





































Below is the uncorrected machine-read text of this chapter, intended to provide our own search engines and external engines with highly rich, chapter-representative searchable text of each book. Because it is UNCORRECTED material, please consider the following text as a useful but insufficient proxy for the authoritative book pages.
C H A P T E R 3 FindingsSHRP 2 Management Perspective The research team interviewed the SHRP 2 program director and senior program officers for the Capacity, Reliability, Renewal, and Safety program areas early in the project in order to understand their perspective on the issues. Goal and Targeted Audience for the Reliability Archive The primary objective of the Reliability Archive is to allow users to validate the research results from relevant SHRP 2 projects and to refine and build on research results in the future. Cur- rently, the archive is mainly targeted to serve transportation researchers, such as university professors, transportation engi- neers, and planners. Thus, its expected immediate and long- term benefit is to give these researchers access to the data in the archive so that they can reproduce research results or build new research on the data. The feasibility of the archive hinges largely on the actual size of the downstream user base, which is a key issue in justifying long-term preservation of a research database. While everyone agrees that there is a definitive need for an archive of research data, it is difficult to identify or guess the size of the future user base. The archive could also be used to support other transporta- tion communities in the future. For example, state DOTs can use data in the archive to augment their own traffic data col- lection programs. State DOTs currently spend vast resources to collect traffic data. A national system like the Reliability Archive that can provide state DOTs similar data could reduce state-level data collection efforts and costs. The focus of the archive should be on data rather than on documents, although associated documentation will also need to be archived in conjunction with the data. It needs to be fur- ther clarified whether or not all documentation type project7deliverables, such as reports and presentations, will be archived for the entire SHRP 2 program. From the âdata perspective,â the Reliability Archive may need to focus on data sets that are more oriented toward future researchers rather than toward practitioners whose data needs tend to change frequently. User Access to the Reliability Archive One of the major concerns of SHRP 2 senior management is how easily users will be able to access the data in the archive. Under the first SHRP program, 14 databases were built to cap- ture a wide range of data. At the time of this writing, 13 of these 14 databases are no longer accessible. Part of the reason is that data was saved in old formats that cannot be easily made avail- able with todayâs technology. Data frequently becomes inacces- sible after being collected because of a number of reasons, including the following: ⢠Technology obsolescence; ⢠High costs of maintaining and managing the data; and ⢠Availability of newer and better data. Initial ideas were exchanged during the meetings with respect to making the archived data more widely accessible and more easily available to those who need it. One approach is an on- the-fly extraction and transformation service as a function available through a portal-type user interface. The following specific examples were discussed: ⢠Each program under the SHRP 2 has established a business framework that describes its program vision and underly- ing business concepts and principles that guide individual projects. These frameworks could be used as a business context or portal to construct future user interfaces for the Reliability Archive. For example, the Capacity Programâs Collaborative Decision Framework includes 50 decision
8points intended to work for all states. It basically rewrites the entire transportation planning process. Each decision point can have its own archive. ⢠Another approach is to provide users with more contextual information about data sets. Commercial products are emerging that are designed to allow users to search, display, and consume information without having to know anything about how and where it is structured and stored. Views on the Data to Be Archived The primary objective of the Reliability Archive will be to pre- serve research project data. However, archiving data is much more complicated than simply saving data in a file system or a conventional database. The research teamâs interviews yielded the following views on the data to be archived in the system: ⢠The interviewees agreed that conclusions as well as data need to be archived; these conclusions are in the form of research products based on the data. ⢠Projects relevant to the archive will typically involve either collecting data or analyzing or mining data. As such, the data expected to be archived will include base or raw data that represent the original information collected as well as research or subject data that are outcomes of analyses. ⢠Sometimes the base or raw data sets may be proprietary and may not be used outside the associated projects; only insti- tutional staff may have access to this type of information. ⢠Data to be archived will either be collected by the project contractors or purchased from vendors such as INRIX. For example, arterial data is hard to collect and most probably will be purchased from vendors. ⢠The Federal Highway Administration (FHWA) is expected to have nonexclusive rights to subjective data. The original producers may retain commercial rights. ⢠Metadata is critical because people often call two different things the same name; hence, it is necessary to define meta- data standards. It is therefore desirable to have a data diction- ary and other means to describe the data to the researchers. ⢠The use of XML to represent metadata was discussed as a promising way to describe data consistently. Project Contractor Perspective The research team also interviewed the contractors of active Reliability projects and relevant Capacity projects (C04 and C05) to understand the data used and produced by those proj- ects that would need to be archived. Examples of such data include travel time and speed used for modeling and simula- tion, travel- or highway-related data collected during a project, analytical models developed by a project, and reports and presentations produced as a result of a project.Appendix A summarizes the key characteristics of reliabil- ity and other SHRP 2 projects that are relevant to the Reliabil- ity Archive. The characteristics are organized according to the following categories: ⢠Raw Data: Almost every project listed in Appendix A is required to collect or obtain some form of raw data to sup- port its analysis. In order for future researchers to validate the results of these projects, it is desirable that the raw data be retained in the archive. Two aspects of the raw data, namely, Data Sources and Data Rights, are examined and summarized in Appendix A. ⢠Research Outcome: There are a diverse range of outputs produced from these SHRP 2 projects. Each type of output is an integral part of the entire set of outcomes toward building an enriched knowledge repository. The following are typical types of outputs: â Derived Data: This includes data derived from any kind of analysis on the raw data via mathematical models, modeling and simulation, and computer programs. Such derived data may be saved in a variety of formats such as spreadsheets, text files, and databases. â Models: This includes mathematical models and formu- las, simulation models, business process flows, strategies, methodologies, and analytical frameworks. They can be in text, graphics, and equation formats. â Tools: This refers to small to medium types of computer- based tools or applications developed by the contractors to support their analysis. These tools will typically be tied to an application development environment such as SAS, Excel, or Access. â Code: This refers to any software code that is developed and used by the contractors to derive their outcomes and conclusions. An example would be a JAVA or C++ program. The programs will typically be saved in both a source file format and an executable format. â Reports: This includes written reports, technical mem- oranda, presentations, and training materials, most of which are expected to be in Microsoft Word, Excel, PowerPoint, and PDF formats. ⢠Reliance on Other Projects: This captures the data depen- dencies among projects, which must be retained so that future users can have a complete and thorough under- standing of the outcomes produced from these projects. ⢠Metadata: This summarizes what metadata standards, if any, are planned to be used in each project. Figure 3.1 presents an overall project timeline based on information available from the SHRP 2 program. The projects are organized into the following categories: ⢠Reliability Archive-related projects; ⢠Active projects;
9Figure 3.1. Project timelines.⢠Pending projects; and ⢠Future planned projects. The following conclusions were drawn from this project timeline: ⢠Most reliability projects are already under way. At the time this report was written, only four more projects have yet to be started. These include one pending project (L05) and three planned projects. â One of these four projects will become active in early 2010. â The three remaining projects (L08, L09, and L15) will become active in 2010. ⢠All projects will be completed by the end of 2012. â Two projects were completed by the end of 2009. â Six projects will be completed by the end of 2010. â Two projects will be completed by the end of 2011. â Six projects will be completed by the end of 2012. The implementation of the Reliability Archive will be com- pleted by August 2011, assuming it will start within 12 months of the completion of the feasibility study. By the time the Reli- ability Archive is deployed, two-thirds of the projects will be completed. Data from these projects should be available to be moved into the Reliability Archive. Currently, no single metadata standard is applied across all these projects. It appears that each project develops its own approach to data collection and organization. The research team believes it is highly desirable that the efforts of assisting project contractors to prepare their data for archiving (whichis the intent of planned Reliability Project L16, now a part of Reliability Project L13A) be started earlier, preferably early in 2010, well before a number of projects are expected to be completed. Literature Research The findings from the meetings with SHRP 2 stakeholders and Reliability project contractors reinforced the research teamâs initial impression that a single, conventional rela- tional database system would not be adequate to build the Reliability Archive. Thus, the research team started to focus on a vision of an active archival system that could serve as a repository capable of managing files and metadata from different content sources. Digital Archiving Technology A survey of the literature in the public domain reveals that the issue of archiving digital resources has been discussed actively for the last decade and that the intensity of the discussion and corresponding volume of research, opinions, experience, and technologies pertaining to the subject have grown dramatically in the last few years. It is not hard to understand why this has happened when one considers the explosive growth of digital information that has occurred, which shows no sign of abating. One industry analyst forecast (1) projected a compound annual growth rate (CAGR) of digital content of 57% worldwide between 2006 and 2010. As organizations accumulate vast amounts of dig- ital content, they are becoming increasingly aware that it is
10actually much easier to lose digital information than it is to lose traditional paper records. The Storage Network Industry Associationâs (SNIA) 100 Year Archive Requirements Survey (2) identified this so-called âDigi- tal Crisis,â which involves the risk of losing digital information over time because one ⢠Cannot read it; ⢠Cannot interpret it correctly; ⢠Cannot validate its authenticity; or ⢠Cannot find it. The executive summary of the same report also describes succinctly the two grand technical challenges of logical and physical migration that must be dealt with in an archival system: Logical migration is the practice of updating the format of the information into a newer format that can be read and properly interpreted by future applications or readers without losing the authenticity of the original. Physical migration means to copy the information to newer storage media to preserve the ability to access it and to protect it from media corruption. Best practices today require logical and physical migration every 3â5 years. (2) Until recently, a digital archive was generally thought of as a library of tapes containing backups. It is now more widely understood that storage backup and disaster recovery tech- nologies designed for operational continuity do not address the issue of long-term data preservation. Backups take a snapshot of information at a given point in time that may be restored as quickly as possible. They are a short-term data recovery solu- tion after data loss or corruption. Digital archiving, on the other hand, preserves the authentic digital document of record for a specified period of time (or even indefinitely) to keep it acces- sible even as technology advances. Preservation is thus a primary focus of a digital archive, but the preservation of digital records presents numerous challenges because, unlike paper or microfilm, digital informa- tion can easily be corrupted, disseminated, copied, or altered beyond recognition. Also, the hardware and software needed to access digital records change rapidly, and storage media such as tapes and discs can deteriorate quickly even if they do not appear to be damaged. Finally, the context of a digital record and its relation to other records can easily be lost. The sheer volume and the volatility introduced by digital content impose a new set of requirements capable of scaling and of preventing accidental changes to the records. Proce- dures need to be put in place to identify, classify, move, evolve, access, and occasionally dispose of digital records. Both library science and traditional archival practice provide an extensive body of knowledge that is being leveraged with technology to provide solutions to this digital preservation dilemma.Research and Standards Initiatives in Archiving Research and innovation around digital preservation are occurring in both the public and private sectors. Organizations with a vested interest in the subject, such as national libraries and archive agencies of many countries, museums and libraries, major research universities, standards organizations, and industry associations are active in the field. Information technology companies now have second- and third-generation hardware and software products on the market. The most influential standards initiative for archival sys- tems is the Reference Model for an Open Archival Information System (OAIS) (3), which has been adopted as an Inter- national Organization for Standardization (ISO) standard (ISO 14721) that identifies the processes required for long- term preservation within an archival repository and establishes a common framework of terms and concepts. The OAIS model was developed by the Consultative Com- mittee for Space Data Systems (CCSDS) in response to a need for standards in support of the long-term preservation of digital information obtained from observations of terrestrial and space environments. The research team believes that it is relevant to the SHRP 2 program because of the following reasons: ⢠It was developed by agencies confronted with very long- term and very large-scale data preservation problems. ⢠It emphasizes long-term access in addition to long-term data preservation. Governmental agencies, museums, libraries, and other institutions have an inherent understanding of the long-term value of the content they are archiving and its importance to future researchers. (In contrast, many initial deployments of archiving technology in commercial enter- prises were driven by compliance mandates, which created a âfix it fastâ mentality to put in place a system that allowed the organization to prove it was meeting its legal obligations to retain information.) ⢠It is widely accepted as a reference model that provides a common vocabulary useful for framing requirements and in assessing implementation and operational feasibility. One of the most important concepts of OAIS is the idea of an information package, which is essentially a container (or object) that encapsulates both the archived data itself (con- tent information) and the various categories of metadata that describe the data, its relationships to other data, and other descriptive information. Figure 3.2 shows the information package concept. Managing content and context in this self- contained and self-describing way makes it easier to apply the traditional archivistâs governing principles, such as prove- nance, in the digital realm.
11Figure 3.2. OAIS information package concept.The OAIS model also defines the major entities and func- tions of a digital repository constructed to maintain safe, long- term custody of digital objects, as illustrated in Figure 3.3. The major functions are as follows: ⢠Ingest: Accepting digital objects into the archive; ⢠Archival storage: Storing, managing, and retrieving objects; managing the storage hierarchy; and refreshing the media on which the objects are stored; ⢠Data management: Writing, reading, and updating both administrative data and descriptive metadata; ⢠Administration: Managing of the overall operation of the archive; ⢠Preservation planning: Managing the logical and physical integrity of the archive over time; and ⢠Access: Locating, applying access controls, and generating responses to requests for archived objects.Figure 3.3. OAIS functional entities.The items labeled SIP (Submission Information Packages), AIP (Archival Information Packages), and DIP (Dissemina- tion Information Packages) in Figure 3.3 refer to the different kinds of self-contained, self-describing information packages that might exist in a repository. Producers submit SIPs to a repository. In the Reliability Archive, the producers will be the research teams conducting the various research projects in this focus area of the SHRP 2 program. AIPs will be managed by the Reliability Archive for the duration of their valuable life cycle. DIPs are retrieved when transportation researchers and practitioners access the Reliability Archive. It is important to note that the OAIS model is a conceptual framework that does not prescribe any specific implementa- tion at any level. The OAIS model defines what is needed for a modern digital archive but not how to build it. It is the con- ceptual foundation for many important digital preservation initiatives as well as many archival products. Role and Importance of Metadata Metadata literally means data about data; its importance in a long-lived digital archive cannot be overemphasized. Meta- data is important for context, description, and discovery, and it also encodes policies related to administration, accession- ing, preservation, and use of information. Over time, many standards have been developed to rep- resent different categories of metadata for specific object types. The transportation sector is no exception. However, there is no catch-all standard that accommodates every type of digital object. The research team expects objects managed by the Reliability Archive to be tagged with different kinds of descriptive and technical metadata as appropriate for their content.
12In addition to metadata specific to particular object types, all digital objects require different levels and types of meta- data at different points in their life cycle; all of this diverse metadata needs to be associated or packaged with the object it describes. The Metadata Encoding and Transmission Standard (METS) (4) was developed to deal with these issues. METS was developed by the Digital Library Foundation and is supported by the Library of Congress as its maintenance agency. Metadata Encoding and Transmission Standard METS was designed as an overall framework within which all the metadata associated with a single digital object can be stored or referred. METS is an Extensible Markup Language (XML) schema that provides a mechanism for recording the various relationships that exist between pieces of content and between the content and the metadata that make up a digital object. It enables effective management of digital objects within a repos- itory, acts as a standard for transferring metadata within repos- itories, facilitates access and navigation by the researcher, and links the digital object and its metadata inextricably together. METS was specifically designed to act as an OAIS informa- tion package. It can deal with all categories of metadata cited by OAIS (content, preservation, packaging, and descriptive metadata). Packaging all of this metadata with the digital object it describes ensures that the object is self-documenting over time. An Aside About XML XML is sometimes called a metalanguage, which means that it can describe other languages. It is extensible because the markup elements are user-defined. XML and HTML are sometimes confused. HTML was designed to specify how data are presented, whereas XML was designed to transport and store data and says nothing about their presentation. Figure 3.4 shows an excerpt from an XML document, which is one row (record) from a table exported from the Long- Term Pavement Performance (LTPP) database as it might be encoded in XML format. The structure and data are quite easy to deduce since XML is eye-readable (and machine- readable, too). The tags in the example (like <SHRP_ID> and <STATE_CODE>) delimit the data contained in the document. (Each tag has a corresponding closing tag starting with a slash, e.g., </SHRP_ID>.) XML is considered a robust archival format and is readily interchangeable because it uses standard ASCII code rather than a binary format to encode data. Because it is neutral and flexible, it has become a de facto standard way to express both data and metadata in a structured manner.<INV_LAYER> <SHRP_ID>0500</SHRP_ID> <STATE_CODE>1</STATE_CODE> <CONSTRUCTION_NO>1</CONSTRUCTION_NO> <LAYER_NO>1</LAYER_NO> <DESCRIPTION>7</DESCRIPTION> <MATERIAL_TYPE>52</MATERIAL_TYPE> <LAYER_TYPE>G</LAYER_TYPE> <RECORD_STATUS>E</RECORD_STATUS> </INV_LAYER> Figure 3.4. XML encoding example.METS Document Structure The following section provides an overview of the structure of a METS document and its application. As Figure 3.5 illustrates, a METS document consists of seven major sections: 1. METS Header: Contains metadata describing the METS document itself, including such information as creator and editor. 2. Descriptive Metadata: May point to descriptive meta- data external to the METS document, or contain inter- nally embedded descriptive metadata, or both. Multiple instances of both external and internal descriptive meta- data may be included in the descriptive metadata section. 3. Administrative Metadata: Provides information regarding how the files were created and stored, intellectual property rights, metadata regarding the original source object from which the digital library object derives, and informationFigure 3.5. METS document structure.
13regarding the provenance of the files constituting the digital library object (i.e., master/derivative file relationships, and migration/transformation information). As with descriptive metadata, administrative metadata may be either external to the METS document or encoded internally. 4. File Section: Lists all files with content that constitutes the electronic versions of the digital object. Files may be grouped by object version. METS can deal with simple digital objects containing a single file and with complex objects composed of many files. 5. Structural Map: Outlines a hierarchical structure for the dig- ital library object, and links the elements of that structure to content files and metadata that pertain to each element. METS can express the hierarchical structure common to digital objects, which may have been created originally in multiple directories and folders. 6. Structural Links: records the existence of hyperlinks between nodes in the hierarchy outlined in the Structural Map. 7. Behavior: can be used to associate executable behaviors with content in the METS object, including the ability to identify a module of executable code that implements and runs the behaviors defined abstractly by the interface definition. An advantage of METS is that it does not dictate the content of metadata. Other metadata schemas can be incorporated into a METS file or referred to from it. It is also extensible inasmuch as new versions of metadata may be incorporated alongside older versions of metadata. Because it was conceived as a framework for packaging dis- parate metadata, METS has strong advantages in this area. The research team believes that such a framework is needed. Any system capable of handling XML documents can be used to create, store, and deliver a METS file, thereby mitigating prob- lems of software obsolescence. METS offers strong capabilities, flexibility, and extensibility. Finally, it has strong worldwide adoption, particularly in preservation repositories. Other Descriptive Metadata Sources In the context of OAIS and a METS âwrapper,â descriptive metadata is and can be thought of as being associated with a digital object. There are two other kinds of descriptive meta- data that can be gleaned from digital objects and used to find items of interest: ⢠Embedded metadata is descriptive metadata contained within the file itself. A familiar example is the information displayed when a Windows user right-clicks a file and chooses Properties. In addition to file system metadata such as size or date created, many document formats embed author, subject, and keyword information. Image files typ- ically embed metadata related to height, width, color depth,and so forth. This embedded metadata can be very useful in helping future users find and filter content of interest. ⢠Derived metadata is information that can be gleaned about a file through content inspection. This can be simple key- word indexing or it can involve much more sophisticated techniques that can identify entities, relationships, and contextual linkages. The advantages of derived metadata as a finding aid in a long-lived archive are numerous. It is impossible to anticipate all the ways that future researchers will wish to access information. Derived metadata is not dependent on fixed metadata schema that effectively requires that all classification be done up-front. It can be extracted at any time. Moreover, it is reasonable to assume that more and more sophisticated information extraction technologies will become available over the life of the archival system. Embedded and derived descriptive metadata can be used, along with metadata stored or referred to in the objectâs wrap- per, to facilitate user access to information in the archival system. Vision for the Archival System In the research teamâs experience, any successful require- ments analysis and feasibility study must be guided by a clear and accurate vision. This project is no exception. The initial vision for the proposed archival system was set in the RFP for the L13 project. This RFP made it clear that long-term preservation of Reliability focus area project data is important (âin the range of 20 to 50 yearsâ) and that the rea- sons for preserving these data are (1) âto allow others to vali- date the research results,â and (2) to make the data âavailable for researchers in the future to refine and build on the research results.â In the course of this research, the team talked to a wide range of stakeholders and has come to a more expansive vision of the archival system. From the research, the team has identified three main goals for the Reliability Archive: ⢠Preserve for up to 50 years all of the valuable digital assets collected and produced by SHRP 2 Reliability focus area research projects. ⢠Provide transportation researchers and practitioners with a way to discover and then access these digital assets in standard, open formats. ⢠Establish an extensible architecture that facilitates future expansion of the archival system to: â Preserve digital assets from other projects; â Enhance discovery by integrating related data (e.g., for data visualization); â Provide data integration or mashup services; and â Create a collaborative community.
14The first goal expresses that all of the digital information being purchased, collected, aggregated, analyzed, and produced across all of the Reliability focus area projects is a potentially valuable asset that must be protected for the long-term. The second goal captures the understanding that the prospective users of this digital information are both prac- titioners and researchers, and that they have certain expec- tations, shaped by the Internet and other experiences, of how users should be able to find and exploit information in the system. The third goal builds on the second to consider how broader connections might be made. At the data level, it is clear that data from other focus areas either relate to the Reliability focus area or are similarly valuable and perhaps should be preserved in the archival system. It seems likely that users will want to connect data from the archival system to other external ser- vices or with other external data. Finally, it is natural that users might want to connect with each other to learn from each other and share their experiences in using the information in the archival system, and that the system itself might facilitate these connections. Conceptual Design for the Archival System After interviewing project teams across the Reliability and other focus areas of SHRP 2, the research team observed the following: ⢠Among projects that are under way, diverse file types are being collected and produced that embody the intellectual product of each research project. ⢠Some projects are purchasing or collecting structured data sets (databases) and, in some cases, aggregating such data, any of which may form the basis for analytical models and resultant predictions and conclusions. ⢠The nature of these structured data sets varies from project to project. Incident, extraordinary events, VOS (volume, occupancy, and speed), and roadway information are some of the data set types that exist. The formats of these data sets also vary. Some are in flat binary files, while others are in various database formats, some of which are proprietary to particular software vendors. ⢠There is variability among structured data sets containing the same kind of information, even within a single project. For example, some VOS data may be purchased from a ven- dor such as INRIX, while other VOS data may be collected from a state DOT. Subtle yet significant differences between them might exist. ⢠There are some data, methodology, and outcome dependen- cies among projects (e.g., Reliability Project L05 will buildon the statistical relationships between countermeasures and reliability performance measures developed in Reliabil- ity Project L03). The contractor will develop corridor- and network-level strategies using countermeasures and strate- gies from Reliability Projects L03, L07, and L11, integrated business processes identified in Reliability Project L01, and model results from Reliability Project L04, as well as infor- mation from other sources. Any relationships or linkages will exist at the conceptual or knowledge level, not only at the data item level. ⢠The archival system will need to preserve raw data as well as the data and conclusions derived from it. How raw data leads to conclusions is a combination of data, methodology, and the conclusions themselves. ⢠Some data (particularly raw data) that will be archived have specific rights and restrictions governing access. A fairly granular access control mechanism may be required. ⢠Without exception, all of the projects expect to produce a range of document-centric, or semi-structured, files, includ- ing reports and presentations in various formats. The work product of some projects will consist entirely of documents. ⢠Some SHRP 2 projects are just starting and others are being planned as of this writing. It is impossible to know what all of data from all of the SHRP 2 projects will look like by the time the present feasibility study concludes. These observations lead to the conclusion that the proposed archival system cannot be thought of as a database, which pre- supposes that all aspects of the structure be known up front. Rather, a much more flexible, generalized approach seems warranted. Since the purpose of the archive is to preserve a diverse but related collection of digital artifacts and make them accessible to practitioners and subsequent generations of researchers, the team proposes that the conceptual design pattern for the archival system follow that of a digital library or museum (see Figure 3.6). Among the advantages of this approach is that there is a growing body of standards, software tools, and best practices gaining worldwide adoption, which could be lever- aged should the archival system be deployed. The remainder of this section describes the major elements and functions of the conceptual design, using concepts and terminology from the OAIS reference model. Producers The born-digital files that will eventually constitute the digital objects preserved in the archival system originate with the work of the research project teams. It is expected that the teams will play an important initial role in assembling and organizing
15Figure 3.6. Conceptual design.content for submission to the archive. In OAIS terms, this means the project teams will create initial submission informa- tion packages (SIP) for conveyance to the archival system. While submission for archiving will logically occur upon completion of the project, planning and preparation for archiv- ing will need to occur sooner. This includes selecting, where available, the most preservation-friendly formats for files, and creating basic descriptive metadata. All aspects of copyright, privacy, and proprietary rights must be documented. A Relia- bility focus area research project is anticipated to assist project teams with such submission-related work. The project teams will need training, standards, best practices, and tools. Depositing a file or collection would begin by completing a submission agreement and an inventory of the file or collec- tion. It is expected that all aspects of submission could be sup- ported by a web-based application (submission portal) and the SIP could be transported electronically using Internet protocols such as HTTP and FTP. SIPs would be staged and processed in an accessioning work- bench function prior to ingest into the archival system. Tasks performed would be the typical work of an archivist, which includes appraising a submission as worthy of preservation, and cataloging it. This work essentially involves establishing what OAIS describes as preservation description information (PDI), which is often called preservation metadata. Once the necessary pre-accessioning work has been done, the object or collection would be passed to the ingest function of the archival information system.Core Archive Functions The OAIS model defines ingest, data management, archival storage, access, administration, and preservation planning as the six core functions in an archival information system. At a summary level, these functions are responsible collectively for the following: ⢠Preserving the collection of digital artifacts; ⢠Monitoring and insuring the integrity of digital artifacts across physical migrations and any format migrations (transformations); ⢠Maintaining the physical security of digital artifacts; ⢠Facilitating the discovery of information; and ⢠Enforcing access control. Consumers The primary consumers of the information housed in the archival system are expected to be a worldwide community of transportation practitioners who will use the information directly, as well as researchers who will validate and build on this information base. It is expected that users will interact with the archival system through a web-based portal. This portal would provide a struc- tured way of navigating through SHRP 2 project content as well as context. A logical way of providing structured navigation is by project.
16As researchers become more accustomed to operating in the online realm, they would expect to be able to search for specific items, navigate through information âbottom-upâ as well as âtop-down,â and to follow lateral relationships, including those that may span repositories. At a minimum, users will expect to be able to search by keyword or phrase. Users will also expect the system to provide faceted search, also called faceted navigation or faceted browsing, which is a technique whereby search results are organized dynamically into categories. A count is often displayed so users can see how many results match each category, or facet. The user can then âdrill downâ into the search results by category. The technique is familiar to anyone who has visited an online retailer. Faceted search is also being used extensively in online libraries and is gaining adoption in enterprise search applications. It follows that search and metadata are inextri- cably linked subjects. Metadata will be discussed in some detail in the following section of this report. The navigation techniques described above will help users find what they need. Other services will be needed to provide this information to them. Access to information will only be provided to those authorized to see or download it. The entire archive system will be accessed through an authentication and authorization system. Users will be named and be assigned a role of administrator, submitter, or consumer. (There will be more granular levels within each role.) In terms of access, the two major functions the access portal would provide are the download of single files or file collections, and on-demand data subsetting and download of structured data sets and databases. In concept, the latter would provide what users of the LTPP database have desired, which is a self- service ability to extract and download data subsets of interest. The access portal would be dependent on a stack of widely available software services available commercially and in open source, including the following: ⢠Web server; ⢠Content management; ⢠Data extraction and transformation; ⢠User management; ⢠Rights management; ⢠Content/metadata indexing and query; and ⢠Collaboration. Online Community Online access to a transportation-related digital library service provides an opportunity to connect the consumers of the information it houses. The same social networking techniques and technologies used across many disciplines and organiza- tions to foster collaboration could be employed in the pro- posed archival information system. For example, an onlinemessage board, or Internet forum, could be a feature of the archival systemâs online presence. The forum could be orga- nized into top-level categories reflecting the four focus areas of the SHRP 2 program, with top-level folders for every research project in each category. Forum content itself is entirely driven by its members through their posts and replies. Participants can build connec- tions with each other and groups can form naturally around discussion subjects. Among other things, a forum can help members find answers to questions, share findings and best practices, and identify needs and opportunities for further research. Because of its global reach, leveraging Internet tech- nology in such a way is potentially useful for facilitating inter- national cooperation with other research organizations. Internet forum software is widely available at little to no cost and the research team recommends considering its role as part of the overall archival information system. System Requirements A broad set of requirements was generated from discussions with stakeholders and research into best practices and tech- nical capabilities, both current and expected. These detailed requirements are listed in Appendix C. These requirements were generated and reviewed as part of the second task of the research project. In a subsequent task the requirements were used to evaluate the solution alterna- tives that were formulated. The scoring of alternatives versus requirements is also shown as additional columns in the table contained in Appendix C. For convenience, these requirements are organized into categories and subcategories largely following OAIS nomenclature: ⢠Producers: Requirements pertain to the preparation and submission of digital artifacts to the archival system. ⢠Ingestion: Requirements pertain to the acceptance of digital objects into the archive. ⢠Archival storage: Requirements pertain to storing, manag- ing and retrieving objects, managing the storage hierarchy, and refreshing the media on which the objects are stored. ⢠Data management: Requirements pertain to writing, read- ing, and updating both administrative metadata and descrip- tive metadata. ⢠Preservation planning: Requirements pertain to managing the logical and physical integrity of the archive over time. In general, these reflect the expression of (setting) policies that are typically enforced by other functions of the archival sys- tem. Because there are numerous aspects of preservation, the team uses the subcategories of retention, deletion, replication, logical migration, and backup and recovery to organize these requirements. (Although it is desirable to not
17require routine backups of the data in an archival system, under certain circumstances the ability to back up data to tape or other removable media in a standards-based format is useful, such as for data migration and device relocation.) ⢠Administration: Requirements pertain to managing the overall operation of the archive. The system must operate in a predictable manner, be easily managed, and capable of issuing alerts regarding status and health. ⢠Access: Requirements pertain to locating, applying access controls, and generating responses to requests for archived objects. ⢠Consumers: Requirements pertain to facilitating controlled access to information in the archival system. ⢠Systemwide: General requirements with broad scope. User Interfaces The research team analyzed desirable user interfaces for the Reliability Archive based on a review of the systemâs likely users and their needs. The team focused exclusively on end- user interaction with the proposed archival system (e.g., future researchers and practitioners) and not on administrative inter- faces, since the latter will be largely determined by the imple- mentation path that will be recommended. User Profiles TRB Special Report 296: Implementing the Results of the Second Strategy Highway Research Program, defines four broad user groups for the Reliability products of the program (5). The research team assessed and evaluated these groupsâ interests, preferences, and desired features and functions with respect to user interfaces for the Reliability Archive, as follows: 1. Leaders of transportation agencies are concerned pri- marily with strategic issues related to transportation and its role in the economy and society. â Primary interests: They would be interested in a small but critical set of products, such as business processes, strate- gies, institutional structures, and performance measures. â Desirable user interface: They need to quickly find the conclusions of each project. They are interested in view- ing and downloading business process diagrams, exec- utive summaries, and presentations. 2. The technical staff of transportation agencies is the largest group of potential users of the Reliability products. They are responsible for delivering transportation programs and services to their customers within legal, regulatory, and financial constraints. â Primary interests: They would be interested in differ- ent sets of the Reliability products, depending on their technical roles. Overall they are interested in applyingthe end products such as tools, reports, and training programs to their day-to-day responsibilities. They will also be interested in using the raw data sets to complement their own data and integrate the L13 data sets with theirs to develop their own unique tools or products. â Desirable user interface: They need to quickly find the end products of individual projects according to their roles and responsibilities. The end products will need to be organized accordingly, such as by the categories of planning, design, and operations. It should be recognized that trying any new technologies, operating strategies, and procedures can be difficult and risky. Thus, this group of users will need to be convinced of the usefulness of the SHRP 2 products. The online community of the Reliability program will be an excellent place for them to learn and share with each other the experience of using SHRP 2 products. This user group will also be interested in downloading tools and training programs. Specifically, they will be very interested in downloading raw data sets if they do not have their own jurisdiction-specific data, or they will combine downloaded data with their own data. 3. Nontransportation professionals with some relationship to transportation operations usually have very different scopes of responsibility, such as law enforcement, firefighting, or management of a special event venue. â Primary interests: They would be interested in the end products about operational strategies in incident man- agement, travel time reliability improvement, and special event coordination and collaboration. â Desirable user interface: They need to quickly find any conclusion, results, and strategies that are related to transportation operations, incident management, and travel reliability improvement. This is the user group that will also be very interested in using the online community to communicate with users from other disciplines. 4. Researchers and analysts are interested in understanding transportation operations and in developing innovative approaches to meet operational challenges. â Primary interests: This group of users will be interested in the entire set of Reliability programs. In particular, they want to understand how conclusions and results are derived from each project. Therefore, they will be inter- ested in raw data and research methodologies. Their goals are to verify the research results and try to build and create addenda research programs. â Desirable user interface: Their focus will primarily be on the interface to individual projects. They want to be able to understand the traceability among different parts of the projects from raw data sets to final results.
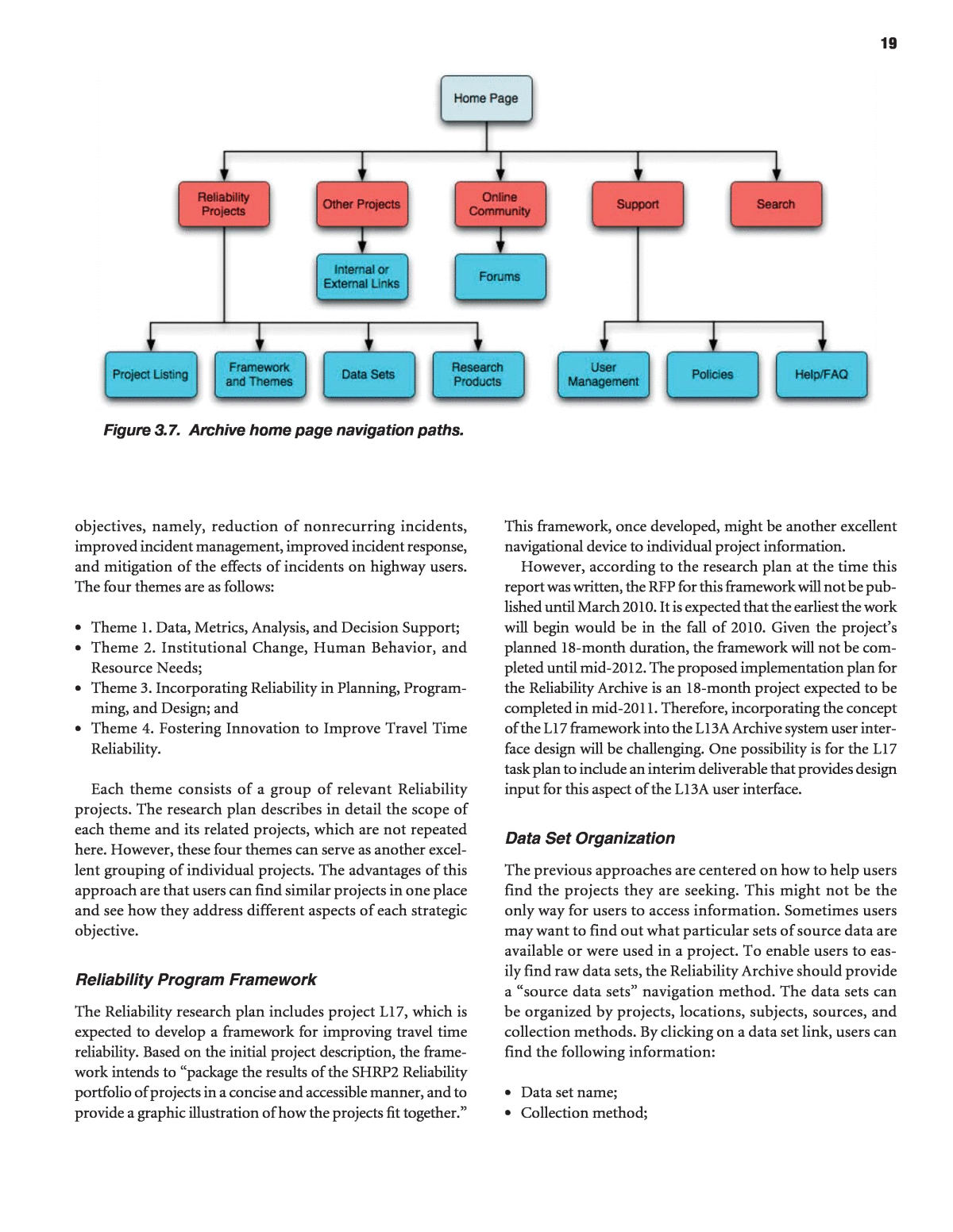
18Lessons from Relevant Systems The research team surveyed a wide range of systems from the transportation sector, other research disciplines, and even con- sumer sites that shape user expectations, to find relevant user interface examples that might inform the conceptual design of the proposed archival system. Appendix D contains informa- tion on those sites and what was gleaned from reviewing them. This review revealed the following general characteristics of these sites: ⢠Almost all provide multiple methods for users to navigate to information. These methods include direct access to data sets, complete or partial views of the data, and access to information from a particular business process or deci- sion point. ⢠When information is deemed to be sensitive, users must be registered to access it. Users are assigned to specific profiles with appropriate privileges. ⢠Collaborative functions that facilitate connections among users are common on most of the websites. A community is an expected âWeb 2.0â feature that is valuable and also relatively easy to implement technically. ⢠Search is one of the most often used approaches for users to find information. Basic and advanced search functions are common. Filtering of outcomes is becoming more preva- lent. Search scope often covers both content and metadata. ⢠Any system providing data access has numerous provisos related to legal information, privacy policy, program dis- claimers, and accessibility aids. Guiding Principles for User Interfaces From the user profile analysis and review of relevant represen- tative systems, the research team identified the following four principles that apply to the proposed archival system generally and to the user interface specifically: ⢠Openness: An open system is one that may be accessed by users operating on differing platforms, other applica- tion languages, and independent network infrastruc- tures. The operational system should not impose any undue restraints on the user regarding hardware, software, and connectivity other than those currently used by the user to access the Internet and that are widely available within the industry. ⢠Zero client administration: The delivered system should not require any special administration on the client side other than the availability of the most basic requirements such as an operating system and a standard web browser. As the operating system continues to grow and mature, it must be able to do so without having to manually modify the client system and/or manually install new software on the client.⢠Expandable: The system must be able to continually grow and expand in both the content and the services it pro- vides. As much as possible, these changes should be trans- parent to the client. New services should be able to come online with little or no impact on existing services. ⢠Easy to use: Finally, the system must be easy to use. Overly complicated user interfaces tend to fall into disfavor and end up not being used. In addition to the above, the user interface of the system must comply with the accessibility standards of Section 508 of the Rehabilitation Act of 1979, thereby insuring that the system can be used by persons with disabilities through the use of various assistive technologies. Conceptual User Interfaces and Requirements The following sections discuss methods various mechanisms might use to navigate and use the system, as a means to define some basic requirements for the user interface. Home Page The home page of an online system typically establishes the top-level navigation scheme for the site. The home page of the archival system should provide various navigation paths to information, as illustrated in Figure 3.7 and explained in the following sections.Navigation of Reliability Research Projects As described earlier, because of their varied roles and respon- sibilities, users will be interested in different aspects of the Reliability products, and the system should provide different and flexible navigation alternatives. Direct Project Lists This approach is similar to the way information is currently organized on the SHRP 2 section of the TRB website. Users can click on a Reliability Project Database link to find lists of Reliability projects. Each project name is another link that will lead to the project information. This navigation mecha- nism would be useful to users already familiar with the SHRP 2 projects, who want to find particular information about a specific project. Reliability Themes The SHRP 2 Reliability research plan defines four subject mat- ter themes. Each of them directly links to the four strategic
19Figure 3.7. Archive home page navigation paths.objectives, namely, reduction of nonrecurring incidents, improved incident management, improved incident response, and mitigation of the effects of incidents on highway users. The four themes are as follows: ⢠Theme 1. Data, Metrics, Analysis, and Decision Support; ⢠Theme 2. Institutional Change, Human Behavior, and Resource Needs; ⢠Theme 3. Incorporating Reliability in Planning, Program- ming, and Design; and ⢠Theme 4. Fostering Innovation to Improve Travel Time Reliability. Each theme consists of a group of relevant Reliability projects. The research plan describes in detail the scope of each theme and its related projects, which are not repeated here. However, these four themes can serve as another excel- lent grouping of individual projects. The advantages of this approach are that users can find similar projects in one place and see how they address different aspects of each strategic objective. Reliability Program Framework The Reliability research plan includes project L17, which is expected to develop a framework for improving travel time reliability. Based on the initial project description, the frame- work intends to âpackage the results of the SHRP2 Reliability portfolio of projects in a concise and accessible manner, and to provide a graphic illustration of how the projects fit together.âThis framework, once developed, might be another excellent navigational device to individual project information. However, according to the research plan at the time this report was written, the RFP for this framework will not be pub- lished until March 2010. It is expected that the earliest the work will begin would be in the fall of 2010. Given the projectâs planned 18-month duration, the framework will not be com- pleted until mid-2012. The proposed implementation plan for the Reliability Archive is an 18-month project expected to be completed in mid-2011. Therefore, incorporating the concept of the L17 framework into the L13A Archive system user inter- face design will be challenging. One possibility is for the L17 task plan to include an interim deliverable that provides design input for this aspect of the L13A user interface. Data Set Organization The previous approaches are centered on how to help users find the projects they are seeking. This might not be the only way for users to access information. Sometimes users may want to find out what particular sets of source data are available or were used in a project. To enable users to eas- ily find raw data sets, the Reliability Archive should provide a âsource data setsâ navigation method. The data sets can be organized by projects, locations, subjects, sources, and collection methods. By clicking on a data set link, users can find the following information: ⢠Data set name; ⢠Collection method;
20⢠Related project; ⢠Location of the data set; ⢠Format and size of the data set; and ⢠Derived data and research results. To assist users in finding the data sets they are interested in, the system can provide a map-based alternative showing the locations of these data sets. If appropriate, geo-locator meta- data could be used in conjunction with an external mapping service such as Google Earth to visualize the locations. Grouping of Research Products As analyzed earlier, a large group of users will be merely interested in the end products of the Reliability program and how to apply them to their day-to-day responsibilities. Therefore, the Reliability Archive user interface should be able to provide these users with a direct access to the end products. From another perspective, as suggested in the SHRP 2 imple- mentation report (5), implementation of Reliability prod- ucts will deliver the most benefits when the products are used together as part of an integrated, systemic approach that includes institutional, analytical, and technological components. There can be different ways to group the end products. One way is to group them according to the following business functions of typical transportation agencies: ⢠Planning; ⢠Design; and ⢠Operations. Alternatively, the products can be grouped according to these detailed subject interests: ⢠Quantitative relationships; ⢠Analytical tools; ⢠Performance measures; ⢠Operational strategies; ⢠Dissemination strategies; ⢠Best practices; ⢠Effective organizational and institutional structures; ⢠Training programs; ⢠Concepts of operations; ⢠Framework; ⢠Business processes; and ⢠Portfolio of innovative ideas. The products may also be grouped in a way that links cer- tain relevant projects. For example, the anticipated Reliabil- ity Project L05, Incorporating Reliability PerformanceMeasures into the Transportation Planning and Program- ming Processes, is to develop procedures for the transportation planning and programming process that demonstrate the ben- efits of operational strategies aimed at improving mobility and reliability. According to its initial work plan, the project will build on the statistical relationships between countermeasures and reliability performance measures developed in Reliability Project L03. In the first phase, the L05 contractor will also develop corridor- and network-level strategies using counter- measures and strategies from Reliability Projects L03, L07, and L11, integrated business processes identified in Reliability Proj- ect L01, and model results from Reliability Project L04, as well as information from other sources. Navigation of Project-Level Data and Results Since the SHRP 2 Reliability program is carried out via indi- vidual projects, project-level navigation is expected to be one of the main navigation paths for users. A significant amount and variety of content might be archived for each project, including raw data, methodologies, and research outputs. One approach for presenting the project information is through simple lists. However, this approach will not best convey the knowledge produced by the project, and as a result will not help users understand the implications of the results; nor will it assist in verifying results or in building new research upon these results. From a knowledge management perspective, it would be more effective for each project to have a home page that pre- sents a project-focused navigation and traceability chart similar to that presented in Figure 3.8. Figure 3.8 illustrates the relationship between different con- cepts, principles, and outcomes from the project. It also shows the traceability of the final results or conclusions drawn from raw data via using the methods, programs, and formulas defined in the project. This approach aligns with the concept of Resource Frame- work Diagram (RFD) technology in the W3 specifications. RFD is intended to link loosely coupled data or contents in order to model and share distributed knowledge. These linkages among objects in the Reliability Archive would be encoded as a kind of descriptive metadata. A mock-up of such a project knowledge map based on Reli- ability Project L03 as an example is shown in Figure 3.9. Other project-level page mock-ups illustrating different modes of information discovery are shown in Figures 3.10â3.12. The mockup shown in Figure 3.10 lists all the raw data sets used in the Reliability Project L03. Users would come to this screen by clicking the âRaw Dataâ item on the left navigation menu. Clicking the details link on an individual item would take the users to a page showing additional details pertaining to that item.
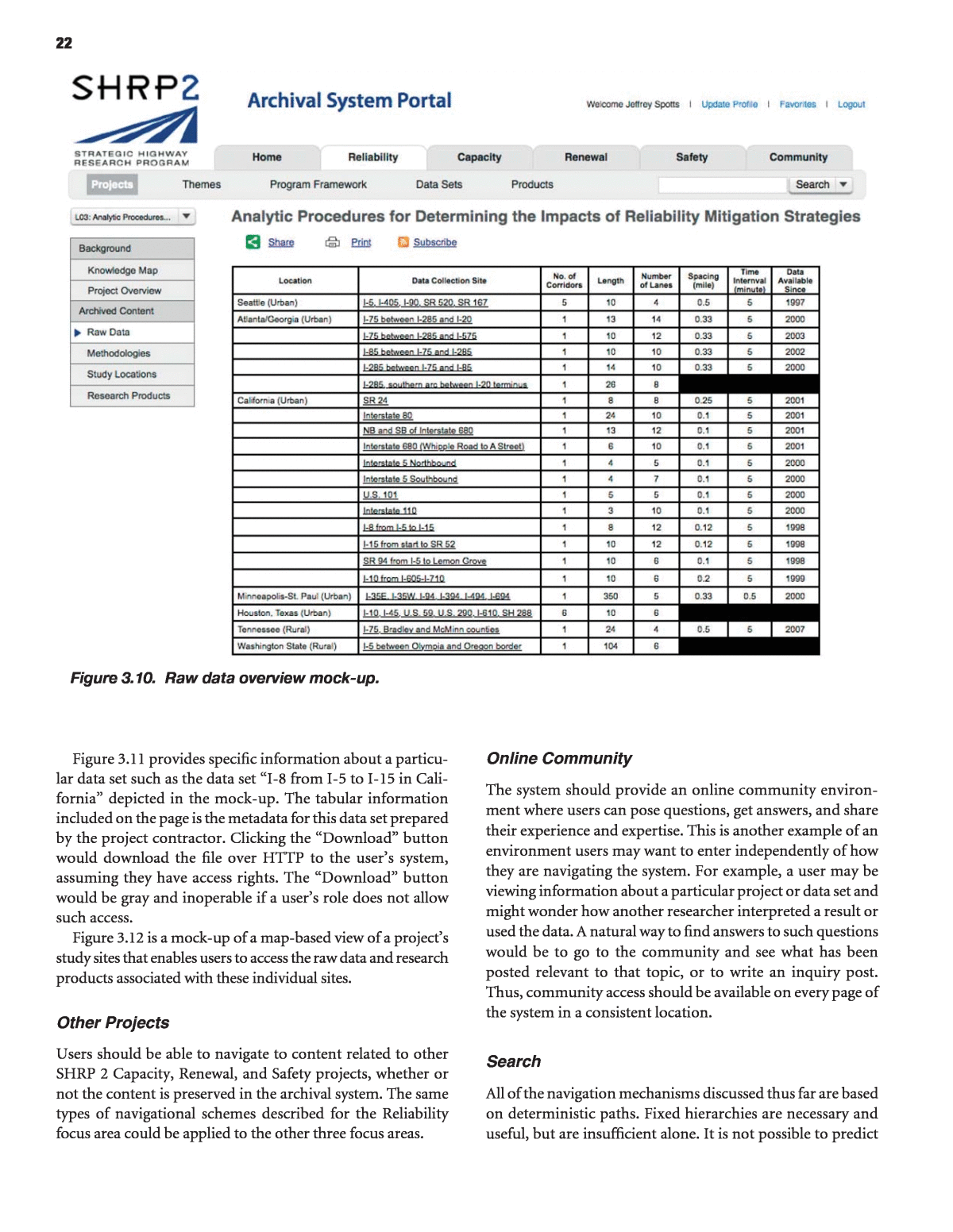
21Figure 3.8. Project-level navigation and traceability.Figure 3.9. Project-level knowledge map mock-up.
22Figure 3.10. Raw data overview mock-up.Figure 3.11 provides specific information about a particu- lar data set such as the data set âI-8 from I-5 to I-15 in Cali- forniaâ depicted in the mock-up. The tabular information included on the page is the metadata for this data set prepared by the project contractor. Clicking the âDownloadâ button would download the file over HTTP to the userâs system, assuming they have access rights. The âDownloadâ button would be gray and inoperable if a userâs role does not allow such access. Figure 3.12 is a mock-up of a map-based view of a projectâs study sites that enables users to access the raw data and research products associated with these individual sites. Other Projects Users should be able to navigate to content related to other SHRP 2 Capacity, Renewal, and Safety projects, whether or not the content is preserved in the archival system. The same types of navigational schemes described for the Reliability focus area could be applied to the other three focus areas.Online Community The system should provide an online community environ- ment where users can pose questions, get answers, and share their experience and expertise. This is another example of an environment users may want to enter independently of how they are navigating the system. For example, a user may be viewing information about a particular project or data set and might wonder how another researcher interpreted a result or used the data. A natural way to find answers to such questions would be to go to the community and see what has been posted relevant to that topic, or to write an inquiry post. Thus, community access should be available on every page of the system in a consistent location. Search All of the navigation mechanisms discussed thus far are based on deterministic paths. Fixed hierarchies are necessary and useful, but are insufficient alone. It is not possible to predict
23Figure 3.11. Project raw data overview page mock-up.all of the ways that future users may wish to seek and connect information. Users should be able to search the archive based on both content and metadata. Since this is a general capability that a user might want to invoke at any point in his or her interaction with the system regardless of the navigation path he or she has taken, the search function should be a capability that would be accessible from anywhere in the access portal independent of any other more structured navigational schemes. The mock- ups serve to illustrate how some of these capabilities might be realized in an actual system. Simple and Advanced Searching Simple searches might be done by typing a keyword or phrase into the search box on the main navigation bar and clicking the Search button, as shown in the Figure 3.13. Instead of clicking the Search button, the user might pull down the combo control and find an Advanced Search option that leads to a page such as that depicted by Figure 3.14, whichwould allow him or her to build a complex search expression. Clicking the plus sign at the end of a line adds a new statement to the expression. (The minus sign would delete a statement.) A similar interface is used in Appleâs popular iTunes software for building so-called Smart Playlists. Viewing and Refining Search Results Independent of the search mode used (simple or advanced), the results of a search would be returned in an interface such as that depicted in Figure 3.15. This example illustrates faceted searching. Additional search facets that are derived from a content and metadata analysis of the result set would appear in the left hand column. Clicking these links in succession would allow the user to filter these results. Customer Support and Administration The system should provide self-service interfaces for rou- tine user management tasks. These include new account
24Figure 3.12. Project study locations page mock-up.Figure 3.13. Simple search box.registration, user profile management, and password reset requests. These user interfaces often provide Help and FAQ content. A common practice for any site providing download- able content is to make visible at the top-level of the site any policy statements with respect to privacy, data rights, warranty disclaimers, and other such policies. Data Integrity and Quality Based on the conceptual design discussed earlier, the data in the Reliability Archive will consist of the data to be preserved and the metadata associated with the archived data. Both types of data are critical to the success of the archive. Thus, it is important to evaluate and control the quality of both. Based on how data are collected, used, and produced by individual Reliability projects, and on how the data are then prepared for, submitted to, and preserved in thearchival system, there are three logical points of data qual- ity control: ⢠Within individual Reliability projects; ⢠Through Reliability Project L16 (now a part of Reliabil- ity Project L13A) (designed to assist Reliability project contractors in preparing their data for submission to the archive); and ⢠By active enforcement of the preservation policy within the archival system. The approach to addressing data quality will vary with the type of data. Figure 3.16 depicts a digital object (in OAIS terms, an Archival Information Package, or AIP) as it might logically exist in the L13A Archive. An AIP in the Reliability Archive will include three types of information: content information; preservation description information; and packaging informa- tion and descriptive information. Content Information This consists of the original data sets or data objects. In this example, it is the VOS data sets collected at the I-8 site. These data sets might be in text, binary, or spreadsheet format. The
25Figure 3.14. Advanced search.Figure 3.15. Viewing and refining search results.
26Figure 3.16. Example of archival information package.quality of this content will be controlled within each individual project. Interviews with the Reliability project contractors indicate that almost all of the projects have robust data quality control standards and processes for the data they collect and produce. For example, the Reliability Project L03 team has developed quality control checks used in the FHWAâs Mobility Monitoring Program for identifying suspect or invalid data that will be applied to all roadway-based traffic measurements. The FHWAâs Traffic Data Quality Measurement report (6) is one of the most common standards used in these projects. This report describes a data quality framework on six funda- mental measures: accuracy, completeness, validity, timeliness, coverage, and accessibility. When a Reliability project is going to deliver the data to be archived, the project contractor is expected to submit the data along with its data quality control standards, methods, and assessment. Reliability Project L16, which is designed to assist Reliability contractors in preparing data for archiving, should review the data quality assessment prepared by the contractor and either confirm or modify the quality rating. Given the wide accep- tance of the FHWA Traffic Data Quality Measurement report, Project L16 should apply the data quality measurement frame- work from this report to evaluate and assign the quality rating on the data delivered by the projects. This quality rating would be a metadata attribute that would be part of the preservation description information (PDI) described next. Project Metadata: Preservation Description Information Preservation description information is the metadata informa- tion to be prepared and collected by individual projects. In the example illustrated in Figure 3.16, this is to clearly identify and understand the environment in which the âVOS Data at the I-8 from I-5 to I-15â (content information) was created. It would include the following information:⢠The source of the data collected; ⢠The context in which the collected data is related to other information from the project; ⢠The reference by which the content information can be uniquely identified; and ⢠The fixity that acts like a wrapper or protective shield, to pro- tect the content information from undocumented alteration. There will be two types of data quality issues with the proj- ect metadata. One is that each project will probably use and collect different metadata elements. The other is that some metadata information may be inaccurate or incomplete. Reliability Project L16 must play a critical role to ensure the quality of the project metadata. For example, L16 should pre- pare detailed guidelines on what core or mandatory metadata must be provided, along with specifications on data quality. A quality control screen should be set up to assess the project metadata. Feedback should be prepared and sent to contrac- tors in case their metadata is not accurate or complete. Once the project metadata passes the data quality screen test, they will be saved to the metadata database in the L13 data archive. System-Generated Metadata: Packaging Information and Descriptive Information System-generated metadata refers to how the data package is stored in the data archive and how it is referred to with respect to its contents. The critical aspects of data quality will still be data accuracy and completeness. L16 is expected to create descriptive information for the data package. The tools or technologies selected for the Reliability Archive will save the descriptive information and also automat- ically generate other system or storage-related information. Table 3.1 summarizes the data quality management process for the Reliability Archive.
27Data in Reliability Reliability Project/ Archive Aspects of Data Quality Contractor Project L16 Reliability Archive System Content data Project metadata System metadata Table 3.1. Data Quality Management Summary Accuracy, completeness, validity, timeliness, cov- erage, and accessibility Accuracy, completeness, and accessibility Accuracy, completeness, and accessibility Provide quality assessment Prepare and submit the project metadata Not applicable Review the quality assessment and assign a quality rating based on the FHWA Traffic Data Quality Measurement framework Set up the project metadata standards and guidelines Screen the quality of the project metadata Create quality descriptive infor- mation Save the rating; data quality and integrity control at the meta- data database level Save the project metadata; data quality and integrity control at the metadata database level Data quality and integrity con- trol at the metadata database level Data Quality ControlData Rights From interviews with the Reliability project contractors, the research team found the following with respect to the issues of data rights: ⢠There are few or no restrictions on the derived data from these projects. ⢠The raw data used in these projects typically come from the contractorsâ existing data sets, a state DOT or other trans- portation agenciesâ detectors and accident data programs, as well as from the private sector. ⢠Currently, about half of the projects have not identified the sources of the data that will be used. ⢠As of the date of this report, it appears that INRIX is the only data provider from the private sector. Its agreement with the Reliability Project L03 contractor includes stipu- lations on the use of raw and derived data. It was equally important to acquire a good understanding on the same subject from the contract administration and legal perspectives of the National Academies and Transportation Research Board. During the project, the research team met with the general counsel of the National Academies to discuss this matter. The discussion mainly centered around Reliability Project L03âs agreement with INRIX with respect to data rights clauses on raw data and derived data. The following summa- rizes the group consensus from the meeting: ⢠The goal of the Reliability Archive is to provide future end users with access to SHRP 2 Reliability project data with- out restrictions. In general, there is no perceived negative impact with respect to data rights affecting the feasibility of building the Reliability Archive.⢠The majority of the raw data used by the Reliability projects comes from the public sector, so it poses no data rights issues. ⢠In any case where there are usage restrictions on raw or base data, the Reliability Archive needs to focus on archiv- ing the derived or aggregated data. ⢠The omission of original base and raw data from the archive might impact the ability of the future end users to efficiently validate the results of a project. In such a case, the project contractor will need to leverage and maximize the utility of metadata to explain how the derived data was aggregated. The knowledge map described earlier can be another means to guide end users in validating the research results. Institutional Framework and Governance Given the size and level of complexity of the Reliability Archive, a proven and reliable institutional framework is warranted in order to provide long-term stewardship of the archive. This section explores a set of key principles that could become the building blocks of this institutional framework. Best Practices of National Systems Numerous national systems similar to the Reliability Archive have been developed. Successful systems all have mature insti- tutional frameworks or governance models with a clear, long- term stewardship mission. These mature frameworks possess the following characteristics: ⢠Clear and well-communicated vision that is shared by stakeholders and participating organizations; ⢠Well-defined multitiered organization structures, roles, and responsibilities;
28⢠Dedicated funding models to ensure the continuity of avail- able funding to support ongoing administration, mainte- nance, and technology upgrade; ⢠Global reach to all possible user groups; ⢠Strong commitment from key stakeholders, dominant industry players, and influential organizations; ⢠Willingness to collaborate with relevant standards develop- ment bodies and professional associations to leverage exist- ing and emerging technologies, standards, and services; and ⢠Clear and enforced policies and procedures that are mon- itored constantly. SHRP 2 Implementation Report The SHRP 2 implementation report (5) includes specific rec- ommendations on the overall strategies for implementing the SHRP 2 research products. These recommendations encom- pass an array of issues, such as who is responsible for imple- menting the results, where and how much funding is needed, and how to set up implementation priorities. The report also discusses potential roles and responsibilities of national trans- portation organizations such as FHWA, TRB, and the Amer- ican Association of State Highway and Transportation Officials (AASHTO). The right direction for the Reliability Archive is to develop its institutional framework under the guidance of these recommendations. Principal Implementation Agent One of the key recommendations of the SHRP 2 implementa- tion report is to establish a principal implementation agent that is a national organization that will lead and support SHRP 2 implementation (5). A similar role should also be established for the archival system. The Reliability Archive principal imple- mentation agent will be responsible for the following tasks: ⢠Implementing the Reliability Archive to a production envi- ronment once its development is completed under SHRP 2; ⢠Long-term managing of the data archive, including system administration, maintenance, and upgrade; ⢠Communicating with the user community on matters such as updates on the implementation and new contents added; ⢠Establishing relevant policies and procedures for using the archival system; and ⢠Maintaining coordination with stakeholders at both the strategic and technical levels. As recommended in the SHRP 2 implementation report, FHWA should serve as the principal implementation agent for SHRP 2, in partnership with AASHTO, National Highway Traf- fic Safety Administration (NHTSA), and TRB. This recommendation is similar to the approach taken with LTPP. Currently, LTPP is administrated and maintained underFHWA with support from contractors who provide technical resources and system production support. This model could be applicable to the Reliability Archive. Stakeholder Advisory Group To support the principal implementation agent, a formal stakeholder advisory group should be established to provide strategic guidance and technical advice on the long-term stew- ardship and use of the archive. This advisory group should operate under the SHRP 2 implementation oversight com- mittee to coordinate overall implementation strategies. The advisory group should include the principal users of the archive and broad stakeholder representation such as leaders of state DOTs, technical staff, nontransportation professionals, academic researchers, as well as experts in information tech- nology and knowledge management. The advisory group should be responsible for the following: ⢠Coordinating with the SHRP 2 implementation oversight committee to ensure that the archive implementation approach aligns with the overall implementation strategies; ⢠Providing both policy and technical guidance to the prin- cipal implementation agent; ⢠Setting priorities for maturing, maintaining, and upgrading the archive; ⢠Developing communication strategies with user groups to maximize the awareness, access, and usage of the archive; and ⢠Monitoring progress on the archive implementation and reporting it to the SHRP 2 implementation oversight committee. Use of Private Sector IT Services A key part of the institutional framework for the archival sys- tem is to ensure that it will be available to users on a 24/7 basis. This requires that system administration and maintenance processes follow rigorous standards, which demands reliable information technology infrastructures and skilled personnel. Although FHWA is an ideal candidate as an implementation agent and has strong IT resources, FHWA is not an IT service shop and does not specialize in providing product system sup- port services. Thus, alternatives need to be explored. A practi- cal option is for system administration and maintenance to be outsourced but managed by the Reliability Archiveâs principal implementation agent. Technical Issues Some specific technical issues were cited explicitly for analy- sis in the L13 Reliability Project RFP. The research team explored the applicability of each technical issue to the Reli- ability Archive. These issues are data normalization and
29denormalization, online analytical processing (OLAP) and user-defined functions, service-oriented architectures (SOA), and virtualization. Normalization and Denormalization The term ânormalizationâ originated in 1970 with the work of E. F. Codd at IBM, considered by many to be the father of the relational database (7). Virtually all modern transactional data- base applications strive to represent data in what Codd called first normal form (1NF), essentially meaning that no table should contain any repeating groups (arrays). Of course, arrays are pervasive in real-world data, so they are handled in rela- tional database systems via relationships between tables. (One row in a master table might be related to N number of rows in a details table, thus obviating the need to fix the maximum number of detail items, which is the case in a denormalized data structure.) As relational databases became widely adopted, perfor- mance problems began to be observed in highly query- intensive applications with fully normalized data models. A recent trend in the database market has been the develop- ment of specialized databases for âread-mostlyâ applications such as OLAP, which employ selective denormalization to speed up query performance. This entire subject area is a large and fairly complex one that can be dealt with here only in summary fashion. The bottom- line question is whether or not data normalization or denor- malization has any application in the proposed archival system. The research team believes that the answer is no, at least in terms of normalizing or denormalizing data postresearch as part of the process of preparing it for preservation. As discussed in Chapter 2, a fundamental purpose of an archive is to preserve unchanged the information entrusted to its care, and to facilitate access to this information when needed. Basic preservation principles argue against such an obvious structural reorganization of data in order to preserve it. That said, an investigator might normalize or denormalize data in the routine course of his or her project. For example, normalized raw data might be the basis for denormalized, aggregate data used in an analytical model. As pointed out previously, all data sets and the relationships among them are important in establishing the traceability of results; thus, all should be part of the collection submitted to the archival sys- tem. Another way of saying this is that normalized and denor- malized data should be able to coexist, and be linked, if appropriate, in the archival system. OLAP and User-Defined Functions The purpose of the Reliability Archive, based on its guiding principles and user requirements, is to serve transportation researchers and decision makers by preserving transportationproject information and facilitating lookup, presentation, and downloading of such information. Therefore, it is not within the scope of the archival system to perform analysis on the stored data, or to perform other open-ended or dynamic user- defined functions on the data. Analyses such as OLAP and user-defined functions are domain-specific and should be addressed by each user based on his or her specific needs. Any attempt to provide such analyses as a function of the archival system would likely miss the mark. They would be costly to build and maintain and, absent any concrete requirements, would likely be ineffective. Beyond the preservation mission of the archive, the appropriate emphasis should be on facili- tating the finding of the correct information and getting it into the userâs hands for any subsequent manipulation. Toward this end, one potentially useful technology is mashups, which are discussed in the following section. Mashups The focus of the Reliability Archive is to provide users easy access to project information, which includes not only SHRP 2 Reliability projects but also other projects from the Capacity, Renewal, and Safety focus areas (some of those projects may have their data and metadata stored in the archival system, while others may have their own storage facilities). In addition, the system may also facilitate the search and downloading of other relevant information outside the SHRP 2 focus areas. As shown in Figure 3.17, the Reliability Archive will poten- tially need to provide access to information from multiple sources. It is likely that users, particularly researchers, will want to aggregate data from the archive, or even aggregate data from the archive with data found elsewhere. This could be achieved by using mashup technologies, which would provide aggre- gated data from the archival system and various other sources. Mashups have the following three fundamental, defining characteristics: ⢠They are lightweight composite applications that employ a web-oriented architecture to provide quick information integration for end users; ⢠They source content or functionality from established systems and have no native data store or content reposi- tory; and ⢠The mashup result is an explicit mixture of source content and functionality, where the sourced content and function- ality retain their original essence or purposes. A mashup environment will enable the construction and use of three fundamental mashup entities: mashup compo- nents, mashups, and mashup applications (see Figure 3.18 for the architecture). A mashup application consists of one or more mashups; a mashup consists of two or more mashup components.
30Figure 3.17. User view of mashup service.Figure 3.18. Mashup reference architecture.Mashup Sources (Information and Function) Mashups source their content and functionality from estab- lished information systems. In the case of the SHRP 2 Relia- bility projects, this would include the Reliability Archive and other relevant information sources, some of which may not be web based. Information Access, Augmentation, and Delivery Non-web-based sources are transformed and made available for mashups. Mashup Assembly The mashup assembly process provides access to mashup components, the means to assemble these components into a mashup, and the ability to preview the result. Mashup assem- bly should also provide search capability of the mashup com- ponents and their metadata.Mashup Visualization Mashup visualization delivers a mashup to its destination, usu- ally a web page, portal, or web-based application. Like the other technical issues discussed in this section, the key question regarding mashups is, Does it have applicability to the Reliabil- ity Archive? The research team found that while it might be applicable (i.e., some prospective users might like the system to provide a general data aggregation service), there was no clear requirement to include such capability in the system. Mashup technology, moreover, would only make the Relia- bility Archive more complex. Not including a mashup service as a requirement today does not of course preclude it from being added to the Reliability Archive at some future date. Service-Oriented Architecture (SOA) SOA refers to a method for systems integration where systems expose functionality as interoperable services. The concept goes back to the first examples of distributed computing systems and is now associated with web services, making the concept prac- tical on a wide scale. Web services provide the capability to inte- grate disparate data by exposing the data as discrete web services accessible over open, standardized protocols. This provides a unified means of accessing information from a diverse set of sources and platforms. Mashups are an example of functionality that can be deliv- ered by the archival system using a SOA. SOA and web services can be expected to play other roles in the Reliability Archive. The search function of the system could span other reposito- ries (known as a federated search) if other repositories expose their indexes as a web service. Similarly, the archival system could expose its index as a web service so that it can be the tar- get of a federated search invoked on another system.
31Virtualization Virtualization is a popular topic today in information tech- nology circles. Virtualization uses software to abstract a hardware environment. It is best known for its application in insulating an operating system from the underlying hard- ware environment. The virtualization software runs on a host operating system, allowing one or more guest operating systems to run on the same hardware platform. This form of platform virtualization is prevalent in server environments for shared hosting and is now quite common on desktop envi- ronments. This application of virtualization is expected to play a role in the deployment of the Reliability Archive, par- ticularly in terms of hosting application software involved in managing the repository, or hosting software that provides user access to the repository. Virtualization is also an interesting possibility for certain archival situations. For example, archivists in museums and libraries who catalog the personal papers of artists, politicians, scientists, and others are now confronting the possibility that the collections donated to their institutions will include remov- able storage media and even complete computer systems, in addition to the usual journals, files, and other paper records they have received historically. Archiving a virtual machine image is a possible means of preserving information and the execution environment on which access to that information depends. This approach to archiving would introduce other prob- lems. Accessing an archived virtual image successfully would now be dependent on having a version of the virtualization software that can run the archived virtual machine image. The attraction is reducing the vicious cycle of format depen- dencies from many (all the applications needed to access data on a given machine) to one (the virtualization software). Although no case has been identified where this technique might be applicable in the Reliability Archive, it could be con- sidered should such a requirement emerge. In storage, virtualization is used to abstract logical storage from physical storage. Some form of storage virtualization could be used in the actual deployment of the proposed archival system, since the technique would facilitate the phys- ical migration of archived content to new storage media over the life of the system. Establishing Solution Alternatives The research team began to map the system requirements against potential solution building blocks and concluded that these requirements fell roughly into three blocks of function- ality connected via some kind of workflow, as described in Figure 3.19.Figure 3.19. Functional blocks of the proposed archival system.The following were identified as critical issues that influ- ence the selection of potential alternatives: ⢠The relative importance of certain system functionality over time; and ⢠The estimated total data volume to be preserved in the archive. Both issues are analyzed in the following sections. Importance of System Functionality Over the expected life of the Reliability Archiveâmore than 25 yearsâthe relative importance of functionality will change (see Figure 3.20). The trustworthiness, reliability, and durabil- ity of archival storage are constants throughout the life of any archive; these are areas where trade-offs should be avoided, if possible. Submissions to the archive will be made by project teams as their respective projects conclude. These submissions will be assessed and then ingested into the archival system. This process will conclude perhaps three years after the system becomes operational; this is thus an area where the long-term sustainability of this functionality is of lesser importance. Content and data management is very important through- out the life of an archive. Arguably, the importance of this function grows over time because this function impacts the curation of the archive and how effectively the information it contains is exploited by practitioners and researchers. Estimated Data Volume of the Archive The overall data volume that has to be managed over the 25-year expected life cycle of the Reliability Archive presents
32Figure 3.20. Relative importance of functionality over time.certain challenges and will influence the ultimate choice of a storage system. Because no SHRP 2 research project is com- pleted yet and many have not even begun, the research team had to come up with a reasonable set of assumptions to build a model for the estimated storage capacity needed in the archival system. This model categorizes each project into one of the follow- ing types: ⢠Type 1: Mostly documents; ⢠Type 2: 50% data and 50% documents; ⢠Type 3: 75% data and 25% documents; and ⢠Type 4: Over 95% data. A capacity âbase valueâ was assigned for each of these types, as shown in Table 3.2. This base value was derived from informa- tion gathered from interviews with all the project contractors. Because some data sets may be stored in XML format, an XML overhead factor was included that takes into account additional space typically needed for encoding binary informa- tion as text in XML files. A metadata factor was also incorpo- rated in the model to account for the need to store metadata for each object. The value of this factor will increase with the level of complexity of the project and the volume of data to be archived. Finally, a headroom factor was provided to ensure that there will be a certain amount of additional space available to satisfy unanticipated storage needs and to ensure the system is running at less than 100% of storage capacity. Figure 3.21 summarizes the estimate of usable storage capacity required. (Usable capacity refers to space needed to store user files. Raw capacity will be higher because of format-Table 3.2. Storage Model Parameters Model Parameters XML Capacity Overhead Metadata Project Type (GB) Factor Factor Type 1: Mostly 100 1% 2% documents Type 2: 50% data 500 5% 7% and 50% documents Type 3: 75% data 1,000 10% 10% and 25% documents Type 4: Over 95% 20,000 15% 15% data Headroom Factor 20%ting overhead, RAID overhead, hot spaces, and other factors, depending on the system implementation.) The research team used 70 TB of usable capacity as the basis of the life-cycle cost estimates across all of the solution alternatives. Solution Components and Implementation Approaches As part of the solution-visioning process, the research team considered a range of potential sources of technology. Can- didate application suites were identified that provided end-
33Figure 3.21. Estimated storage capacity needed for the archival system.to-end coverage of submission, appraisal, ingestion, and data and content management. These suites generally abstracted the interface to the storage tier, thus allowing freedom of choice for the archival storage layer. Within the archival storage tier itself, there were suboptions. The research team also identified can- didate software tools that focused on specific tasks that could be considered as components of a system. In addition to identifying what software and hardware technology might address the functional and operational requirements of the archival system, the research team also needed to consider the question of how the technology could be acquired and implemented. These options include commercial off-the-shelf technology (COTS), open-source software (OSS), in-house software development, hosting, and software and storage as a service (SaaS). The following sections discuss the kinds of solution com- ponents considered, the various technology implementations available, and how the research team analyzed which choices are appropriate for the institutional framework in which the system will be deployed and managed. Commercial Off-the-Shelf Technology COTS technology is software and hardware that is ready- made and available for sale, lease, or license to the general public. The research team considered both COTS software and hardware products as potential sources of technology.Commodity versus Specialized Hardware It is useful to distinguish between commodity hardware (e.g., servers or generic storage) that is readily interchangeable from vendor to vendor, from specialized hardware that is unique to a given vendor (and therefore more proprietary in nature). Open-Source Software Open source has become one of todayâs most popular models of software development. OSS is created and maintained via a collaborative model. Larger open-source projects often have primary sponsors, which include commercial, governmental, and nonprofit entities. Contributors to open source projects may be motivated individuals, but many are employees of technology companies assigned to work on such projects. With OSS, users can go to a trusted repository on the web to obtain a copy of the source code, which is distributed under one of several licenses (e.g., the GNU General Public License, or GPL) that provides users the freedom to run the software for any purpose, to study and modify the source code, and to freely redistribute copies of either the original or modified software without royalty payments or other restrictions on who can receive them. The lines between commercial and open-source software are blurring. Many proprietary software products today incor- porate some components that are licensed under open-source terms. And many OSS packages are available as commercial
34distributions where the distributor adds value in terms of test- ing, integration with other technology, certification on certain hardware, and support. When considering OSS, the research team found it use- ful to distinguish between products that are supported under commercial terms and packages that are only available on a community-supported basis, meaning that users are essentially on their own and have to figure out problems with the assis- tance of the community using that package. In-House-Developed Software Inasmuch as the National Academies and TRB and any likely implementation agent for the proposed Reliability Archive have little to no in-house software development capability, the research team looked at in-house development in the context of this discussion as a potential responsibility of the L13A project contractor. Software and Storage as a Service SaaS has become a popular deployment model for certain software applications. It is based on an on-demand, pay-as- you-go model that eliminates up-front acquisition costs and variable operational expenses. SaaS is often talked about in the context of cloud computing, in which various computing services are made available to the user from the cloud, which is a metaphor for the Internet. A recent development is the availability of cloud storage services from vendors such as Amazon that are based on a similar pay-as-you-use model. These services have addressed enough of the issues and risks relative to security, integrity, availability, and quality of service to be considered for a wide range of storage applications, and there is considerable inter- est in the archiving community in using cloud storage services as part of a long-term preservation strategy. Hosting Hosting is generally understood to mean the operation and maintenance of a computer system on someoneâs behalf as a commercial service. It is a means of deploying and managing software and hardware, whether COTS, OSS, commodity, or proprietary. It is discussed here because it may be applicable to the proposed archival system and because it is important to differentiate between hosting and SaaS/cloud storage. With the latter, the customer (at least theoretically) enjoys cost savings because he or she is using a small fraction of a massive, Internet-scale technology deployment. With hosting, provisioning of hardware is more fixed and hardware is often dedicated to a customer, particularly if the computer and storage requirements are significant. Generally speaking, a customer has more freedom of choice in software components and configuration in hosting than in SaaS and cloud storage. Pros and Cons of These Approaches When the research team considered these different approaches to technology implementation against the backdrop of the insti- tutional framework in which the proposed Reliability Archive is to be deployed, the following conclusions were reached: ⢠In-house software development should be considered only as a last resort and only for limited functionality where the need is short-term. It cannot be considered for core functionality that must be sustainable over the life of the archival system. ⢠Community-supported OSS should be considered only in similar circumstances, since it generally requires developing significant in-house expertise to implement and support it. ⢠COTS software (which may or may not include OSS com- ponents) seems to be the most attractive option for the application and infrastructure software portion of the system because of the availability of commercial support services, eliminating the burden and issues that arise with self-support of either in-house-developed or community-supported OSS. ⢠Cloud storage is a solution component that should be con- sidered if for no other reason than the cost of acquiring and managing storage (including replacing the hardware on a 3â5-year basis), which is likely to be the single largest cost over the systemâs lifetime. ⢠Hosting should also be considered as a technology deploy- ment option principally because it offloads certain opera- tional burdens. Solution Framework The visioning and filtering process the research team went through led to the conceptual solution framework (see Fig- ure 3.22). This builds on the functional blocks concept introduced at the beginning of this section and maps it against the implementation options the team judged to be most viable. The research team identified two different classes of COTS application software that meet most of the end-to-end func- tional requirements of the proposed system (with respect to submission, appraisal, ingestion, and data and content man- agement) and included them in the analysis. The team also identified an OSS tool that could be used to meet a short-term need and could play a role in a simple and straightforward alternative. The team did not consider alternatives that had any long-term dependence on community-supported OSS for the application or storage tiers. With respect to the archival storage tier, the research team generally found that the application-level software abstracted
35Figure 3.22. Solution framework.the interface to the storage tier, thus allowing certain freedom of choice for the archival storage technology. As noted, the expected data volume in the archive will impose practical constraints on the storage options that can be considered. While the archival storage tier may use commodity compo- nents such as SATA drives, the particular requirements of an archival storage system dictate specialized capabilities. With hosted storage, this specialization comes in the form of the embedded software that runs in the filer or storage controller that virtualizes the underlying generic storage devices, makes these subsystems largely self-managing and highly reliable, and facilitates managing physical migrations. In addition, the emergence of robust cloud storage services provides a viable option for archival storage. Using this framework, the research team proposed a number of alternative system solutions, which are described in the following section. Alternative 1 The research team strove to find an alternative that might be described as the bare minimum, meaning that it would be sim- ple and straightforward to implement and meet the minimum, essential requirements to be considered a viable solution (see Figure 3.23). This alternative is based on the use of a hierarchi- cal file system to organize the files from each research project. A directory structure that follows basic naming conventions would establish an implied taxonomic hierarchy. The system is based on simple building blocks and manual processes. The major elements of the system and the workflow through it are as follows: 1. Research project teams would be given log-in credentials and access to specific directories in the archive mapped to their respective projects. For example, the L03 team mightFigure 3.23. Alternative 1 concept.have access to the directory \\root\reliability\L03. They would follow prescriptive guidelines to organize their con- tent locally, and then transfer the files to the appropriate subdirectories in the archive using readily available FTP (file transfer protocol) client software. 2. The âweb clusterâ in this system is simply two commod- ity servers (for redundancy) that provide an FTP service to accept submissions and an HTTP service to support user access, which is discussed in point 5. 3. Archival storage in this alternative would be provided by self-hosted network-attached storage (NAS). NAS uses a special-purpose computer, sometimes called a filer, to provide file-based disk services on a network. The filerâs file volumes are made visible as network shares. The maximum size of a disk volume that a modern, general-purpose NAS can export to the network is 16 TB. (This is the current maximum volume size of NAS market leader Network Appliance (NetApp), which is representa- tive of this class of storage device.) Presenting the archival storage space as multiple volumes is undesirable from both a manageability and user-access point-of-view. Presenting it as a single namespace requires the use of a more special- ized class of NAS or the insertion of Global Namespace technology, or both, usually in the form of an appliance, between the web server and the NAS filers. With a Global Namespace, users access a virtualized file system name- space where the files exist in multiple volumes but appear to be part of a single namespace. There are numerous options available from vendors such as EMC, Hitachi Data Systems, HP, Network Appli- ance, Sun, and others that can address this storage chal- lenge. The point of the preceding discussion is simply to frame the issue for the purposes of the current analytical task. The storage requirements inform the class of storage
36that will be required and allow us to estimate storage acqui- sition, maintenance, and operations costs commensurate with this class of storage. 4. Institutional staff would use an OSS tool such as the Archivist Toolkit (AT) to catalog the files deposited into archival storage. A tool such as AT basically provides a form-based system to catalog descriptive metadata (some- times called writing a finding aid) and then export it in various standard formats, such as METS or EAD (Electronic Archival Description). These exported files could be trans- formed by style sheets into static HTML pages to provide a simple, structured way to browse the file system. The con- cept is to manually publish fixed, top-level maps of the con- tents of the various subdirectories that users might browse, as described in the next point. 5. Access to this system would be based mainly upon direc- tory browsing, a capability supported by all web servers, whereby a user types a URL into their browser and is per- mitted to view and navigate a list of files and directories instead of viewing an HTML page. It is very much like using Windows Explorer or Macâs Finder to browse local disks and network shares; it is simply done using a browser and accessing the archival systemâs directory structure over the Internet. The primary user interface experience might look some- thing like Figure 3.24.Figure 3.24. Browsing a hypothetical directory hierarchy.Alternative 2 The second alternative is based on digital object repository management software designed for universities, libraries, museums, archives, and information centers (see Figure 3.25). This alternative was selected because the functionality pro- vided by these software suites maps very closely to the func- tional requirements and conceptual design of the archival system as presented in Chapter 2. Figure 3.25. Alternative 2 concept.
37The following systems enable institutions to manage digi- tal entities end-to-end, from submission through access, while ensuring their integrity over time through continuous preservation actions: 1. Research project teams would submit content into the repository through a web-based interface. These systems generally employ configurable, form-based templates that allow publishers to upload files, enter metadata, and define access restrictions. 2. Review stages involving configurable automatic, semi- automatic, and manual workflows can be integrated to ensure that institutional staff has the ability to edit, delete, or approve submitted content prior to ingestion into the repository. 3. These applications are designed to manage any content type and typically have a very flexible metadata schema. Metadata is encapsulated with its associated content, usu- ally in standard format such as METS, thus constituting a self-contained and self-describing package that is main- tained in archival storage (see 4). A relational database (RDBMS) such as Oracle is typ- ically used as an operational or runtime database to cache metadata and support web-based publishing and access processes. A key consideration from a sustainability and long-term preservation standpoint is that the runtime database can be rebuilt from metadata embedded in dig- ital objects. The web, application, and database cluster is a small number of self-hosted commodity servers that run the application suite; that is, the processes related to sub- mission, appraisal, ingestion, and data and content management. 4. Digital objects themselves are stored in self-hosted archival class storage under a write-once, read-only policy with object replication to ensure their security and integrity over time. 5. Researchers and practitioners would access the repository from a public access portal functionality that is built into these products. Web publishing is automatic and dynami- cally driven from the repositoryâs metadata. The look-and- feel of the interface would be customized via HTML, CSS, and XML/XSL, and the user experience would be more akin to that depicted in the mock-ups. Users would be able to navigate the repository content through fixed and dynamic classification paths (menus), as well as perform full-text and faceted searches. These systems support user self-registration and various authentication schemes and enforce access control restrictions that are encoded in the administrative metadata.Alternative 3 This alternative is based on the same class of COTS software as Alternative 2; however, the system implementation differs substantially, as depicted in Figure 3.26. The system functionality and topology, in the first three of the following points, are identical to Alternative 2: 1. Research project teams would submit content into the repository through a web-based interface. These systems generally employ configurable, form-based templates that allow publishers to upload files, enter metadata, and define access restrictions. 2. Review stages involving configurable automatic, semi- automatic, and manual workflows can be integrated to ensure that institutional staff has the ability to edit, delete, or approve submitted content before to ingestion into the repository. 3. These applications are designed to manage any content type and typically have a very flexible metadata schema. Meta- data is encapsulated with its associated content, usually in standard format such as METS, thus constituting a self- contained and self-describing package that is maintained in archival storage (see 4). A relational database (RDBMS) such as Oracle is typi- cally used as an operational or runtime database to cache metadata and support web-based publishing and access processes. A key consideration from a sustainability and long-term preservation standpoint is that the runtime database can be rebuilt from metadata embedded in dig- ital objects. 4. The web, application, and database cluster is a small num- ber of self-hosted commodity servers that run the applica- tion suite; that is, the processes related to submission, appraisal, ingestion, and data and content management. In this alternative, instead of residing in self-hosted stor- age, the archived data is preserved using a cloud storage service. Figure 3.26. Alternative 3 concept.
385. Once submitted data have been appraised and approved for ingestion, the metadata-wrapped digital object is written to a cloud storage service. While it is beyond the scope of this document to describe cloud storage services in detail, a few highlights are worth noting. Cloud storage services do not operate like file systems or network-attached storage (NAS), which are mounted or mapped as either physical or virtual disks. Instead, they store and retrieve files via a simple web service (ReST: Representational State Transfer) interface, in essence, pro- viding an object-based storage service. An object is stored and retrieved using a persistent identifier over encrypted communications in conjunction with a session authentica- tion token. Each stored object is replicated within the stor- age cloud for high availability and fault tolerance (three ephemeral copies of an object is typical of these services). At many levels, the model maps well to archival storage requirements. User access to the system is exactly as described for Alter- native 2, except that the digital object repository management software, in its role as trusted intermediary to archived data, retrieves the requested object(s) from a cloud storage service instead of from a self-hosted storage. Other Alternatives Considered The research team considered an alternative solution based upon a category of COTS application software called Enter- prise Content Management (ECM). AIIM (Association for Information and Image Management) defines ECM (8) as âthe strategies, methods and tools used to capture, manage, store, preserve, and deliver content and documents related to organizational processes. ECM tools and strategies allow the management of an organizationâs unstructured information, wherever that information exists.â ECM systems provide a range of functions, which typically encompass at least the following areas: ⢠Document management: Organize documents into hierar- chies of files and folders or compound documents; classify documents by adding metadata; manage document check- in, check-out, and versioning; manage change request, review, and approval workflows; ⢠Records management: Manage document retention and disposition through system-enforced rules; ⢠Digital asset management: Manage digital media and related metadata to support workflows around image, audio, and video file types; and ⢠Image management: Provide paper, fax and e-mail capture, recognition, and routing. Representative products of this class of software include Documentum from EMC, ECM Suite from Open Text,Filenet from IBM, and Oracle UCM (Universal Content Management). The research team considered this alternative because it is a well understood and proven means of managing electronic content within certain functions of some organizations. Upon cursory examination, ECM systems seem to map well to the functional requirements of the Reliability Archive. On deeper examination, a number of key differences or opti- mizations become apparent when compared to digital object repository management software. In general, the following characteristics are typical of ECM systems: ⢠They are optimized for integration into the workflow of existing operational systems instead of being built for stand- alone use. ⢠They have more fixed metadata schemas. ⢠They are primarily document-centric but can manage other content types. ⢠They are typically deployed internallyâi.e., behind a firewall on a corporate Intranet. Web publishing for public access involves add-on products, more hardware, and additional workflows. ⢠They are more complex and cumbersome to implement and maintain, and impose much more application software dependency. An ECM system represents conventional thinking about content-centric applications typical of major technology ven- dors, many of whom have ECM software in their product offerings. These vendors have natural incentives to steer cus- tomers toward solutions they control and that drag substan- tial service revenue. They naturally would propose an ECM solution if given the opportunity. An ECM system would have a virtually identical storage requirement to a digital object repository management system. Software acquisition costs would be significantly higher, as would system integration costs. For these and other reasons the research team decided not to recommend this alternative or analyze its life-cycle costs and benefits. Life-Cycle Costs Analysis This chapter includes the research teamâs estimates on the costs of each alternative archival system, while considering all the life-cycle costs that could be identified over a 25-year period. Assumptions The following assumptions are used to support the costâ benefit analysis on the three selected alternatives: 1. The length of life cycle: This is the time from the begin- ning of a systemâs implementation project to the retire-
39ment and replacement of that system. It includes the time during which the system will be operational as well as the time needed to develop and implement the sys- tem. Using the requirements from the L13 RFP, the research team calculated the life-cycle cost for a period of 25 years. 2. Cost distribution: Costs were estimated for each of the first 5 years (including initial acquisition costs) and then for 5-year increments for the next 20 years. 3. Base year: Following the current SHRP 2 Reliability program schedule, the research team used 2010 as the beginning of the systemâs life cycle. 4. Initial period: Following the current Reliability program plan, the research team assumed that the Reliability Archive would be implemented over a 2-year time frame from 2010 to 2011 and that the system would be in production in 2012. 5. A discount rate was used to relate present and future dol- lars. It is expressed as a percentage and used to reduce the value of future dollars in relation to present dollars. A discount rate of 5% was used for the analysis. 6. The defined alternatives represent types of solutions rather than specific products. Therefore, the cost of future selected products may differ from the estimated costs. However, such differences are not expected to have significant impact on the relevance or comparability of the alternatives. 7. The life-cycle cost considered in this analysis includes costs associated with initial acquisition, operations, and mainte-nance as well as periodic or occasional upgrades to accom- modate technology advances and obsolescence. 8. The cost for the Reliability contractors to enter their proj- ect data into the archival system is not included in this analysis. Reliability Project L16 covers that effort. Data Sources The research team used cost information from a wide variety of sources, including the following: ⢠Vendorsâ websites and other sources in the public domain, including online configuration tools and price lists; ⢠Informal contacts with vendors; and ⢠The team membersâ experience and knowledge. Cost Elements The life-cycle cost considered in this analysis includes the costs associated with initial acquisition, operations, and mainte- nance as well as periodic or occasional upgrades to accommo- date technology advances and obsolescence. Figure 3.27 shows the cost breakdown structure the research team developed for the proposed alternative solutions. It takes into consideration the technical characteristics of these alternatives as analyzed earlier, as well as the current SHRP 2 Reliability program plan.Figure 3.27. Life-cycle cost elements of Reliability Archive solution alternatives.
40Initial Costs or Nonrecurring Costs The initial costs incur during the first two years on a one-time basis. These nonrecurring costs represent the capital invest- ment from the SHRP 2 Reliability program and should be closely tied to the budget of Reliability Project L13A. The initial costs of the L13A Archival system can be grouped into procurement costs and program management costs. Procurement Costs The procurement costs for the Reliability Archive solution may include the following items, depending upon the alternative: ⢠Hardware: The cost to procure necessary hardwareâi.e., servers, workstations, networking, and storage; ⢠Software: The cost to license COTS software; and ⢠Vendor services: The cost for the selected vendors to work with the SHRP 2 Reliability program staff to implement their solutions. It is anticipated that their services will include installation, customization, testing, and deployment. Program Management Costs The program management costs represent the effort of over- seeing the entire Reliability Archive implementation and working with the selected vendors to ensure that their ser- vices and products are properly implemented to fully satisfy the Reliability Archive requirements. The program manage- ment team will represent the SHRP 2 Reliability program and ensure that the SHRP 2 program interests are best protected and realized. The following are the components of the Reliability Archive program management costs: ⢠Project management: The cost to manage the implemen- tation of the Reliability Archive, including schedule mon- itoring, task execution, and working with the vendors on a day-to-day basis. ⢠Submission appraisal: The cost to evaluate and appraise the submissions from individual Reliability project teams so that the information can be properly archived and the metadata can be encoded. ⢠System integration: A key part of the program manage- ment teamâs efforts is to ensure that all components of the solutionâi.e., submission, storage, metadata manage- ment, and content managementâare properly integrated. This is the cost of these efforts. ⢠System testing: The cost of performing acceptance tests on the solutions implemented by the vendors to ensure that all requirements are fully satisfied.⢠Marketing and communication: The cost of communication with user communities on services provided by the Reliabil- ity Archive. The efforts will include newsletters, project web- site, and conference presentations. Estimation of the program management cost was based on a basic project management team that includes roles such as project manager, technology specialists, archivists, analysts/developers, and quality assurance. The level of effort may vary from one alternative to another, depending on complexity. Recurring Costs Recurring costs are the continuing costs associated with the management and operation of the archival system. Recurring costs apply over a period of time throughout the systemâs life. In this analysis most of the recurring costs are incurred over a period of 23 years from 2012 to 2035. Those that also apply during the initial period follow. System Operations and Maintenance Costs The recurring system operations and maintenance costs for the L13 archival solution include the following cost items: ⢠Hardware maintenance: The cost to troubleshoot, replace, or repair hardware. This cost typically begins to accrue 90 days after hardware installation, so it must be accounted for during the initial period as well as over the operational life of the archival system. ⢠Hardware upgrade and replacement: The cost to regu- larly upgrade or replace acquired hardware to accommo- date obsolescence, advances in technology, and growth in number of users. This cost is assumed to be incurred every 5 years. ⢠Software upgrade: The cost associated with software up- grades and replacement. This cost is also assumed to be incurred every 5 years. ⢠Software maintenance: The cost of obtaining product sup- port and access to software fixes and updates from the ven- dor. This cost typically begins to accrue from 90 days to one year after software installation, so it must be accounted for during the initial period as well as over the operational life of the archival system. ⢠Hosting: The cost to house, power, cool, and physically maintain any archival system hardware, whether a fee from a commercial service or a chargeback from an implemen- tation agent. These costs accrue once any hardware is installed, so they have to be accounted for during the
41initial period as well as over the operational life of the archival system. ⢠Storage service: The usage cost of a commercial cloud stor- age service, such as Amazon S3. The cost is based on data storage capacity used, plus the amount of data transfer in and out of the service. The estimates of this cost are based upon the expected data capacity growth over time. Initial data transfer expense will relate to ingestion into the archive and later to data downloaded by users. Program Management Costs The success of the Reliability Archive implementation will depend on continued program support. This warrants a small-scale focus team dedicated to the support task. The following, then, are the estimated cost items for program management: ⢠System administration: The cost of administering, manag- ing, and monitoring the operations of the archiving system on a daily basis. ⢠Customer service: The cost of providing services to address the needs or issues users encounter in using the system. ⢠Marketing and communication: The cost of promoting the services of the archival system. The typical efforts will include newsletters, conference presentations, and coordination with other programs. Life-Cycle Costs of the Alternatives The life-cycle costs of the three alternatives are summarized below. Worksheets that provide supporting details behind the initial and recurring costs can be found in Appendix B.The tables in this section show the cost breakdown for a 25-year life cycle. Costs are shown on an annual basis for the first 5 years and thereafter in 5-year intervals. Shaded areas represent cost items that are not applicable to the specific life- cycle periods. Alternative 1 This bare minimum alternative (see Table 3.3) focuses on pre- serving the data and providing a minimally acceptable level of user access. The level of manual effort involved in system implementation accounts for these costs being the highest among the three alternatives.Alternative 2 The second alternative (see Table 3.4) has essentially the same storage-related costs as Alternative 1 but adds licensing costs for COTS application software and system software (e.g., RDBMS) that deliver considerably more functionality than Alternative 1. Estimated system implementation costs are lower because much of the effort will involve configuring out- of-the-box functionality. Other hardware costs are marginally higher because more servers are required to run the application functionality that is not present in Alternative 1.Alternative 3 The final alternative (see Table 3.5) would offer the same functionality as Alternative 2, but with no cost over the life cycle of the system for procurement, installation, mainte- nance, and replacement of storage hardware. Estimated sys- tem administration costs are also lower because there is no storage hardware to manage.
42 Table 3.3. Al Di 2014 2015â2019 2020â2024 2025â2029 2030â2035 Year 5 Years 6â10 Years 11â15 Years 16â20 Years 21â24 Initial Cost ($) Hardware Software Implementat Recurring Cos 958,000 $2,750,000 $2,750,000 $2,750,000 $2,750,000 Annual Cost System Adm 170,000 $850,000 $850,000 $850,000 $850,000 System Main 102,000 $510,000 $510,000 $510,000 $510,000 Marketing an 170,000 $850,000 $850,000 $850,000 $850,000 Hosting $6,000 $30,000 $30,000 $30,000 $30,000 Storage Serv $â $â $â $â $â Periodic Cos Software Up $â $â $â $â $â Hardware Up 510,000 $510,000 $510,000 $510,000 $510,000 Summary Total Cost ($ 958,000 $2,750,000 $2,750,000 $2,750,000 $2,750,000 Number of P 5 6 11 16 21 Total Cost ($ 750,618 $2,052,092 $1,607,868 $1,259,807 $987,092 Total Initial C (Present V two years Total Life Cy (Present V from 2012ternative 1 Life-Cycle Cost Summary scount Factor 2010 2011 2012 2013 5% Year 1 Year 2 Year 3 Year 4 $1,002,600 $515,000 $0 ion $243,800 $243,800 t ($) $108,000 $278,000 $448,000 $448,000 $ s inistration $â $170,000 $170,000 $170,000 $ tenance $102,000 $102,000 $102,000 $102,000 $ d Customer Services $â $â $170,000 $170,000 $ $6,000 $6,000 $6,000 $6,000 ice (Capacity and Access) $â $â $â $â ts grade grade $ ) $1,110,600 $278,000 $448,000 $448,000 $ eriods (Years) 1 2 3 4 , Present Value) $1,057,714 $252,154 $386,999 $368,571 $ ost ` $1,309,868 alue, first 2010 and 2011) cle Cost $7,413,047 alue, 23 years to 2035)
43 Table 3.4. Altern Discou 4 2015â2019 2020â2024 2025â2029 2030â2034 5 Years 6â10 Years 11â15 Years 16â20 Years 21â25 Initial Cost ($) Hardware Software Implementation Recurring Cost ($) 00 $2,920,000 $2,920,000 $2,920,000 $2,920,000 Annual Costs System Administr 00 $850,000 $850,000 $850,000 $850,000 System Maintena 00 $670,000 $670,000 $670,000 $670,000 Marketing and Cu 00 $850,000 $850,000 $850,000 $850,000 Hosting 00 $30,000 $30,000 $30,000 $30,000 Storage Service (C $â $â $â $â $â Periodic Costs Software Upgrade $â $â $â $â $â Hardware Upgrad 00 $520,000 $520,000 $520,000 $520,000 Summary Total Cost ($) 00 $2,920,000 $2,920,000 $2,920,000 $2,920,000 Number of Period 5 6 11 16 21 Total Cost ($, Pre 26 $2,178,949 $1,707,264 $1,337,686 $1,048,112 Total Initial Cost (Present Value two years 2010 Total Life Cycle C (Present Value from 2012 to 2ative 2 Life-Cycle Cost Summary nt Factor 2010 2011 2012 2013 201 5% Year 1 Year 2 Year 3 Year 4 Year $1,041,850 $525,000 $170,000 $173,425 $173,425 $140,000 $310,000 $480,000 $480,000 $1,000,0 ation $â $170,000 $170,000 $170,000 $170,0 nce $134,000 $134,000 $134,000 $134,000 $134,0 stomer Services $â $â $170,000 $170,000 $170,0 $6,000 $6,000 $6,000 $6,000 $6,0 apacity and Access) $â $â $â $â e $520,0 $1,181,850 $310,000 $480,000 $480,000 $1,000,0 s (Years) 1 2 3 4 sent Value) $1,125,571 $281,179 $414,642 $394,897 $783,5 $1,406,751 , first and 2011) ost $7,865,075 , 23 years 035)
44 Table 3.5. Al D 2014 2015â2019 2020â2024 2025â2029 2030â2034 Year 5 Years 6â10 Years 11â15 Years 16â20 Years 21â25 Initial Cost ($) Hardware Software Implementat Recurring Cos 434,200 $2,091,000 $2,091,000 $2,091,000 $2,091,000 Annual Cos System Adm $85,000 $425,000 $425,000 $425,000 $425,000 System Main $34,000 $170,000 $170,000 $170,000 $170,000 Marketing an 170,000 $850,000 $850,000 $850,000 $850,000 Hosting $1,200 $6,000 $6,000 $6,000 $6,000 Storage Serv 124,000 $620,000 $620,000 $620,000 $620,000 Periodic Co Software Up $â $â $â $â $â Hardware Up $20,000 $20,000 $20,000 $20,000 $20,000 Summary Total Cost ($ 434,200 $2,091,000 $2,091,000 $2,091,000 $2,091,000 Number of P 5 6 11 16 21 Total Cost ($ 340,207 $1,560,336 $1,222,564 $957,911 $750,548 Total Initial (Present V two years Total Life Cy (Present V from 2012ternative 3 Life-Cycle Cost Summary iscount Factor 2010 2011 2012 2013 5% Year 1 Year 2 Year 3 Year 4 $541,850 $25,000 $170,000 ion $173,425 $173,425 t ($) $71,200 $192,200 $414,200 $414,200 $ ts inistration $â $85,000 $85,000 $85,000 tenance $34,000 $34,000 $34,000 $34,000 d Customer Services $â $â $170,000 $170,000 $ $1,200 $1,200 $1,200 $1,200 ice (Capacity and Access) $36,000 $72,000 $124,000 $124,000 $ sts grade grade ) $613,050 $192,200 $414,200 $414,200 $ eriods (Years) 1 2 3 4 , Present Value) $583,857 $174,331 $357,802 $340,763 $ Cost $758,188 alue, first 2010 and 2011) cle Cost $5,530,132 alue, 23 years to 2035)
45References 1. Ganz, J. F., D. Reinsel, C. Chute, W. Schlichting, J. McArthur, S. Minton, I. Xheneti, A. Toncheva, and A. Manfrediz. The Expand- ing Digital Universe: A Forecast of Worldwide Information Growth Through 2010. IDC, Framingham, Mass., March 2007. www.emc. com/collateral/analyst-reports/expanding-digital-idc-white- paper.pdf. Accessed March 2, 2011. 2. Peterson, M., G. Zasman, P. Mojica, and J. Porter. 100 Year Archive Requirements Survey. Storage Network Industry Association, San Francisco, Calif., Jan. 2007. www.snia.org/forums/dmf/ programs/ltacsi/forums/dmf/programs/ltacsi/100_year/100YrATF_ Archive-Requirements-Survey_20070619.pdf. Accessed March 2, 2011. 3. Reference Model for an Open Archival Information System. Recom- mendation for Space Data System Standards (OAIS). Consultative Committee for Space Data Systems 650.0-B-1. Blue Book. Issue 1.Washington, D.C., Jan. 2002. http://public.ccsds.org/publications/ archive/650x0b1.pdf. Accessed March 2, 2011. 4. Library of Congress. Metadata Encoding & Transmission Standard. www.loc.gov/standards/mets. Accessed March 2, 2011. 5. Special Report 296: Implementing the Results of the Second Strate- gic Highway Research ProgramâSaving Lives, Reducing Conges- tion, Improving Quality of Life. Transportation Research Board of the National Academies, Washington, D.C., 2009. http://onlinepubs .trb.org/Onlinepubs/sr/sr296.pdf. Accessed March 2, 2011. 6. Battelle. Traffic Data Quality Measurement. Final Report, BAT 03- 007, Federal Highway Administration, Sept. 15, 2004. http://isddc .dot.gov/OLPFiles/FHWA/013402.pdf. Accessed March 2, 2011. 7. Codd, E. F. A Relational Model of Data for Large Shared Data Banks, Communications of the ACM, Vol. 13, No. 6, June 1970, pp. 377â387. 8. Association for Information and Image Management. What is Enter- prise Content Management (ECM)? www.aiim.org/What-is-ECM- Enterprise-Content-Management.aspx. Accessed March 3, 2011.
