
5
Controlling Usage of Collected Data
5.1 WHY IT IS IMPORTANT TO CONTROL USAGE
Many people are concerned about how the large and rapidly growing amount of private data that exists online is handled, and whether privacy and civil liberties are properly protected. For signals intelligence (SIGINT), these concerns increase because the data is collected by the government. The disclosures by Edward Snowden have further increased concerns about the privacy of information that the National Security Agency (NSA) collects.
This chapter describes a number of ways to implement controls on the use of collected information. NSA is already using some of them, as the committee learned when the agency described in briefings how it complies with the legal authorities that govern its activities. NSA may be using other controls that the committee did not hear about, but there may also be opportunities to make compliance with the rules both more efficient and more transparent without increasing the compliance burden on analysts.
In understanding the security of any computer system, it is important to be clear about the “threat model,” that is, the set of threats that the system must be defended against. In the context of bulk collection, there are three broad classes of threats:
• Entities outside the Intelligence Community (IC): hackers, cyber-criminals, foreign intelligence agencies;
• Lone insiders within the IC; and
• Misuse of the IC’s capabilities, contrary to law or stated policies.
The last two are the main threats for most people concerned about privacy and civil liberties. Hence, the emphasis of this report is on controls, oversight, and transparency, which are the principal ways to address these threats.
Chapter 4 states the committee’s conclusion that refraining entirely from bulk collection will reduce the nation’s intelligence capability and that there is no kind of targeted collection that can fully substitute for all of today’s bulk collection. However, the committee believes that controlling the usage of data collected in bulk (and indeed all data) is another way to protect the privacy of people who are not targets (see Figure 5.1).
Controls on usage can help reduce the conflicts between collection and privacy. There are two ways to control usage: manually and automatically. NSA automates some of its controls and plans additional automation. Despite rigorous auditing and oversight processes, however, it is hard to convince outside parties of their strength because necessary secrecy prevents them from observing the controls in action, and because popular descriptions of the controls are imprecise and sometimes wrong.1 Examples of usage controls in place today are minimization (Section 1.4.1) and restricting queries to targets with reasonable and articulable suspicion (Section 1.4.3).
Technical means can isolate collected data and restrict queries that analysts can make, and the way these means work can be made public without revealing sources and methods.
This is similar to the well-established doctrine in cryptography2 that the security of the system should depend only on keeping the cryptographic key secret, not on keeping the cryptographic algorithm secret. The main reason for this is that the algorithm exists in many more places than the key—with every sender or receiver of messages that uses the cryptosystem—so it is much harder to keep the algorithm secret and to change it if it is compromised. In contrast, a key is usually used only between a single sender and receiver, or at most a few of them, and only for a limited time, so it is much easier to keep it secret and to change it if it is compromised. In addition, a public algorithm may be more secure because many people can scrutinize it for weaknesses.
______________
1 See, for example, this newspaper account of President Obama’s description of NSA practices: http://www.washingtonpost.com/world/national-security/obamas-restrictionson-nsa-surveillance-rely-on-narrow-definition-of-spying/2014/01/17/2478cc02-7fcb-11e3-93c1-0e888170b723_story.html, Washington Post, January 17, 2014.
2 First formulated by Kerckhoff in 1883. See Fabien Peticolas, electronic version and English translation of “La cryptographie militaire.”
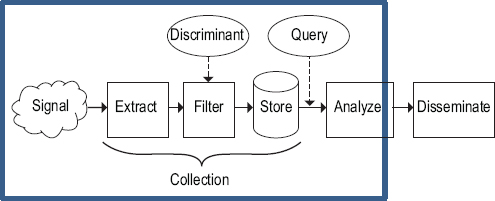
FIGURE 5.1 Focus of controls on usage.
In the same way, the specifics of actual use cases would be kept secret while the rules and the usage controls that enforce them are made public. This transparency makes the control of usage more credible.
Implementing usage controls in technology also forces those specifying the rules to be much more explicit than if they are providing instructions for human analysts to follow. Today, many of the descriptions for what is and is not allowed are in certain ways imprecise and ambiguous. Such ambiguities can lead to confusion and differing interpretations of the same rule. Furthermore, automatic controls may reduce the need for human labor implementing manual controls. Thus, technology may make the control more reliable and economical as well as more transparent.
It is impossible, however, for technical means to guarantee that information is not misused, because someone with properly authorized access can always misuse the information they obtain. This is like the “analog hole” in digital media; there are many ways to prevent digital copying, but when a human views or hears information, that information can be copied with a camera or sound recorder. Similarly, when an analyst sees information, he or she can misuse it. Thus misuse can only be deterred by the threat of punishment. Deterrence requires technical capabilities to detect access, to identify the (authorized) accessing party, and to audit records of access to spot suspicious patterns of access.3 In addition, both
______________
3 Note that, to date, the only allegations that information collected in bulk has been used for an unauthorized purpose was the so-called “LOVINT” set of incidents in which some NSA analysts inappropriately used this data to track the activities of significant others.
manual and automatic controls are primarily aimed at analysts and others not in positions of authority. Detecting bad behavior by people in positions of authority needs multiple independent audit paths and oversight.
Lastly, it may be true that manual controls can be overridden more easily than automatic controls, because a technical change is usually more difficult than a procedural change. Changes are sometimes necessary to fix problems that arise, but whether it is good or bad for changes to be easily made is a policy judgment.
Manual and automatic methods can control usage in many ways, including the following:
• Constraining the selectors associated with targets to those that are approved in some way (e.g., analysts may target only those parties for which they have reasonable and articulable suspicion of involvement with terrorism);
• Limiting the time period for which data are accessible;
• Limiting the kinds of algorithms that are applied to data (e.g., algorithms that look for patterns, or various statistical techniques); and
• Using advanced information technology techniques to limit risk of disclosure, as described below.
The bulk of this chapter discusses how to control queries that analysts make against collected data. Controlling the use of such a large amount of data is critical, which is why the committee has emphasized it. When the data are queried, rules are applied about what uses of collected data are allowed. If a policy decision is made to continue bulk collection, protection of privacy and civil liberties will necessarily rely on these rules.
Once the results of a query are delivered to an analyst, other means must be used to control proper use of the data between queries and disseminated intelligence reports. These other means must be matched to what analysts actually do and to the tools they use. This cannot be done in the same way that queries on the collection database are controlled, for several reasons:
1. To do their jobs, analysts need flexibility to use the query results in many ways, such as combining them with other data or processing them with other programs, some perhaps written specifically for the current
______________
These involved very few incidents (around a dozen). A letter from NSA to Senator Charles Grassley on September 11, 2013, details these incidents (see https://www.nsa.gov/public_info/press_room/2013/grassley_letter.pdf). According to testimony to the committee on August 23, 2014, by NSA Director of Compliance, the activities were uncovered through internal investigations.
purpose. These uses are much less standardized than the collection database and the ways of querying it, and it is not practical to control them in detail. The reason is that in order to construct software that tracks in detail the way that the inputs of a program affect its outputs, it is first necessary to formalize how the program works. This is usually much more difficult than writing the program in the first place.
2. Analysts share their work in progress with other analysts, so that even if the queries made by a single analyst return only 50 items, the queries made by 200 analysts may return 10,000 items altogether, and a single analyst or systems administrator may end up with all of these items.
3. In some cases, analysts import query results into commercial applications such as a spreadsheet like Excel or a statistical analysis system like SAS/STAT. It is not practical to modify these applications to track the way that their inputs affect their outputs, and it is impractical for the IC to develop its own substitutes.
4. Analysts do their work and store their data on workstations and servers that run commercial off-the-shelf operating systems because it is neither economical nor efficient for the IC to build its own operating systems and the applications. Furthermore, there are many versions of these systems in use at any given time, as is normal for any large organization. It is not practical to use these systems for fine-grained control of data.
It would be naive for the committee to claim that it understands what happens today, and presumptuous to pretend to design an ideal system for NSA’s use. Furthermore, it is not enough to understand the normal information flow; possible changes, mistakes, and errors also need to be dealt with. For instance, something might change that would make yesterday’s legitimate query unacceptable today. A target might have become a non-target, or an error might have been found in the rules governing queries.
It is possible, however, to have very coarse-grained controls on the data held by analysts, controls that implement the existing U.S. government information classification system. Indeed, the IC has supported research on such controls since the 1970s, under the rubric of “multi-level security.” More recent academic work calls it “information flow control.” It is quite well understood in theory, and several systems have been built that enforce the rules for handling classified data. Unfortunately, attempts to use these systems in practice have been unsuccessful, and almost none are deployed. Information flow control cannot do the kind of query-specific control that is described in this chapter; instead, it tends to push computed outputs to the highest level of classification, which is not useful in practice. However, it is the best technique known at present.
To ensure compliance with the rules laid down by the legal authorities under which it operates, NSA has a system of internal auditing and oversight, combining automated and redundant human components. The system covers all parts of the foreign intelligence collection system: storage, querying, analysis, and dissemination.
Technology is used to some extent to implement the legal framework for foreign intelligence information, in the form of access controls, secure databases, and an automatically generated audit trail.
There is also extensive human review of all actions, both internal and external. NSA’s compliance program is supported by more than 300 personnel across the agency, which includes the Office of the Director of Compliance (established in 2009).4 Internal oversight is provided by the NSA’s Office of Inspector General and the Office of General Counsel. NSA also has a Civil Liberties and Privacy Office, first established in January 2014 shortly after the President’s speech on signals intelligence.5 The other major staff organizations that have responsibility for some facets of civil liberties and privacy responsibilities are the Office of the Director of Compliance, the Authorities Integration Group, and the Associate Director for Policy and Records. The Office of the Director of National Intelligence (ODNI) has its own Civil Liberties and Privacy Office,6 and the ODNI Office of General Counsel and the Department of Defense Office of General Council have responsibility for oversight as well.
Continuing external oversight is provided by the Department of Justice, congressional oversight committees, and the Foreign Intelligence Surveillance Act (FISA) court. The Privacy and Civil Liberties Oversight Board (PCLOB)7 and the Intelligence Oversight Board of the President’s Intelligence Advisory Board have also examined NSA operations from
______________
4 Office of the Director of National Intelligence, DNI Clapper Declassifies Intelligence Community Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act (FISA), 2014, http://www.dni.gov/index.php/newsroom/press-releases/191-press-releases-2013/927-draft-document.
5 National Security Agency Central Security Service, NSA Announces New Civil Liberties and Privacy Officer, January 29, 2014, https://www.nsa.gov/public_info/press_room/2014/civil_liberties_privacy_officer.shtml.
6 See Office of the Director of National Intelligence, Civil Liberties and Privacy Office, “Who We Are,” http://www.dni.gov/index.php/about/organization/civil-liberties-privacy-office-who-we-are, accessed January 16, 2015.
7 Privacy and Civil Liberties Oversight Board, Report on the Telephone Records Program Conducted under Section 215 of the USA PATRIOT Act and on the Operations of the Foreign Intelligence Surveillance Court, January 23, 2014, available at http://www.pclob.gov/library/215Report_on_the_Telephone_Records_Program.pdf; and Privacy and Civil Liberties Oversight Board, Report on the Surveillance Program Operated Pursuant to Section 702 of the Foreign Intelligence Surveillance Act, July 2, 2014, http://www.pclob.gov/library/702-Report.pdf.
a privacy and civil liberties standpoint. None has found any deliberate attempts to circumvent or defeat these procedures, although there have been documented incidents of error.
Purely automatic control of usage would mean that the rules would be enforced automatically using published mechanisms. Then people outside the IC concerned about privacy and civil liberties would not have to trust that the IC has adequate procedures and follows them, which many of them are reluctant to do. Such purity is not possible, however; it is thus necessary to independently audit the IC’s procedures to some extent. The impractical alternative is to make every step on the path from raw data to query results secure from any possible tampering; this would be a rigid and unworkable system. Some manual controls are necessary to ensure that the automatic controls are actually imposed and that they are configured according to the rules, and to decide cases that are too complex to be automated.
Thus, the goal of reassuring the public by the exclusive use of transparent automatic controls is elusive. Those who do not trust the power of government, both its elected officials and the IC, will argue that its technical expertise could be misused to override automatic controls, and no amount of manual or automatic oversight is likely to reassure them. In short, perfect controls are impossible. The goal should be to balance controls against practicality, recognizing that some amount of risk, tempered by trust in those who manage the system, will always remain.
A technical system for controlling usage of bulk data has three parts: isolating the bulk data so that it can only be accessed in specific ways, restricting the queries that can be made against it, and auditing the queries that have been done. All three parts are equally important, although isolation is most fully developed and hence has the fullest description, and auditing is the least developed. This chapter gives brief descriptions of each of these parts. It emphasizes the architecture of the possible systems, giving only a sketch of the technical details; consult the references for the full story.
Note that any technical mechanism must be tested under realistic conditions to establish confidence that it actually works. This is especially important for mechanisms that are intended to handle rare events, like the ones described here. The only practical way to do this is to deliberately inject disallowed queries into the running system and verify that they are detected and handled correctly.
Some of the methods described here are in widespread use commercially, and perhaps within NSA. Others have been demonstrated in the
laboratory at a moderate scale. Except for full homomorphic encryption, it should be possible to deploy any of them at scale within the IC in the next 5 years. However, the committee is not recommending deployment of any of them. Whether more powerful automatic controls should be deployed is a policy question. The answer depends both on the cost to the IC in dollars and in reduced capability, and on how important it is to have better controls. The committee notes that, in some cases, better technology could reduce the cost of existing controls.
Isolating bulk data is one technical method for controlling usage. Isolation also makes it easy to log all the queries against it and their results, which is essential for the auditing discussed in Section 5.4.3. Figure 5.2 shows the elements of this method, which is closely related to the standard access control method used in cybersecurity. The bulk data is cut off from the outside world by an isolation boundary. The only way to cross this boundary is to submit a query to the guard, which is responsible for enforcing the policy that says what queries and results are allowed. The guard logs all queries and results for later auditing, and the audit log itself is isolated to protect it from tampering. The isolated domain is hosted by some mechanism that guarantees the isolation; in some sense it runs on the host, and its security therefore depends on the host operating correctly. There are many such mechanisms: airgaps, operating systems, etc.; some of them are discussed below. In all cases, the host is implementing the isolation; if it does not work correctly, the bulk data will not be pro-
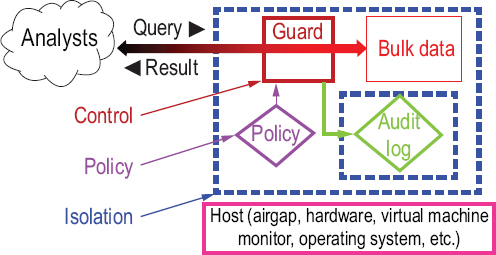
FIGURE 5.2 Isolating bulk data.
tected. For example, if an operating system is corrupted by malware, it will not properly isolate the application processes that it hosts.
Note that isolation depends on the guard as well as the host. If the guard lets through inputs that it should have blocked, the bulk data will not be properly protected. See Section 5.4.1.3.
The critical points in this architecture are the bulk data processing itself, the guard, and the host that implements the isolation boundary. These constitute the trusted computing base (TCB), the parts of the system that must work correctly for the system to be trustworthy. The smaller and simpler they are, the more likely they are to be correct, making it easier for manual review and automated tools to check for mistakes.
Bulk data processing is trusted to correctly implement a query, rather than return something else that might violate the policy. Again, if the TCB is simple, it is easier to understand and more likely to work. There are ways to implement the system so that the most complicated parts are kept outside the TCB; they are described below.
The guard is critical, no matter how the isolation is done; it is trusted to correctly enforce the policy and block malformed inputs. The latter is difficult if the inputs are too complicated for the guard to fully understand. Simple policies and simple inputs make it much more likely that the guard will work correctly. With simple inputs, the guard can concentrate on the job of making sure that all the queries it passes are allowed by the policy. With complicated inputs, it is much easier to hide some piece of malware that is not really a query at all. A familiar example of this is executable malware included in an email message. A policy that says to only accept email from friends is not enough, because friends might be infected themselves. The guard needs to block all executable content that has not been properly vetted.
Traditionally in computer security, the guard implements an access control policy that, as shown in Figure 5.2, would specify which analysts are allowed to access which items of bulk data, by attaching to each data item some description of the analysts authorized to access it. NSA has reported that its analysts use some variant of this scheme within a private cloud.8 Although it is a useful line of defense, this mechanism cannot express more complex policies such as, “Report all contacts that are one hop away from this target and were in Afghanistan during the communication.”
______________
8 Dirk A.D. Smith, “Exclusive: Inside the NSA’s private cloud,” Network World, September 29, 2014, http://www.networkworld.com/article/2687084/security0/exclusive-insidethe-nsa-s-private-cloud.html.
5.4.1.1 Federation of Nongovernment Parties
A partly technical approach to isolating bulk data is federation: when possible, leaving the data in the hands of multiple parties that are not part of the government; these might be the parties that acquire the data in the first place, such as telephone companies or other communication service providers, or they might be independent third parties. Querying the database then requires querying all the relevant parties and combining the results, as shown in Figure 5.3. In general, it cannot be done in parallel, and it might require repeated queries to the same party. For example, when tracing out a chain of communication in which different links come from different providers, each link may require a separate query. Furthermore, some kinds of preprocessing of the data may be much less effective, for example, working out all the tightly knit cliques of people who communicate with each other a lot, so that it is possible to quickly find all the cliques that an individual belongs to.
Federation has clear advantages for safeguarding privacy and enforcing policies:
• The federated parties are separate from the intelligence agency and may have no incentive to break the rules, which would help reassure those who are concerned that NSA may have incentives to break the rules.9
• One party’s misbehavior exposes only some of the collected data.
Federation also has clear drawbacks for intelligence:
• The federated parties may have no incentive to cooperate, even if paid; indeed, their customers may object to such cooperation.
• If a federated party is compelled to collect data it otherwise would not, it may introduce privacy risks.
• If forced to cooperate, a federated party may be slow and clumsy, because it is being asked to do things that are not part of its normal business. This may make it difficult to get good results. Note that federation is much more difficult to implement than the cloning of call detail records that is the current practice under FISA Section 215.
• Federated queries may be much slower and less reliable than centralized ones, both because communicating across organizational boundaries is slow and because database-wide optimizations may be impossible, as described above.
______________
9 This is the process used in wiretap investigations authorized by the 1986 Pen Register Act (Title III of the Electronic Communications Privacy Act).
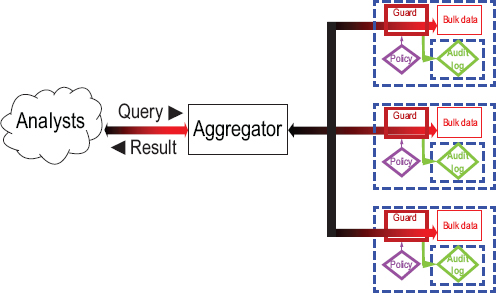
FIGURE 5.3 Federation of non-government parties.
In addition, federation makes the collected data both more and less secure. It is more secure because breaking into one party exposes only some of the data. It is less secure because some of the federated data is exposed if the adversary breaks into any one of the parties.
5.4.1.2 Hosts and Isolation Boundaries
The choice of hosts depends on two things: the acceptable cost of isolation (both capital cost and reduced performance) and the threats it must defend against. More severe threats incur a higher cost, of course, but depend less on manual controls. There are many possible implementations of isolation boundaries with different security strengths and weaknesses and different costs. Here are a few examples:
• Airgap. The most secure and most expensive isolation boundary is an airgap: separate physical machines, or networks of physical machines, inside and outside the isolation boundary that is breached only by a carefully controlled network connection. The airgap is costly, because there are two networks of machines to buy and maintain, and the connection between them may be slow. The IC has traditionally used airgaps to isolate classified from unclassified systems; perhaps they are also using airgaps to isolate collected data from analysts. Note that although an air-
gap is a very good isolation boundary, the isolation also depends on the guard that is supposed to check all inputs, as discussed below.10
• Hypervisor. A cheaper host is a hypervisor that implements separate virtual machines instead of separate physical ones. Currently, the hypervisor is part of the TCB, and, unfortunately, commercial hypervisors are rather complicated because their main selling point is performance rather than security. But this is cheaper than the airgap because there is only one physical machine, and the bandwidth of communication between the virtual machines can be close to the full memory bandwidth. There are many variations on the hypervisor idea, with different costs and security considerations.11
• Enclaves. In between separate physical machines and separate virtual machines is a fairly new way of doing isolation, called an enclave in the implementation, developed by Intel. This is like a virtual machine, but its isolation is provided directly by the central processing unit (CPU). Because this mechanism is tightly integrated into the CPU and the memory system, it can provide good performance much more simply than a hypervisor.12
Language virtual machines. Programs written in languages intended for web pages, such as Java and JavaScript, are usually executed inside isolation boundaries with names like Java Virtual Machine. In this case, the main purpose of the isolation is to protect the rest of the system from the untrusted web program rather than the other way around.
5.4.1.3 The Guard
If the isolation mechanism is sound, the guard is the main weak point; if the guard makes the wrong decisions about what to allow through, the system inside the isolation boundary can be completely compromised, and this has happened many times in practice with every kind of isolation boundary, including airgaps. For example, executable malware included in an email message can infect an isolated system. The same thing can happen with a USB flash drive, which can contain malware that is executed automatically. The guard needs to block all executable content that has not been properly vetted. As with every aspect of security, the
______________
10 Although a good example of an isolation technique, technology alternatives listed in this subsection can be engineered to provide adequate isolation for this application.
11 M. Pearce, S. Zeadally, and R. Hunt, Virtualization: Issues, security threats, and solutions, ACM Computing Surveys 45(2), Article No. 17, 2013.
12 F. McKeen, I. Alexandrovich, A. Berenzon, C. Rozas, H. Shafi, V. Shanbhogue, and U. Savagaonkar, Innovative instructions and software model for isolated execution, in Proceedings of the Second International Workshop on Hardware and Architectural Support for Security and Privacy, Association of Computing Machinery, New York, N.Y., 2013.
only practical approach today is to keep both the specification of what the guard has to do and the code that does it as simple as possible.
If each item of bulk data is tagged with access control information that specifies which analysts are allowed to see it, the job of the guard is easier. The Apache Accumulo open-source database, for example, has this feature; it was originally developed by NSA, which transferred it to Apache, an organization that develops open-source software for the Internet. This kind of tagging is the standard way of doing access control in computer security; it is helpful for controlling usage of collected data, but not sufficient for enforcing a rule such as “trace contacts for at most two hops,” which restricts the algorithm that processes the data rather than access to the data itself.
5.4.1.4 Bulk Data Processing
In general, there are a lot of bulk data, so that simply storing the bits securely and reliably is complex, and the data are processed by a general-purpose database system that is even more complex, usually tens of millions of lines of code. Much of this code might not be needed for a particular application, but it is likely to be impractical to separate the parts that are needed from the rest. Thus, it is highly desirable to keep as much of this storage and processing out of the TCB, which should be small and simple.
There has been a lot of work on isolation to protect a cloud client from its cloud service provider, because there is a big market for cloud computing, and many customers care about the security of their data and do not want to trust the service provider. This is the most important application for the enclaves described above. Figure 5.4 shows another way for a client to store and process data in the cloud without trusting the cloud provider. The idea is to do everything in the cloud in encrypted form, so that the result appears in encrypted form as well. Only the client holds the key, so only the client can see anything about the data or the result except its size, and perhaps something about the shape of the query. This gives no guarantee that the result is correct or that it reads only the data actually needed for the query, but it does guarantee that only the client sees any data, and since the client is entitled to see all the data, the client’s secrecy is maintained. It is not obvious how to actually implement this scheme, but in some cases it is possible, and ways to do it are explained below.
Unfortunately, although the architecture shown in Figure 5.4 serves the needs of the cloud client, it is not enough for automatic control of access to bulk data. Unlike the cloud client, the analyst is not entitled to see all of the data. How can the guard enforce the policy about what the analyst is allowed to see? This takes a proof, or perhaps some convincing
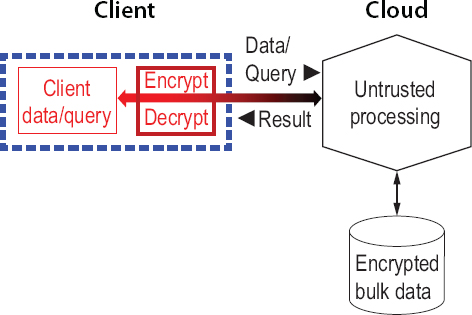
FIGURE 5.4 Smaller trusted computing base by processing encrypted data for a client.
evidence, provided by the untrusted cloud side of the picture, that the result is correct or at least that it does not reveal any more data than the query demands. Figure 5.5 illustrates this approach; the parts that are unchanged from Figure 5.2 are dimmed.
What would such a proof look like? That depends on the query. For example, if the query is “Return all the endpoints of communications with this target,” a proof would be a list of all the database entries that yielded the result; recall that these are all encrypted, so the untrusted side cannot make them up. If the target is X, and each database entry represents a call detail record with a triple <from, to, time>, verifying the proof means checking that every result endpoint Y is in an entry <X, Y, time> or <Y, X, time>. Note that this does not prove that the result is correct, but it does prove that no extra information is disclosed. For another example, see the next section.
5.4.1.5 Encrypted Data at Rest
The simplest example of the idea in Figure 5.5 uses the untrusted side only to store data, not to do any computing on it, as shown in Figure 5.6 (where the unchanging left side of the figure has been cut off). This means that each data block is encrypted before being handed over to untrusted storage by the collection system and decrypted when it is read back. Each
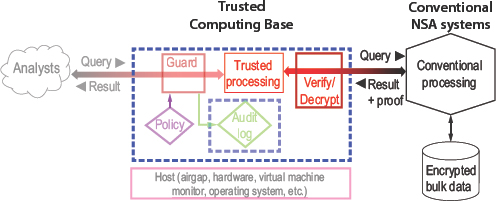
FIGURE 5.5 Smaller trusted computing base by verifying untrusted processing of a query.
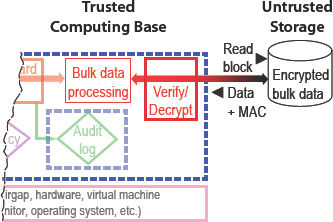
FIGURE 5.6 Smaller trusted computing base by encrypting bulk data at rest.
data block also has a message authentication code (MAC), a well-known cryptographic mechanism that the trusted verifier can use to check that the encrypted data it reads back is indeed the same data that it wrote earlier. The MAC serves as the proof that the untrusted storage is returning the correct result of the read. This scheme has been widely implemented, and it removes the storage hardware from the TCB. It also removes a lot of software, because reliably and efficiently storing large amounts of data is complex, and it takes millions of lines of code to deal with this complexity.13
______________
13 Ken Beer and Ryan Holland, “Securing Data at Rest with Encryption,” Amazon Web Services white paper, November 2013, http://media.amazonwebservices.com/AWS_Securing_Data_at_Rest_with_Encryption.pdf.
5.4.1.6 Simulating Homomorphic Cryptography
A fancy form of cryptography called homomorphic encryption makes it possible to do all the processing on encrypted data, producing an encrypted result without exposing any data in the clear.14 It is quite surprising that this works at all, but it turns out there are theorems showing that any computation can be done in this way. Doing the untrusted processing with homomorphic encryption provides a complete implementation of Figure 5.4. Unfortunately, the best known ways of doing it, in general, are at least a million times too slow to be practical.
For queries that only need to test whether two values are equal, simple deterministic encryption is sufficient. Perfect encryption would reveal nothing at all about the data values except their approximate size. Deterministic encryption reveals only which values are equal. For queries that need to test whether one value is less than another, order preserving encryption is sufficient. It is more expensive and of course reveals the relative order of the values. Many practical queries fall into one of these categories, and it is not too hard to modify an existing database system to make these queries work entirely on encrypted data.15 Work using an encrypted search may yield useful results in the future; see Section 6.3.1.
The idea behind homomorphic encryption is that any basic computation on encrypted data, such as adding two numbers, comparing two strings for equality, or sorting a list of items, can be done (slowly) directly on the encrypted data. A practical alternative is to add a small component to the TCB that decrypts the data, does the operation, and encrypts the result, as shown in Figure 5.7; compare this with Figure 5.5. Because most of the basic operations are simple, this component can be small and simple. Indeed, for many applications, it can be simple enough to be implemented in special purpose hardware using field programmable gate arrays, which is both fast and difficult to infect with malware.16
______________
14 Craig Gentry, Computing arbitrary functions of encrypted data, Communications of the ACM 53(3):97-105, 2010.
15 R.A. Popa, C.M.S. Redfield, N. Zeldovich, and H. Balakrishnan, CryptDB: Protecting confidentiality with encrypted query processing, in Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, Association of Computing Machinery, New York, N.Y., 2011.
16 A.A. Arasu, S. Blanas, K. Eguro, M. Joglekar, R. Kaushik, D. Kossmann, R. Ramamurthy, P. Upadhyaya, and R. Venkatesan, Secure database-as-a-service with Cipherbase, in Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, Association of Computing Machinery, New York, N.Y., 2013.
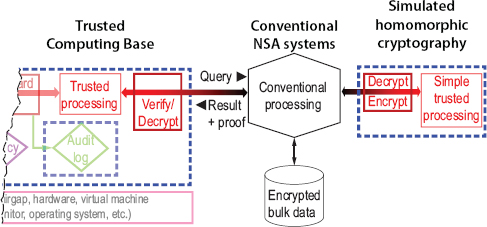
FIGURE 5.7 Smaller trusted computing base by simulating homomorphic cryptography.
5.4.2 Restricting Queries Automatically
Restricting queries automatically is another way to control usage. The goal is to do this well enough that software can decide which queries are allowed by the policy, or at least drastically reduce the number of queries that require human approval. The conventional access control discussed above is one way to do this, but there are many policies that it cannot express. Automated restriction is certainly feasible for limited classes of queries such as, “Find all the phone numbers that have connected in the last month to this list of numbers belonging to a known target.” Indeed, NSA already has pre-approved queries, but their scope can probably be extended significantly. The more mechanized the process, the better. Sometimes the software will refer to a human for a decision, but an automated decision is cheaper, faster, potentially more transparent, and less burdensome to analysts. The ideal is that the analyst only sees information about targets, so that there is no intrusion on the privacy of people who are not targets.
Chapter 6 discusses some of the major opportunities for advances here.
5.4.3 Audit/Oversight Automation
Auditing usage of bulk data is essential to enforce privacy protections. The first step is to ensure that every query is permanently recorded in a log. Isolation provides confidence that every query is permanently logged. Then the log must be reviewed for compliance with the rules.
Doing this manually is feasible, and is, indeed, NSA’s current practice. Although it is thorough, it is expensive and not transparent—outsiders must rely on the agency’s assurance that it is being done properly, because the queries are usually highly classified. Automation of auditing, a direction NSA is pursuing, could both streamline audits and provide assurance to outside inspectors, who can then examine the auditing technology.
The resulting ability to inspect the privacy-protecting mechanisms of the SIGINT process on an unclassified basis may help allay privacy and civil liberty concerns. The inspection would focus on the automation software and the usage rules it enforces, rather than on the data, which must remain classified.
Greater automation of auditing is an area that has been greatly neglected by government, industry, and academia; for example, operating systems write voluminous logs of security-relevant events, but they are seldom looked at, and when they are, a great deal of manual effort is required. Chapter 6 discusses some possible improvements.
This chapter has reviewed a variety of feasible mechanisms, both manual and automatic, for controlling the way that collected data is used. Some of these are deployed in the IC. Others may be deployed, but the committee was not told about them in briefings. All of these mechanisms are feasible to deploy within the next 5 years. Opportunities to introduce enhancements to such capabilities are expected to arise as the information technology systems used for collection and analysis are refreshed and modernized.
Automation of usage controls may simultaneously allow a more nuanced set of usage rules, facilitate compliance auditing, and reduce the burden of controls on analysts. Similarly, there are opportunities to automate the various audit mechanisms to verify that rules are followed. These techniques may permit more of the use controls and audit mechanisms to be explained clearly to the public. It may be possible to express a large fraction of the rules required by law and policy in a machine-processable form that can be rapidly and consistently applied during collection, analysis, and dissemination.
Conclusion 2. Automatic controls on the usage of data collected in bulk can help to enforce privacy protections.
Conclusion 2.1. It will be easier to automate controls if the rules governing collection and use are technology-neutral (i.e., not tied to specific, rapidly changing information and communications tech-
nologies or historical artifacts of particular technologies) and if they are based on a consistent set of definitions.
Conclusion 2.2. Automated controls can provide new opportunities to make the controls more transparent by giving the public and oversight bodies the opportunity to inspect the software artifacts that describe and implement the controls. Increased transparency can give people outside the IC more confidence that the controls are appropriate, although the need for secrecy about some of the details makes complete confidence unlikely.
Whether any given method should actually be deployed is a policy question that requires determining whether increased effectiveness and apparent transparency is worth the cost in equipment, labor, and potential interference with the intelligence mission. In any case, some automatic methods might be able to replace existing manual ones at a lower cost.



















