
Appendix C
Introduction to Causal Inference Principles
Recent decades have seen a surge in the development of methods to answer questions regarding causality—such as whether exposure to particulate matter increases mortality—from data arising from randomized and non-randomized (observational) studies. Those methods introduced formal tools that increase rigor in design, analyses, and interpretation of studies that establish causality and clarify the conditions under which a causal determination can be made. This appendix reviews some of the main ideas introduced by those methods, focusing on how the general principles can be used to assess the relative importance of a single study on the body of evidence used in a weight of evidence approach for establishing causality. The goal is to delineate these principles in sufficient generality so that they might be incorporated into a causal framework to assess the strength of evidence for causality. Important points will be illustrated using specific study designs that are common across Integrated Science Assessments (ISAs).
The fundamental ideas in statistical literature goes back to Neyman (1923) and Cochran (1965), and formalized in seminal work by Rubin (1974), Rosenbaum and Rubin (1983), Robins (1986), Pearl (2009), among many others. To organize the discussion, this appendix focuses on a roadmap for causal inference as described in (Petersen and van der Laan, 2014). There are variations of the roadmap (e.g., Ahern, 2018), and the principles presented below appear in various forms in causal inference literature. The principles are widely recognized as important tenets for the appropriate design, analysis, and interpretation of causality studies. When designing a study aimed at assessing causality (Goodman et al., 2017; Pearl, 2009; Petersen and van der Laan, 2014) recommends the following:
- Articulate the scientific question in terms of potential/counterfactual outcomes.
- Specify the available data (e.g., measurements of exposures, outcomes, confounders, etc.) and a causal model.
- Articulate a set of assumptions on the causal model that allow identification of the causal parameter of interest (also called a “causal estimand”) as an observable statistical quantity.
- Analyze the data: estimate the identified statistical quantity.
- If all assumptions are internally consistent, interpret the statistical results as causal relations according to the validity of assumptions made in Steps 3 and 4, and quantify the statistical uncertainties.
While these steps were formulated for the design and analysis of individual studies, they may also be helpful for assessing the quality and strength of causal inference of individual studies considered by the U.S. Environmental Protection Agency (EPA) in the ISAs. These include, for example, epidemiological studies, controlled human exposure studies, animal toxicology studies, and various studies on pollutant exposure or deposition effects on environmental endpoints or other welfare effects like visibility and climate. These principles also apply to both randomized and non-randomized (observational) studies, although some of the issues discussed below (e.g., confounding) are less relevant when assessing the quality of randomized studies.
Some historical and cultural clarification about observational studies and causality is helpful before discussion of each of these principles in more detail. Scientists historically have been reticent to describe results from non-randomized studies as causal (e.g., Hernán, 2018, and associated commentary; Pearl, 2009). While the advent of novel tools and methods for causal inference has increased the adoption of these principles in research practice, the explicit use of a rigorous causal framework and causal language is not yet the norm (Haber et al., 2021; Hernán, 2018). However, even though the development of the causal inference framework discussed here is relatively recent, its core principles have been present implicitly long before their explicit statement. A study that does not explicitly discuss the above principles can nevertheless provide important evidence about causal relations. Conversely, discussion of the principles or using causal language when describing the conclusions does not guarantee that the relations found in a given study are causal. A crucial point with respect to Step 5 is that a study’s results should not be viewed as valid just because “causal language” was used or methods for causal inference were used, but rather it needs to be considered in terms of whether the causal assumptions underlying that design are plausible in that study.
ARTICULATION OF THE SCIENTIFIC QUESTION
Causal inference questions are formalized in terms of counterfactual queries expressing what would have occurred under different treatment conditions, including hypothetical interventions of the agents (e.g., individuals’ exposure to pollutants) being evaluated. Specifying these interventions is a fundamental step in defining a causal inference problem. For air pollution specifically, there are at least two types of questions that studies may tackle:
- Studies that estimate whether a hypothetical difference in air pollution, A and A+delta lead to differences in health or welfare outcomes. These are referred to as epidemiological studies of air pollution. Welfare-related gradient studies are conceptually similar (Braun et al., 2017). Study designs typically used in this setting include longitudinal/panel cohort studies, case-control studies, case-crossover studies, and instrumental variable designs, although many other designs can also be used. While epidemiological approaches were primarily developed and refined for assessing human health effects, similar design approaches are also relevant and applicable to assessing welfare effects of pollutant exposures (Braun et al., 2017).
- Studies that estimate whether observed changes in pollutant exposure led to changes in health or welfare outcomes. These are generally described as natural experimental studies or quasi-experimental studies (de Vocht et al., 2021), and noted by Bradford Hill as potentially providing some of the strongest support for causation. Studies of effects of air
quality changes resulting from regulatory policies (e.g., banning traffic during the Olympic games), referred to as accountability studies, are an important subset of natural experimental studies, and especially relevant to assessing causality in the context of National Ambient Air Quality Standards (NAAQS) reviews considering future regulatory policies (Henneman et al., 2017). Study designs used in this setting include difference-in-difference designs, instrumental variable designs, time-series studies, etc., although many other designs can also be used.
These study categories are not necessarily mutually exclusive; the data used may overlap. Four types of study designs are presented in Boxes C.1 through C.4 to illustrate the principles outlined in this section. The four types of study are: randomized studies, time-series studies, cohort studies, and quasi-experimental studies. Quasi-experimental studies are also referred to as natural experiments (de Vocht et al., 2021) While this is not an exhaustive list of all of the study designs that can inform causal determinations, they are useful to illustrate some principles discussed in this section. How those principles may be used by EPA to guide individual study quality assessment and to assess the strength of evidence for causality that can be gleaned from a single study in a weight of evidence approach are discussed. Boxes C.1 through C.4 are examples referenced throughout this appendix.
The fundamental problem of causal inference is that none of the counterfactual outcomes in the above examples can be observed for all study participants—not even in principle. Nonetheless, causal determinations are useful for decision making and an attempt to infer causal effects may be sought. Solving this riddle requires the postulation of a causal model and causal assumptions that allow the use of observed data (factuals) to infer causal effects. The definition of the counterfactuals is crucial to define and determine other principles of study quality (e.g., no unmeasured confounders) and is what distinguishes evidence of an association from evidence of causality.
SPECIFICATION OF AVAILABLE DATA, A CAUSAL MODEL, AND THE APPROACH FOR ASSESSING CAUSAL INFERENCE FROM THE DATA
To illustrate the need for a causal model, it is important to understand a useful distinction between a statistical parameter and a causal parameter. As described in Box 3.1, a statistical parameter refers to a quantity defined in terms of the statistical model and observed data distribution (e.g., a coefficient in a regression model), and a causal effect (or causal parameter) is a quantity defined in terms of the causal model (e.g., the mean outcome for a set of units if those units had the exposure of interest compared to the mean outcome for them if they were unexposed). Inferring a causal effect requires the assumptions in the causal model to be correct. Therefore, causal effects cannot be learned from only a statistical model and data.
The process of representing causal queries in terms of statistical parameters is referred to as “identification” in the causal inference literature. Identification of causal effects requires the postulation of a causal model encoding a priori knowledge about the data generating mechanisms. This knowledge often comes in two different forms: known or assumed temporal ordering of the measured variables and known or assumed causal relations between pairs of variables. Such a priori knowledge may thus incorporate non-testable assumptions that have no observable implications for associations in the available data, and thus their validity cannot be tested from such data.
To understand the importance of temporal ordering, consider a study that aims to assess whether A has a causal effect on B. A cause must precede its effect, yet in many studies there is no information about whether variable A precede variable B. Without external knowledge (e.g., from other studies) about the temporal ordering between variables, it is difficult to know whether A causes B, B causes A, or neither, even in the presence of an association between A and B.
To illustrate the need for a priori knowledge of cause-effect relations in the data, consider Example 1 described in Box C.1 (a randomized study) and consider a dataset in which only exposure assignment and animal health outcomes are given. It would be impossible to distinguish from this dataset alone whether exposure assignment was randomized, or whether exposure was given preferentially to healthier rats for example. Randomization of exposure assignment implies that no observed or unobserved variable is a cause of exposure assignment, and randomization information is only externally available through the study design. Randomization is fundamental to avoid potential unmeasured confounding that would otherwise vitiate any causal determination made from data alone.
Temporal ordering and other a priori knowledge can be encoded and communicated in the form of causal models. As an example of a tool that is often used in the construction of a causal model, consider the directed acyclic graph (DAG) for the longitudinal cohort study described in Box C.3, with two time points depicted in Figure C.1. In this graph, an additional set of factors have been added, characterized by variables Lt which we assume are measured at each time point. This graph encodes the following assumptions about the data generating mechanism: (1) the temporal relation among At, Lt, and Y; and (2) an assumed causal structure for At, Lt, and Y dictated by directed arrows that represent the possible presence of a causal relation.
ARTICULATION OF CAUSAL MODEL ASSUMPTIONS AND IDENTIFICATION OF THE CAUSAL PARAMETER OF INTEREST AS AN OBSERVABLE STATISTICAL QUANTITY
Given a causal model and a causal estimand, the next task to consider is to decide whether the causal estimand can be identified from the observed data, given a set of assumptions on the causal model. It is in this step where the concept of confounders plays a crucial role. Consider the example in Box C.1 where the exposure of interest is randomized. By virtue of the study design, exposure
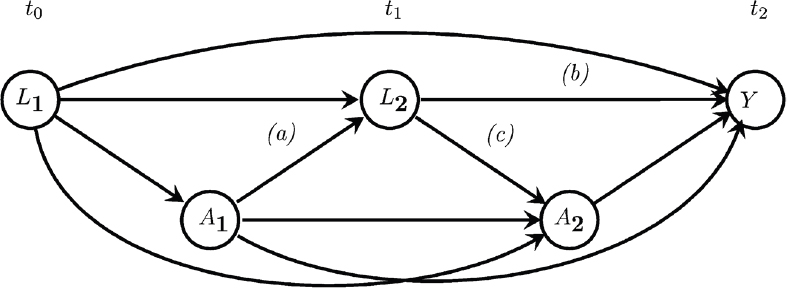
SOURCE: Moodie and Stephens, 2010.
assignment A is independent of the counterfactual variables Y(1) and Y(0), and so it is relatively straightforward to prove mathematically through a simple analysis that compares aggregate measures (e.g., averages) of the outcomes Y for those exposed (A=1) with the outcomes Y for those unexposed (A=0) delivers a causal effect (i.e., there is no confounding [Pearl, 2009]).
Identification of causal effects in non-randomized studies is more subtle and requires more careful consideration of confounding. Consider the example in Box C.3 (a longitudinal/panel/cohort study), where study participants are measured longitudinally at several points in time. Identifying the causal effects of a change in exposure requires that the time-varying variables Lt capture all common causes of the exposure variable At and the outcome Y. This means, for example, that a study that fails to adjust for known common causes of exposure and outcome is unlikely to deliver statistical results that can safely be interpreted as causal effects. Furthermore, recent developments in the causal inference literature have unveiled the important fact that coefficients extracted from longitudinal regression analyses cannot identify causal effects in causal models such as those depicted in Figure C.1 (Hernán and Robins, 2020). Specifically, under the assumption that Lt captures all common causes of the exposure variable At and the outcome Y, the distribution of the counterfactual variables may be identified from data in terms of the so-called longitudinal g-computation formula (Bang and Robins, 2005). Importantly, it is not feasible to use a simple single regression analysis to estimate causal effects in this context; a strategy like g-computation is needed to estimate causal effects in these complex longitudinal settings (Moodie and Stephens, 2010).
Other epidemiologic study designs for causal inference require similar assumptions. Consider the example in Box C.4, which is a quasi-experimental design. Identification of the effect in such a study often proceeds using a difference-in-differences (DiD) approach, which requires that the temporal trends of the unobserved counterfactual variables are identical between the control and exposure groups (Abadie, 2005). This assumption permits estimation of causal effects by “borrowing” information from the controls to extrapolate what would have happened to the exposed group under no exposure. Violations of this assumption will lead to incorrect causal effect estimates. All other study designs and identification strategies have analogous identification assumptions, and the strength of the causal inference that a given study can provide should be evaluated with respect to the degree of confidence that these identification assumptions hold.
DATA ANALYSIS
Once the causal effect has been identified in terms of quantities that can be learned from data (e.g., the longitudinal g-computation formula in the example in Box C.3 or the DiD formula in the
example in Box C.4), individual studies often proceed to data analysis and estimation of the identified quantity. In this step, there are several techniques that can be employed, such as those based on outcome regression models, propensity score based or other types of matching or weighting, and doubly robust estimators (Stuart, 2010). Estimation techniques have been developed for each design and causal estimand. For example, several estimators are available based on regression and weighting for the longitudinal g-computation formula (e.g., Bang and Robins, 2005; Díaz et al., 2021; Robins et al., 2000; van der Laan and Gruber, 2012) for the difference-in-differences study design (e.g., Abadie, 2005; Heckman et al., 1997; Sant’Anna and Zhao, 2020) for instrumental variables (e.g., Angrist and Imbens, 1994; Angrist et al., 1996; Hernán and Robins, 2006; Ogburn et al., 2015), and other factors. Evaluating the quality of the data analysis and statistical modeling in an individual study entails ensuring that (1) the analysis chosen corresponds to the identified causal quantity (e.g., longitudinal regression models do not estimate causal effects [Hernán and Robins, 2020]), (2) the testable assumptions required (such as the overlap or positivity assumption [Petersen et al., 2012]) are satisfied, and (3) the analysis makes acceptable efforts to reduce the risk of model misspecification bias. This evaluation is done within the context of assessing the underlying causal assumptions as described above. Emerging tools that can be used to assess the quality of an individual study regarding each of these points are discussed in Chapter 8.
INTERPRETATION OF STATISTICAL QUANTITIES AS CAUSAL EFFECTS IN INDIVIDUAL STUDIES
The principles discussed in this appendix allow the evaluation of individual studies on quality and strength of evidence of causal relations. The strength of causal inference for an individual study depends on the quality of the study design, the validity of the implicit or explicit causal model, the quality of the data analysis, and the correctness of the assumptions required for identification. While the quality of the data analysis and statistical relationships can often be tested or assessed empirically, the validity of causal models is often a source of significant debate and cannot generally be completely corroborated given that the validity depends on unobserved counterfactual outcomes. Nonetheless, the evaluation of causal assumptions (e.g., the assumption of complete confounder adjustment in the context of study designs that rely on that) needs to be an integral part of the assessment of study quality. While confirming that the assumptions hold is not generally possible, explicit articulation of the assumptions can help identify situations in which causal conclusions are not warranted or are only weakly supported. For example, in a comparison group design, failure to consider and adjust for potentially important confounders should reduce confidence that statistical effects estimated from data are indeed causal.
As for any tool, the utility of a causal inference framework in an individual study depends on its appropriate use. Merely using a causal model and attempting to estimate causal effects does not ensure that the questions asked are relevant. Likewise, the ability to posit causal models does not make the assumptions contained in those models true. The ability to show mathematical equivalence between statistical and causal parameters does not make the assumptions required for such equivalence true. The best estimation techniques can still produce unreliable answers if the data are inadequate (Petersen and van der Laan, 2014). The converse of this is also true: the absence of an explicit discussion of the study design principles outlined in this section does not constitute a failure of an individual study to provide evidence of causal effects in the context of a multidisciplinary weight of evidence framework.
REFERENCES
Abadie, A. 2005. Semiparametric difference-in-differences estimators. The Review of Economic Studies 72(1):1-19.
Ahern, J. 2018. Start with the “c-word,” follow the roadmap for causal inference. American Journal of Public Health 108(5):621.
Angrist, J., and G. Imbens. 1994. Identification and estimation of local average treatment effects. Econometrica 62:467-475.
Angrist, J. D., G. W. Imbens, and D. B. Rubin. 1996. Identification of causal effects using instrumental variables. Journal of the American Statistical Association 91(434):444-455.
Bang, H., and J. M. Robins. 2005. Doubly robust estimation in missing data and causal inference models. Biometrics 61(4):962-973.
Braun, S., B. Achermann, A. De Marco, H. Pleijel, P. E. Karlsson, B. Rihm, C. Schindler, and E. Paoletti. 2017. Epidemiological analysis of ozone and nitrogen impacts on vegetation—Critical evaluation and recommendations. Science of the Total Environment 603-604:785-792.
Cakmak, S., C. Hebbern, L. Pinault, E. Lavigne, J. Vanos, D. L. Crouse, and M. Tjepkema. 2018. Associations between long-term PM2.5 and ozone exposure and mortality in the Canadian Census Health and Environment Cohort (CANCHEC), by spatial synoptic classification zone. Environment International 111:200-211.
Cochran, W. G. 1965. The planning of observational studies of human populations. Journal of the Royal Statistical Society: Series A (General) 128(2):234.
Currie, J., and R. Walker. 2011. Traffic congestion and infant health: Evidence from E-ZPass. American Economic Journal: Applied Economics 3(1):65-90.
de Vocht, F., S. V. Katikireddi, C. McQuire, K. Tilling, M. Hickman, and P. Craig. 2021. Conceptualising natural and quasi experiments in public health. BMC Medical Research Methodolology 21(1):32.
Díaz, I., N. Williams, K. L. Hoffman, and E. J. Schenck. 2021. Nonparametric causal effects based on longitudinal modified treatment policies. Journal of the American Statistical Association 1-16.
Goodman, S. N., S. Schneeweiss, and M. Baiocchi. 2017. Using design thinking to differentiate useful from misleading evidence in observational research. JAMA 317(7):705-707.
Haber, N. A., S. E. Wieten, J. M. Rohrer, O. A. Arah, P. W. G. Tennant, E. A. Stuart, E. J. Murray, S. Pilleron, S. T. Lam, E. Riederer, S. J. Howcutt, A. E. Simmons, C. Leyrat, P. Schoenegger, A. Booman, M. K. Dufour, A. L. O’Donoghue, R. Baglini, S. Do, M. R. Takashima, T. R. Evans, D. Rodriguez-Molina, T. M. Alsalti, D. J. Dunleavy, G. Meyerowitz-Katz, A. Antonietti, J. A. Calvache, M. J. Kelson, M. G. Salvia, C. O. Parra, S. Khalatbari-Soltani, T. McLinden, A. Chatton, J. Seiler, A. Steriu, T. S. Alshihayb, S. E. Twardowski, J. Dabravolskaj, E. Au, R. A. Hoopsick, S. Suresh, N. Judd, S. Pena, C. Axfors, P. Khan, A. E. Rivera Aguirre, N. U. Odo, I. Schmid, and M. P. Fox. 2022. Causal and associational language in observational health research: A systematic evaluation. American Journal of Epidemiology.
Heckman, J. J., H. Ichimura, and P. E. Todd. 1997. Matching as an econometric evaluation estimator: Evidence from evaluating a job training programme. The Review of Economic Studies 64(4):605-654.
Henneman, L. R. F., C. Liu, J. A. Mulholland, and A. G. Russell. 2017. Evaluating the effectiveness of air quality regulations: A review of accountability studies and frameworks. Journal of the Air and Waste Management Association 67(2):144-172.
Hernán, M. A. 2018. The C-word: scientific euphemisms do not improve causal inference from observational data. American Journal of Public Health 108(5):616-619.
Hernán, M. A., and J. M. Robins. 2006. Instruments for causal inference: An epidemiologist’s dream? Epidemiology 17(4):360-372.
Hernán, M., and J. M. Robins. 2020. Causal Inference: What If. Boca Raton, FL: Chapman and Hall/CRC.
Miller, D. B., S. J. Snow, A. Henriquez, M. C. Schladweiler, A. D. Ledbetter, J. E. Richards, D. L. Andrews, and U. P. Kodavanti. 2016. Systemic metabolic derangement, pulmonary effects, and insulin insufficiency following subchronic ozone exposure in rats. Toxicology and Applied Pharmacology 306:47-57.
Moodie, E. E. M., and D. A. Stephens. 2010. Using directed acyclic graphs to detect limitations of traditional regression in longitudinal studies. International Journal of Public Health 55(6):701-703.
Neyman, J. 1923. Sur les applications de la theorie des probabilites aux experiences agricoles: Essai des principes. (D. M. Dabrowska, and T. P. Speed, Translators). Excerpts reprinted in English, Statistical Science 5:463-472.
Ogburn, E. L., A. Rotnitzky, and J. M. Robins. 2015. Doubly robust estimation of the local average treatment effect curve. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 77(2):373-396.
Pearl, J. 2009. Causality: Models, Reasoning, and Inference. 2nd ed. Cambridge: Cambridge University Press.
Petersen, M. L., and M. J. van der Laan. 2014. Causal models and learning from data: Integrating causal modeling and statistical estimation. Epidemiology 25(3):418-426.
Petersen, M. L., K. E. Porter, S. Gruber, Y. Wang, and M. J. van der Laan. 2012. Diagnosing and responding to violations in the positivity assumption. Statistical Methods in Medical Research 21(1):31-54.
Robins, J. 1986. A new approach to causal inference in mortality studies with a sustained exposure period—Application to control of the healthy worker survivor effect. Mathematical Modelling 7(9):1393-1512.
Robins, J. M., M. Á. Hernán, and B. Brumback. 2000. Marginal structural models and causal inference in epidemiology. Epidemiology 11(5):550-560.
Rosenbaum, P. R., and D. B. Rubin. 1983. The central role of the propensity score in observational studies for causal effects. Biometrika 70(1):41-55.
Rubin, D. B. 1974. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology 66(5):688-701.
Sant’Anna, P. H. C., and J. Zhao. 2020. Doubly robust difference-in-differences estimators. Journal of Econometrics 219(1):101-122.
Stuart, E. A. 2010. Matching methods for causal inference: A review and a look forward. Statistical Science 25(1):1-21
van der Laan, M. J., and S. Gruber. 2012. Targeted minimum loss based estimation of causal effects of multiple time point interventions. The International Journal of Biostatistics 8(1).
This page intentionally left blank.










