
4
Models for Public Engagement
“Multiple communities require multiple approaches.” —Paul Harris, Vanderbilt University
The Avon Foundation for Women has a strong commitment to breast cancer research, and, in the past 5 years, has supported some 350 research studies. In October 2008, the Foundation joined with the Dr. Susan Love Research Foundation to launch the Love/Avon Army of Women project.2
Because recruiting even 50 volunteers for a clinical trial can be a lengthy process, the Army of Women was conceived as a way to create a large, demographically diverse pool of women interested in participating in breast cancer research, said Marc Hurlbert, Executive Director of the Global Breast Cancer Programs of the Avon Foundation for Women and the Avon Breast Cancer Crusade. By making it easier for researchers to recruit study participants, project managers hoped that more prevention studies will be conducted overall and more will be conducted in women, rather than in mice or in vitro.
As of July 2011, the Army of Women project has attracted more than 356,000 registrants, adding approximately 1,500 new recruits each month. In its first two and a half years, the Army of Women has helped investigators recruit volunteers for 44 research studies, and 24 research teams are using the Army of Women website for participant recruitment.
![]()
1 Material in this section is based on the presentation by Marc Hurlbert, Executive Director of the Global Breast Cancer Programs of the Avon Foundation for Women and the Avon Breast Cancer Crusade.
2 See: http://www.armyofwomen.org/.
Those who join the Army of Women receive an email every few weeks describing research participation opportunities. If they are interested and meet the eligibility criteria, they contact the Army of Women, answer brief screening questions, and, if appropriate, their names are provided to the researcher for follow-up. Scientists must apply to the Army of Women for the opportunity to recruit volunteers from its pool, and every study undergoes a rigorous scientific, safety, and ethical review. When the study is over, researchers are required to present their results via a video or blog on the Army of Women website.
The demographic profile of the women who have volunteered is as follows:
• 86 percent have never had breast cancer.
• 74 percent have no family history of breast cancer.
• Half are between ages 40 and 59.
• 86 percent are Caucasian.
• Some 10,680 are African American, an equal number are Hispanic, and about 3,560 are Asian.
Hurlbert reported recent examples of how researchers are using the Army of Women database to recruit participants, including
• a study of methylation in breast tissue hormones, which needed 300 healthy women for core biopsies (an invasive procedure) and other tests; this request generated responses from 739 women, and the study has already recruited 425;
• a study looking for biomarkers in breast milk, which needed 250 lactating women who had been asked by their physician to have a breast biopsy to assess “something suspicious” (a relatively rare occurrence); the request generated such a large response that the researchers were able to quickly recruit 334 women, shorten the study’s recruitment timeline from 6 months to less than a week, add to the study questions, and expand the recruitment target to 2,000; and
• a third study needed to recruit 100 Latina women for a study of breast cancer survivors’ quality of life; it received responses from 125 Army of Women volunteers, only 5 of whom were ineligible, enabling the researchers to expand the study 20 percent.
23andMe is a for-profit company that describes itself as a “direct [to] consumer genetics company” that customers interact with through a website.4 A customer sends a saliva sample to the company for analysis, and, in 6 to 8 weeks, receives information about the genetic variants in his or her genotype and their implications for health. Customers are encouraged to share the results with their physician, said Brian Naughton, Founding Scientist, 23andMe, and genetic counseling is available. 23andMe builds “site stickiness” by providing engaging tools and information people can use in the analysis and understanding of their genetic information.
23andMe also engages with its customers through online surveys focused on everything from exercise and lifestyle to the presence of specific diseases, said Naughton. When customers answer a question such as, “Have you ever taken a nonsteroidal anti-inflammatory drug?” they receive immediate feedback about how many people in the database answered as they did.
More than 100,000 people are in the 23andMe database (as of July 2011), and more than 60,000 of them have taken at least one survey. People who have taken any surveys have taken, on average, 10, for a cumulative 20 million data points. They receive no reward for completing surveys, but participate out of an apparent desire to be part of a community.
The web is a convenient platform for administering long surveys because the answer to one question can automatically eliminate a whole series of questions that would be irrelevant to that individual. Although there are likely to be errors in data self-reporting, the size of the sample may in some cases minimize that. (The statistical power lost from self-reporting is highly dependent on the phenotype being studied, and for some conditions, such as schizophrenia, self-reporting may not work very well, said Naughton.)
According to Naughton, 23andMe is becoming useful for several types of clinical research. The surveys provide a rich database of potential associations that may reveal information about how environment, behavior, and other factors can affect gene expression. The genetics database enables efficient identification of people with specific genetic profiles. Or, studies can start with a pool of people having a known disease and look for previously unrecognized shared genetic characteristics.
23andMe has found that the most effective way to recruit its customers, particularly when it is trying to increase the pool of people with cer-
![]()
3 This section is based on the presentation by Brian Naughton, Founding Scientist, 23andMe.
4 See http://www.23andme.com/.
tain diseases, is to work with disease advocacy groups, Naughton said. For example, the firm worked with the Michael J. Fox Foundation for Parkinson’s Research and, with its help, has now recruited some 5,000 people with Parkinson’s disease, more than 85 percent of whom have completed the Parkinson’s disease survey. It now has the world’s largest database of people with the LRRK2 genetic mutation (which greatly increases the likelihood of developing Parkinson’s disease). This resource is enabling tentative identification of potentially new genetic associations that may increase understanding of the disease.
As examples of how 23andMe can work, according to Naughton:
• When a pharmaceutical company requested research on dry eye syndrome, 23andMe posted a survey on its website to find people in its database who have this condition. It received 900 responses in one week and 8,000 responses to date. Now, 23andMe is able to contact those who reported severe dry eye symptoms to ascertain whether they would be interested in taking part in a clinical research study on the condition.
• For a pharmaceutical company interested in the genetic factors contributing to skin aging, 23andMe obtained 1,600 responses to a nontargeted survey within 90 days.
• For a study on hair loss, 23andMe analyzed data from 13,000 customers; the analysis replicated all known genetic associations, found three novel ones associated with male pattern baldness, and identified a suggestive association that may predict drug response. Administering the survey online was especially helpful, because it could show respondents pictures of different degrees of hair loss, in order to obtain more precise results.
• For a study of people over 80 who are carriers of the APOE e4 mutation for Alzheimer’s disease, 23andMe recruited 127 patients in the first week.
As with the Army of Women project, 23andMe provides its community members with information on the results of studies in which they participated. This feedback is believed to be very important in creating incentives for future participation and for building the patient, or customer, base. For example, Naughton said that in just a few days after results of the Parkinson’s disease research were released, 100 more Parkinson’s patients joined 23andMe.
23andMe researchers have compared their results with those of large, multicenter trials. For example, two NIH-funded trials (Neumann et al., 2009; Sidransky et al., 2009) found that having a mutation in the GBA gene
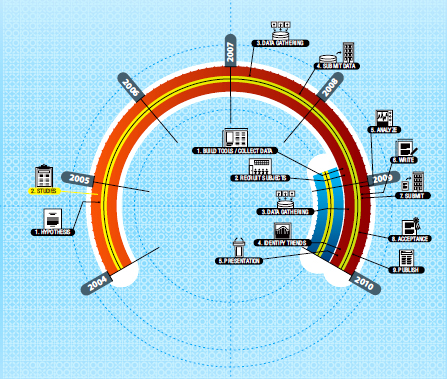
FIGURE 4-1 A timeline comparing a conventional NIH clinical trial versus the 23andMe research model. The orange and red semi-circle depicts a conventional NIH trial from hypotheses generation (step 1) through publication of trial results (step 9). The blue circle segment depicts the 23andMe research model from the building of tools and collecting of data (step 1) through presentation of research results (step 5). The conventional NIH trial took 6 years as compared to just over 1 year for the full application of the 23andMe research model in this example. SOURCE: Goetz, T. 2010. Sergey Brin’s Search for a Parkinson’s Cure. Wired Magazine. http://www.wired.com/magazine/2010/06/ff_sergeys_search/all/1 (accessed September 7, 2011). Reprinted with permission from Wired Magazine and Dominik Schulz.
increases the risk of Parkinson’s disease by a factor of 5. Analysis of the 23andMe database reached the same conclusion. The two NIH-funded trials took 6 years from inception to publication (Figure 4-1). Using 23andMe, recruitment of patients, analysis of saliva samples, and attainment of results took 8 months. Of course, said Naughton, the 23andMe study uses self-report, versus clinician testing, and it only needed statistical power sufficient to replicate existing knowledge rather than to
discover new information. But, he said, it is a tantalizing foretaste of how a trial can happen more quickly—and less expensively.
Naughton added that 23andMe has sufficient data to make new genetic associations, as it did for Parkinson’s disease, not merely replicate existing studies, depending on the phenotype, and the number of people in the database with a particular condition.
Vanderbilt University and its sister CTSA institution, Meharry Medical College, use a number of web-based approaches for patient recruitment, engaging faculty and staff and creating public awareness of clinical studies. Among them is a collaboration project called ResearchMatch (www.researchmatch.org), which, said Paul A. Harris, Associate Professor, Department of Biomedical Informatics, Vanderbilt University, was born out of the simple philosophy that there are people in the community who want to be involved in trials. Although traditional methods often can enroll people in studies and trials only with great difficulty, Vanderbilt staff recognized that there was an unmet need to connect people who want to participate in clinical trials with researchers looking for volunteers.
The Vanderbilt team started by building a local registry, and in the past few years they have expanded it nationwide to serve the entire 61-member CTSA program. ResearchMatch is free to both volunteers and researchers, and it complements, but does not replace, other recruitment methods.
A potential volunteer who finds out about ResearchMatch registers on its website. Adults can register their children or elderly relatives living in their home. The registrant is asked basic intake information, about common inclusion and exclusion criteria, and about medical history and medications. One data point entered is street address, from which the software automatically calculates the registrant’s distance from CTSA-participating institutions. People can type in their responses in their own words and the system translates it into a structured vocabulary. For example, the person’s “heart attack” becomes the system’s “MI.”
Investigators must go through a specific process to gain approval to use the ResearchMatch database for recruitment. Once an investigator has received permission to recruit for a particular study, ResearchMatch’s
![]()
5 This section is based on the presentation by Paul A. Harris, Associate Professor, Department of Biomedical Informatics, Vanderbilt University.
simple filtering mechanism provides information about how many candidates fitting the specific criteria are in the database.
When this anonymized pool of registrants is deemed sufficient, the researcher sends an IRB-approved message to each individual in the pool. If prospective participants agree to participate, their identity is revealed, and the consent and educational processes proceed as in any other study.
As of July 2011, approximately 16,000 people were in the Research-Match database. Race and ethnicity data were similar to the population as a whole, although the ratio of women to men was approximately 3:1. About half the enrollees reported no health conditions and thus are potential controls. As of July 2011, 743 researchers were using ResearchMatch resources in the conduct of 268 active studies. Not only has the system worked at Vanderbilt, but, Harris said, comments from CTSA sites indicate the system is also working elsewhere.
The next step for the project is to evolve it from a disease-neutral-only framework to one that includes subsets of people with specific diseases. In addition, the development team is looking at the stakeholders’ unmet needs. For example, patients and families may need information about an illness, they may need direction, or they may want a voice in the research community. Similarly, researchers also may need more information and may be able to serve as a source of information for participants and families. Finally, there may be additional stakeholders that are not involved yet—foundations, advocacy groups, and others—with needs that a simple-to-use tool like ResearchMatch could meet. Conceptually, the ResearchMatch system need not be limited to CTSA institutions. Because the service currently is offered at no cost, expansion to other institutions would require some consideration of whether it can be scaled out effectively. In the long term, said Harris, the impact of ResearchMatch will depend on investments at the institutional level—especially support for liaisons and development of community relationships built on trust that will encourage people to register.
This page intentionally left blank.








