
2
Data Quality Challenges and Opportunities in a Learning Health System
KEY SPEAKER THEMES
Overhage
• Heterogeneity of data limits the ability to draw conclusions across datasets.
• Data quality assessment requires understanding if data is fit for its intended purpose.
• Data collection should aim to maximize value by balancing the burden of collection with its usefulness.
Heywood
• Clinical research is not currently focused on what patients consider valuable.
• Patient-reported data are critical for answering questions important to patients.
• A learning health system will require converging clinical research and clinical care on a common platform constantly oriented around patient value.
A learning health system relies on collecting and aggregating a variety of clinical data sources at the patient, practice, and population level. Realizing this goal requires addressing concerns over data quality and harnessing new opportunities and sources of clinically relevant data. Marc Overhage, Chief Medical Informatics Officer at Siemens Healthcare, focused his presentation on the challenges for data collections and the limitations inherent in aggregating data across sources. Jamie Heywood, Co-Founder and Chairman of PatientsLikeMe, examined the issue of data quality as it relates to patient-reported data, and how patient value must be a central strategy in building a learning health system.
CHALLENGES FOR DATA COLLECTION AND AGGREGATION
Marc Overhage focused on several of the challenges posed by collecting and aggregating data to help derive meaningful conclusions and improve care. At each possible source of data collection, he noted, there are limitations to the quality of data obtained. With patient reported data, the way a patient understands or reports an event may not be understood in the same way by clinicians or researchers. Clinician-recorded data is limited in scope and quality by the time it takes to input structured data into an EHR. Finally, while external sources of data—labs, imaging, pharmacy, etc.—are not subject to the same human biases, they still carry other biases and limitations such as lack of standardization across products.
Overhage focused on structured data collection from the clinician perspective, which he posed as a balance between the burden and cost associated with its collection (impact on usability) and its value (usefulness of data) (see Figure 2-1). More structured data is generally more useful. However, the level of structure dramatically impacts the burden of collection, and therefore the usability of the collection system; rigidly structured data is usually time- and resource-intensive to collect. There should be a focus on maximizing both usability and usefulness—that is, finding optimum value.
Structured data collection is only part of the challenge. According to Overhage, although more and more efforts are being made to bring data together in a “queryable well,” most digital health data remains siloed within different institutions and organizations. Data aggregation is crucial for a learning health system, but brings about new challenges.
One challenge noted by Overhage is the ability to identify patients across sources. When health information exchanges combine data from various sources, duplication of data or different views of the same clinical event can occur. He brought up the example of identifying which patients are on statins. Patients can be identified either based on medication order
data from an EHR or by claims data. Both are “right,” as both are facts about the patient, but they can yield different results. Some patients have both an ordering event and a dispensing event, some have one or the other, and some have neither. Successful data aggregation, according to Overhage, will need to account for the fact that there are going to be repeated observations and conflicting evidence, and combine evidence in a meaningful way. Fortunately, there are computational advances that can improve this process. Overhage pointed to work being done at Siemens on computer algorithms that can parse through conflicting evidence, assess its provenance, and begin to draw conclusions that clinicians can use.
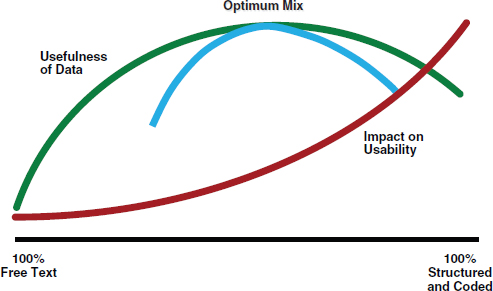
FIGURE 2-1 The usability-usefulness tradeoff for data collection.
SOURCE: From Ambulatory practice clinical information management: Problems and prospects, by B. Middleton, K. Renner, and M. Leavitt. Journal of Healthcare Information Management 11(4):97-112. Copyright 2012 by the Healthcare Information and Management Systems Society. Adapted with permission.
Another challenge cited by Overhage was the ability to conduct population-level research on interventions and outcomes. He expressed caution with using large claims or health system EHR databases to draw conclusions. In particular, he focused on the importance of understanding the characteristics of datasets, such as the underrepresentation of females in the Department of Veterans Affairs (VA), especially when making comparisons across datasets. He presented data from the Observational Medical Outcomes Partnership (OMOP) showing the correlation of Cox-2 inhibitor use to an increased incidence of myocardial infarction in a health system
dataset. When this correlation was explored in other health system and claims datasets, however, no relationship was found. This type of heterogeneity impacts efforts to combine datasets for observational research. Differences in context and demographics limit comparability between datasets. For example, Medicare has a vastly different age distribution than most commercial payers. Similarly, the gender distribution for the VA dataset is disproportionately skewed toward males. Heterogeneity is not limited to demographics, he stressed, but also includes the context in which the data was collected—e.g., changes in drug utilization patterns within a given health system over time.
Overhage concluded his remarks by stressing the need to appreciate that data quality lies in the eye of the beholder. The true quality of digital health data is an assessment of whether they are fit for their intended purpose. For example, he noted, data quality for population health measurement may be able to tolerate more error since researchers are looking for trends and changes at the population level. The same may be true for quality-measure adherence as well. However, at the individual patient encounter, decision support needs to be exactly right, and clinicians must have the correct information on the correct patient. Depending on the use, criteria for what is “good-enough” data will vary tremendously.
PATIENT-REPORTED DATA AND MAXIMIZING PATIENT VALUE IN THE LEARNING HEALTH SYSTEM
Heywood began his presentation with a series of quotes from management expert Peter Drucker: (1) Who is your customer? (2) What does your customer consider value? and (3) What are your results with customers? He proposed that the fact that health care costs have been increasing while the value of care has been decreasing can be traced to an inability to understand and answer these questions in the health care system.
In health care, Heywood stressed, the patient is the customer. This relationship, however, can be obscured in the research setting. According to Heywood, the clinician or researcher asking the question, rather than the patients, can often become the customer. This has profound implications on the utility of research. If the patient is the customer, he noted, research should be delivering results that they consider valuable. Currently, this is often not the case. Most clinical research focuses on physiologic, molecular, and other markers rather than aspects that matter most to patients: well-being and productivity. In order to serve their customers most effectively, Heywood proposed that all of research should be helping to answer this question that patients value most: Given my status, what is the best outcome I could hope to achieve and how do I get there? Digital health
data that help to answer this question needs to be captured, recorded, and analyzed.
According to Heywood, patient-reported data can help improve the relevance of medical research to patients. He provided a brief overview of the PatientsLikeMe (PLM) online platform, and how it enables patients to share their data and learn from others. Patients create profiles on PLM which detail personal information, medical history, treatment history, and track functional status over time (using accepted patient reported outcome measures). This allows other patients on the site to find individuals similar to them, and learn from their experiences.
Despite some concerns over the perceived quality of patient reported data, Heywood provided an example of how patient-reported data can answer some of the same questions that traditional clinical outcomes research methods are used for. Since patients with amyotrophic lateral sclerosis (ALS) comprise one of the largest groups on PLM, he detailed the use of patient-reported data to assess the efficacy of lithium in slowing the progression of ALS. In 2008, the results of a clinical trial were published showing that lithium significantly slowed the progression of ALS symptoms. Using the PLM platform, researchers were able to test this same treatment in the PLM population. They used an algorithm to match ALS patients being treated with lithium to similar patients who were not undergoing lithium treatment. The variety of demographic and physiologic variables recorded on PLM profiles allowed for each patient to be matched to an individual control, rather than pairing groups. No change in the progression of ALS symptoms was observed in the population being treated with lithium. The same results were later found in four clinical trials stopped early for futility.
The benefit of routinely collecting patient-reported data through a platform like PLM is that it greatly speeds up the assessment process for interventions. Since data are already in place, conducting clinical research does not require building new infrastructure nor collecting new data. According to Heywood, this allowed the researchers at PLM to conduct their study of lithium efficacy in ALS patients in a fraction of the time, and at a fraction of the cost, of the follow-up clinical trials to the 2008 study.
After focusing on the ALS case study, Heywood broadened his discussion to consider the transformation necessary to use data—regardless of source—to improve the health system. He returned to the center question patients value most: Given my status, what is the best outcome I could hope to achieve and how do I get there? The path to answering this question, he suggested, is building learning mechanisms, such as predictive models, into the system to speed discovery, assessment, and implementation. If done effectively, this would converge clinical research and clinical care into one model on a common platform. Heywood proposed that if this is done within the context of what the patient perceives as valuable, and keeps
patients part of the process the whole time, the result will be a learning health system. Heywood concluded his remarks with a series of paradigm shifts necessary to move toward a learning health system (Figure 2-2). These include moving toward a system characterized by sharing rather than privatization, patients as partners rather than subjects in research, accessibility rather than security, learning rather than validation, personalization rather than aggregation, and openness rather than closedness.
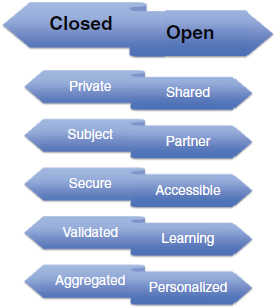
FIGURE 2-2 Paradigm shifts required for the realization of a learning health system. Status quo is presented on the left and requirements of a learning health system on the right.
SOURCE: Reprinted with permission from James Heywood.






