful discrimination between meaningful and trivial changes? In each, what are the characteristics of meaningful change?
-
In each field identified, what databases of imagery or other data can be used to build models of meaningful changes?
-
Can fully autonomous computer algorithms compete with a human analyst looking for meaningful changes? How can the computer enhance the capabilities of the expert human? By analogy to computer-aided detection (CAD) or diagnosis (CADx) in medicine, can computer-aided change detection (CACD) be applied in the applications identified?
-
What is the relative role of semantic analysis and statistical analysis in understanding changes?
-
What modifications in the basic paradigm of task-based assessment of image quality are needed for tasks that involve temporal changes?
READING
Coppin P and Bauer M. Digital change detection in forest ecosystems with remote sensing imagery. Remote Sens Rev 1996;13:207-34. Accessed online June 15, 2010.
Radke RJ, Andra S, Al-Kofahi O, and Roysam B. Image change detection algorithms: A systematic survey. IEEE Transactions on Image Processing 2005;14(3):294-307. Accessed online June 15, 2010.
Singh A. Digital change detection using remotely sensed data (Review article). Int J Remote Sensing 1989;10(6):989-1003. Accessed online June 15, 2010.
Because of the popularity of this topic, three groups explored this subject. Please be sure to review the second and third write-ups, which immediately follow this one.
IDR TEAM MEMBERS—GROUP A
-
Mark Bathe, Massachusetts Institute of Technology
-
Felice C. Frankel, Harvard Medical School
-
Ana Kasirer-Friede, University of California, San Diego
-
K. J. Ray Liu, University of Maryland
-
Joseph A. O’Sullivan, Washington University
-
Robert B. Pless, Washington University
-
Jerilyn A. Timlin, Sandia National Laboratories
-
Derek K. Toomre, Yale University
-
Paul S. Weiss, University of California, Los Angeles
-
Jessika Walsten, University of Southern California
IDR TEAM SUMMARY—GROUP A
Jessika Walsten, NAKFI Science Writing Scholar, University of Southern California
IDR team 3A wrestled with the problem of defining meaningful changes among images. These changes can be between two images or in a series of images over a period of time.
Analyzing images to detect changes from one to another is not as simple or straightforward as many of us think. Even when looking at two still images side by side it can be hard to differentiate what is meaningful from what is not. For example, two photos taken of the same section of forest at different times of day will have variations in light that may distort the meaningful changes, exaggerating or minimizing them. Some tools do exist, such as principal component analysis (PCA), that can help normalize the images, correcting for any background noise or variation. But the use of any analysis technique, whether it’s PCA or model based, will vary depending on what the researcher is looking for. There is not a universal tool that can be applied across disciplines. Likewise, each researcher will run into different problems during the analysis of data from different imaging technologies. To illustrate, a biologist looking at vesicle fusion within a cell may run into issues with the image resolution produced by the instrument he or she uses or instrument vibrations. On the other hand, an analyst looking at color change in leaves may run into problems with the intensity of sunlight or wind.
Because there are so many variables at play when images are analyzed (e.g., instrumentation, light, vibration, resolution, etc.), the IDR team thought it necessary to somewhat narrow the scope of its original challenge, which was to: Develop and validate new methods for detecting and classifying meaningful changes between two images taken at different times or within temporal sequences of images. The group focused instead on two aspects of this statement, altering it to read as follows: Develop and validate new methods for detecting and classifying meaningful trends within temporal sequences of images.
From these temporal sequences, trends need to be detected from the data, not just changes from one image to another, so that researchers can model what is happening over time and then use those models to predict the outcomes of future experiments. These trends are more meaningful overall than just defining what changed between two images.
Exploring Terms
It’s easy to get hung up on terms, but sometimes it is helpful and necessary to define terminology. In the case of the group’s redefined statement, three ideas need further vetting.
First, the images that need analysis can come in a variety of forms. They can be still photos, a handful of snapshots from video surveillance cameras,
or hundreds of hours of video. These images can be two-dimensional, three-dimensional, spectral, four-dimensional (three-dimensional plus spectral), or even five-dimensional (four-dimensional plus time).
With all of these different types of images, it can be complicated trying to assess them, especially when all of the variables are taken into account.
The second word that needs some explanation is meaning. What does it mean to be meaningful? The group determined there are two kinds of meaningful processes: exploratory and explanatory. Exploratory processes lead to discovery or surprise. In this case, a researcher may not go into an experiment knowing what he or she is looking for and is surprised by the finding. Explanatory processes are the analyses in which a researcher will attempt to make sense of data, reducing pages and pages of numbers to something meaningful.
Meaningfulness can be quantified in a number of ways. Specifically, the IDR team talked about information theory entropy measurements where entropy, a measure of randomness, is compared with the probability an event will occur. This relationship is inversely proportional. For example, if a vesicle fusion event is likely to occur many times during a short period of time, the chance that something random will happen (entropy) is much lower. Quantification of meaning can also occur through measurements of error in the data. Recognizing error can be difficult. Oftentimes, it involves reanalysis of the data using trial and error to find the information that is important to the experiment.
The word trend is similarly ambiguous, meaning different things to different people. In general, however, the team defined a trend as meaningful changes over time. Trends are evolving processes that have directionality. There is usually a growth and collapse phase in a trend, but a trend may not necessarily go in one direction (i.e., it can go up and down multiple times). By measuring a trend a researcher can say something more about the process, possibly using the trend as a predictive model.
Trends can be found in birth or death rates, morphology, structure, topology, particle motion, diffusion, flow, drift pattern, spectral, background, noise, intensivity, reflectivity, transmissivity, density, and statistics (non-visible).
Team 3A noted that trends can be broken down into categories. These categories include monotonic, linear, periodic, random walk, or impulsive/frequency. The data from an experiment usually doesn’t nicely fit into one trend category. Rather, the data is a combination of multiple trend categories. Tools exist to decompose a temporal sequence of images into trends,
but those tools only analyze data from one category. So, the challenge then is to find methods to decompose temporal sequences of images that have contributions from multiple categories of trends.
Also, some of these trends may be more or less meaningful than others, and there may be trends that compete within an application, distracting the researcher from what he or she is looking for. It can be difficult to extract the meaningful trends from the non-meaningful trends. For example, the patterns of vibration in a video of cell vesicle fusion are not related to the vesicle or even the cell. The vibrations come from the instrument used to capture the video. But background noise, like instrument vibrations, are not always as easy to detect.
How Do You Find Trends?
Both explanatory and exploratory processes are used in experiments to find trends. A researcher first goes into the exploratory phase. A scientist may go into the experiment knowing what he or she is looking for. But that is not necessarily the case. This exploratory phase leads to discovery, which then helps the researcher formulate or reformulate hypotheses. That can motivate the experiments. The researcher then moves into the explanatory phase to attempt to support or invalidate the hypotheses.
Researchers can use both factor analysis and dynamical models to analyze their results. Factor analysis looks at the raw numbers and finds trends in the numbers. For example, if a video of cell vesicle fusion events is analyzed via a statistical program, like MATLAB, the program will average all of the images in the video into a composite image. The researcher can then look at a specific part of the video, creating an image that represents that parameter. That video is then compared at certain intervals to the average image, and a graph that shows how far the video is at any point from the composite image is produced. This graph will show a trend in the information that can indicate a specific event, like vesicle fusion, did or did not occur. Depending on the parameters used, the trends produced may or may not be useful. So other methods could be employed to analyze the data, such as dynamic models that use time as a comparison to certain points.
Mathematical analysis can be used to find trends in intensity or frequency of events in a temporal series of images. In the vesicle video, a flash of light represents a vesicle fusion event, a cellular mechanism important for cell movement and the transportation of cellular material. These flashes, or events, occur in varying speeds and intensities. A researcher could ana-
lyze the flash intensities or speeds to see what the trends are. Are vesicles fusing more quickly at a certain point? More slowly? Why? The findings could then be used to predict what would happen in further cell vesicle fusion experiments, completing the feedback loop. The importance of these predictive models may not be as apparent in the vesicle fusion example. Nevertheless, cell biologists may find these types of trends meaningful in future research.
If these types of models are applied to tumor growth, for example, a researcher may be able to predict the behavior of a tumor for certain locations in the body. In addition, finding these trends may help researchers better understand ways to redesign experiments.
Future Areas of Development
Many challenges are encountered during the experimental process. These include massive datasets, limitations due to instrumentation, resolution in time, space, and spectrum, trends on multiple time scales, data in multiple dimensions, and representation and communication of results. Overcoming these challenges will help lead to future progress.
Team 3C sees these future developments as falling into three types. First, researchers could use tools in new ways, such as PCA analysis to preprocess a video. Tools could be used in post-processing and removing unwanted noise in an image. This could also mean using tools or theories in disparate fields to help analyze the data or solve problems collaboratively. One example of this is pattern theory, a mathematical theory that tries to explain changes in images using combinations of a few fundamental operations. Pattern theory does not account for series of images over time. Other limitations of the theory also need to be addressed to develop more mature and implementable versions of pattern theory that can be applied to scientific image analysis.
Second, nonlinear representations of data need to be developed. Current methods of factor analysis are linear, accounting poorly for motion. In scans that involve deformation by movement, such as distortions in images from PET scans from breathing or objects on surfaces that are being deformed, mathematical models need to be built to account for the deformations.
The third and final recommendation for development was the use of iterative feedback for prioritized development of mathematical tools, instrumentation, and experimental design. This means using experimental
analysis to reassess the original problem. For example, new instruments could be developed based on what happens during a particular experiment, and trends that are found could be used for predictive models.
If researchers develop these areas, they will better be able to find meaningful trends in images and find ways to improve their data analysis from those images.
IDR TEAM MEMBERS—GROUP B
-
Daniel F. Keefe, University of Minnesota
-
Lincoln J. Lauhon, Northwestern University
-
Mohammad H. Mahoor, University of Denver
-
Giovanni Marchisio, DigitalGlobe
-
Emmanuel G. Reynaud, University College Dublin
-
James E. Rhoads, Arizona State University
-
Bernice E. Rogowitz, University of Texas, Austin
-
Demetri Terzopoulos, University of California, Los Angeles
-
Rene Vidal, Johns Hopkins University
-
Emily Ruppel, Massachusetts Institute of Technology
IDR TEAM SUMMARY—GROUP B
Emily Ruppel, NAKFI Science Writing Scholar,
Massachusetts Institute of Technology
Current Imaging Methods: Not Always a Clear Picture
Imagine walking into an empty room, turning on the light, and taking a picture of a chair. Now imagine walking into that same room a week later, not turning on the light, and taking a picture of the chair using the flash on your camera.
In the two images, the chair would look completely different. But how can we tell whether the chair or the imaging actually changed between picture one and picture two? Are the differences significant, or not?
Let’s assume, for instance, that the chair did change (perhaps the room flooded and the wood warped slightly out of shape). If one wants to use those two pictures, the first taken before the flood, and the other taken after the flood, to track the flood’s effect requires knowing what is also different about the conditions of the lighting, the camera apparatus, or perhaps
the stability of the room, itself. Because there are many possible sources of interference, and they cannot be isolated, the problem has no easy solution.
Now imagine a more probable situation. Your skull is being imaged to look at a tumor. Over a period of weeks or years, your neurologist is trying to determine whether the tumor is changing in any significant way. It should be possible to know by looking carefully at fMRI, PET, and/or CT scans, the widely trusted tools of neuroscience, without having to resort to surgery. Is it that simple?
This is exactly the problem that IDR team 3B tackled at this year’s National Academies Keck Futures Initiative Conference on Imaging Science. If anything about the calibration of the MRI device changes, if there is some methodological change between two brain imaging sessions, the resulting data could suggest changes that have nothing to do with whether the tumor is shrinking or growing or spreading.
Meaningful detection of change is not just a problem in neurology—scientists in many fields are eager to establish better methods for capturing and determining significant change based on highly reliable imaging. Forestry experts need to know whether satellite or aerial pictures can be trusted to accurately compare canopy images over time. Likewise, astronomers must use still pictures to observe ever-changing celestial phenomena. Oceanographers, military surveyors, even farmers could benefit from advances in imaging science.
Mining for Meaning in Images
By modeling human behavior with computer programming—that is, encoding a process or calculation that humans used to do by hand into something the computer can do for them—computer scientists improve productivity and free up time and minds for solving other problems. If the same solution could be applied to imaging science, it would be enormously helpful for those scientists whose complex pictures, videos, and visual models must be painstakingly deciphered for useful analysis. IDR team 3B sees a key opportunity for improvement as a sharpening of imaging language. For instance, most people think of an image as an array of pixels, but team 3B’s definition includes radiographs, 3-D graphics, even nonvisual media like audition and haptics. By specifying the meaning of the words scientists use to identify key features in an image set, they increase their chances of successfully teaching others to identify meaningful change and develop computer systems unique to their problems.
In the introductory example, the obvious subject of interest is the chair, and the obscuring factors are lighting, noise, and equipment. But there are many fields of science in which the lighting, itself, could be the subject that needs measuring. If that were the case, shadows on the chair would provide a way to detect lighting change.
In as wide and varied a field as imaging science, the best computer programmer is unlikely to come up with one solution that addresses challenges of comparing visual data in medicine, astronomy, and environmental science. With no “fix-all” that, when reduced to computation, could help determine meaningful change in every situation, IDR team 3B focused on developing a model that scientists in their respective fields can use to solve their own imaging problems, using creative algorithms where necessary and/or possible.
The Man Machine
While the vertical flow of this model focuses on the relationship between humans and their equipment, the horizontal arrows point to the heart of the matter: the relationship between humans and how they can use representations to help a computer “see” their data. Without meaningful
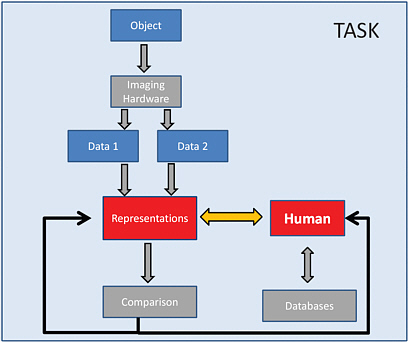
FIGURE 1.
representation, scientists continue to have to work from raw data, spending time deciphering what’s most important in small and large datasets. By creating an algorithm that could do this step for them, and using the creativity inherent in human beings to continually redefine representation, scientists in many fields could save a lot of time.
The thin arrows that close the feedback loop from Comparison back to Human and Representation is part of the redefinition step. New methods will obviously require evaluation, and that evaluation will be used to tweak the representation in question.
The IDR team’s model is dependent upon the human element in computer science—for instance, instead of letting the machine take over, you, the scientist, know your imaging problem best. You know what you want to see, and what you don’t want to see. If humans become active participants in not only evaluating the effectiveness of their respective systems, but also reimagining the computers that are often merely their tools, they open up possibilities for creative computerization and previously unseen solutions.
The best example for how to value human creativity in this particular kind of problem solving comes from a rather surprising source: the unfolding of our own understanding.
Data Dreaming
One of the team members, years ago, had a dream. A dream about clouds. Although most scientists would not consider the whirring of one’s subconscious a proper tool for problem solving, this particular dream cleared the air, if you will, of a seemingly impenetrable problem.
The team member needed to count clouds. The satellite images he was working with needed to be evaluated for clarity. For instance: was the milky character of the picture due to cloud cover, or was it snow on the ground?
In his dream, the team member saw the clouds in a paralax effect. (Paralax refers to how movement alters your perception of your surroundings. For instance, when you drive a car, the things that are close to you shift out of your vision at a different rate than things in the far background.)
Because the satellite was not just taking one picture, but five quick-succession snapshots, the dreamer realized that instead of looking at the combined images, cleaving those snapshots from one another and comparing the edges of clouds as the satellite moved was one way to determine how many clouds there were.
By applying this idea to his algorithm, he solved the puzzle in a creative way, and was able to turn his attention to other things.
Team 3B thus encourages continual participation by the human in the model, because by abandoning the computer to its work, a scientist will also abandon the possibility for improving and increasing the volume of work a computer can do. Research into the methods that humans use to understand data, and improving the relationship of all research fields with computer scientists in several disciplines will be a big step toward improvements in imaging science.
Although such a vision is not an entirely new idea (its been a big move in the computer science world since around 2005), IDR team 3B thinks that its introduction to and integration of all methods of imaging will help set the foundation to “begin building a new generation in human/computer interaction, which will enable us to envision a new era of understanding in the representation and analysis of complex images.”
IDR TEAM MEMBERS—GROUP C
-
Sima Bagheri, New Jersey Institute of Technology
-
David A. Fike, Washington University
-
Douglas P. Finkbeiner, Harvard University
-
Eric Gilleland, National Center for Atmospheric Research
-
David M. Hondula, The University of Virginia
-
Jonathan J. Makela, University of Illinois at Urbana-Champaign
-
Mahta Moghaddam, The University of Michigan
-
Naoki Saito, University of California, Davis
-
Curtis Woodcock, Boston University
-
Olga Khazan, University of Southern California
IDR TEAM SUMMARY—GROUP C
Olga Khazan, NAKFI Science Writing Scholar, University of Southern California
Scientists who rely on images to provide data are faced with an unusual challenge: Although taking two images is easy, finding the scientific difference between the two images remains a much more complicated task.
Scientists trying to find the differences between two images often find
themselves constrained by the limited number of tools for image differentiation in their field. Someone who studies changes in the ocean floor, for example, would use a different methodology than someone who looks for changes in the urban climate. The type of software, the type of algorithm used to read the data, and even what is considered “noise” (or irrelevant information) are specific to each field, and they vary from discipline to discipline. Because of this segregation of image detection methods between physicists and climatologists, for example, researchers frequently find themselves “stuck” doing change detection as it has always been done in their field, which can stymie the progress of change detection methods overall.
IDR team 3C, at the National Academies Keck Futures Initiative Conference on Imaging Science, was tasked with “developing and validating new methods for detecting and classifying meaningful changes between images.” Although standard methods for differentiating images already exist for everyone from astronomers to zoologists, scientists from different areas suffer from a lack of communication about these methods.
In order to help scientists get a more complete impression of the changes that occur between two images, team 3C set out to breach the divides between disciplines when it comes to image processing. The group aimed to lay a unified framework that would combine the practices used by everyone from astronomers to climatologists to radiologists.
What Is Image Differentiation?
There are three categories of observations a scientist might note when evaluating the changes between two images: First, there is everything in the image that the researcher is not interested in measuring, like rocks when the study is about trees, or stars when the study is about planets. There is also the noise/artifact, or the interference from environmental factors, such as soil moisture and cloud cover. Finally, there’s everything the researcher is interested in measuring, which can also be called the meaningful change that occurred between the time two images were taken.
The easiest way to define a meaningful change in an image might be simply “a cluster of points in a large space” as one of the group’s researchers explained.
That meaningful change usually has a few defining characteristics. First, it is persistent, in that it appears repeatedly throughout multiple images. Second, it is specific to a certain portion of the image. That is, a
large portion of the image will remain the same, but the change occurs in a small area.
Typically, the way differences between two images are found is through the following chain of actions: First, the scientist captures the images. Then, the images are examined in order to determine how they vary. Then changes between them are subtracted from one another and corrected for noise. That should leave (more or less) the change that occurred between the images.
There are countless ways to observe changes between images. In medicine, one can monitor the growth of malignancies by evaluating images of a tumor, at different times, ranging from weeks to months to years. But there are also less-obvious applications for measuring changes, like when the amount that something changed is a matter of political or international importance.
For example, the progress of forest deforestation, which is measured by looking at the changes between two images of a forest, could have vast impacts on cap-and-trade policies, agreements in which billions of dollars are at stake. Therefore, in order to make sensible decisions based on changes in images, scientists need to know what they’re measuring and why.
Methods for Good Change Detection
It’s impossible to model an entire forest or an ocean, so imaging specialists choose a set of parameters, or dimensions, that they can use to characterize an image. For example, in a forest these dimensions might be the height or density of the trees.
The essence of detecting change is being able to recognize what doesn’t change. Most changes are subtle, and most of the image doesn’t actually change. Furthermore, it involves accounting for the aberrations in the image (clouds, snow, etc., while bearing in mind that the “noise” may contain significant data.
After the two images are generated, a process known as optical flow can be used to determine the relationship between the two images and therefore to create statistical models for changes in similar images. Optical flow is the process of asking what translation one can impose on each part of the image to create the next image.
The Pitfalls
However, there are a number of obstacles in measuring the meaningful changes, and these challenges vary depending on the type of image processing being used.
The amount of data one captures can create an image that is either too small to be meaningful, or so huge it’s nonsensical. The challenge is to capture the right number of pixels (within instrumental and financial constraints, of course) so that the image is neither overwhelmingly hyperspectral nor underwhelmingly uniform. The change that an instrument detects may not signal an important change on the ground, after all. For example, the density of a radar signal may vary based upon the time of day, the time of year, and other factors.
When evaluating noise, a common pitfall is throwing out data points that fall within the range of what is considered extraneous information, or “noise.” If there are multiple points in the noise range, after all, presumably those points would signify a meaningful cluster.
Then there comes the problem of whether the researcher should study the raw data versus the images that are mapped from the raw data. The latter option compounds the likelihood of error in detecting a change because there may have already been errors in the mapping of the image.
Finally, models, or the ways that data are processed into images, are not always perfect. Computational issues, poorly measured interference, imperfect algorithms, and the nonlinear nature of certain problems can all make it hard to generate an accurate image from the data collected.
There’s no way to know that the model results are close to reality. And because the models are imperfect, there can be issues in characterizing the uncertainty of the answers.
Working Across Applications
To complicate matters further, each of these obstacles and their potential resolutions vary among scientific disciplines. One climatologist may use a program called MATLAB to convert data into an image, for example, while another will use a program called Fortran.
Furthermore, the type of data gathered varies by field. For example, environmental science may operate on a larger scale (like a forest), while biomedical sciences may operate on a smaller scale (like a tumor or a heart or a whole body). Furthermore, in some sciences, the data type is more or less ephemeral than in others—like heat waves versus rocks. For example,
a climatologist would be more interested in measuring heat waves, while a geologist might be more interested in the composition of rocks. This discussion prompted the necessity to for some sort of basic, cross-disciplinary formula to describe the modeling of parameters as images. Our group chose to represent this basic formula in this way:
D = f(x,h) + n
Where D is the data (or image) constructed, f is the transfer function (or model), x is the parameter (such as height or biomass), h represents the hidden variables or nuisance parameters (such as atmospheric effects), and n is noise, or the parts of the image the researcher is not interested in measuring.
Depending on the task, however, some of these variables might be hard to define. In the task of supernova detection, for example, the parts of the image that aren’t the supernova are things like other stars and cosmic rays. Therefore, the “h” is known and measurable. In land use, on the other hand, the final image comprises a variety of potentially confounding factors, such as clouds and shadows, none of which the researcher can predict. Therefore, the “h” is unknown.
Because of these differences in the variance of h, the model (f) for each of these disciplines can also vary. In astronomy, therefore, image detection tends to have a well-defined “f,” while land use may have a poorly defined “f.” These variances in “f” can make it challenging for scientists to work in one specific program or algorithm to detect changes between images. However, they may still benefit from studying the approaches taken in other disciplines, because the solutions may be applicable even if the data types are not.
Two Potential Solutions
There currently exists no canon of imaging science that can serve as a reference for image analysts across disciplines. Many scientists who actually perform image analysis were never academically trained in the practice, and instead learned on the job from others in their own profession.
In order to overcome these myriad obstacles, the IDR team proposes the creation of a common framework to detect changes in images across disciplines. Using methods that were developed in other fields would allow individual researchers to enhance their ability to detect meaningful change where they may have overlooked it previously.
The group proposed creating a textbook or online repository that
would combine examples and frameworks for detecting important changes in images across all disciplines. It would also include software examples and tutorial datasets for the user to experiment with. This guide would serve as somewhat of an interdisciplinary “best practices” outline for image analysts so that they would not be circumscribed by the methods of their own disciplines. In this way, a geologist could see if a program or algorithm from medicine, for example, might suit one of his particularly challenging imaging tasks.
In 2009, the DVD rental service Netflix held a competition for whoever could find the best algorithm for predicting which movies users would like. In a similar vein, the IDR team proposes a multidisciplinary “image-change detection challenge.” The challenge would provide a comprehensive dataset and a time series of images to analysts from any discipline. The analyst could then identify the features and estimate the dimensions of the change with his or her own tools or methods. Taking a cue from the “Netflix challenge” and other database contests, a cash prize could be awarded to those who successfully complete the challenge. By seeing the various approaches to the challenge, the original creators of the data set and images could see if there was a new or better approach to the change detection than the one they had been using
With these two solutions—the data challenge and online repository—image analysts would be better able to apply existing solutions to their current problem. That way, scientists from multiple fields would be provided with not only their own tools for detecting changes, but also those of their colleagues from other disciplines.


















