
2
Disruptions to the Computing Technology Ecosystem for Stockpile Stewardship
Via the Advanced Simulation and Computing (ASC) program, the National Nuclear Security Administration (NNSA) spearheaded the global development of terascale and then petascale computing, and its collaboration with the Department of Energy’s (DOE’s) Office of Science in the Exascale Computing Project (ECP) has led to the first U.S. exascale computers. Concurrently, fabrication of leading-edge semiconductors has shifted to offshore foundries such as the Taiwan Semiconductor Manufacturing Company (TSMC), with both supply-chain issues and potential national security implications, particularly for systems that must be deployed in secure environments. Meanwhile, there is credible evidence that China was the first country to deploy exascale computing systems, targeting China’s own national security interests.
Moreover, technological shifts owing to the end of Dennard scaling and the slowing of Moore’s law have raised questions about the technical and economic viability of continued reductions in transistor sizes and associated growth in computing performance, all at a time when the locus of semiconductor design is now being driven by artificial intelligence (AI) and cloud-computing (Box 2-1) workload needs, rather than predominantly by technical computing.
These shifts in the semiconductor ecosystem and associated market forces, together with rising costs and global competition, are indicative of the challenges now facing NNSA. Simply put, NNSA no longer has the same capability to drive the future of advanced computing as it did in the past. To meet mission needs, NNSA must partner in new and strategic ways to both meet its computing needs and respond to evolving geopolitical circumstances.
TECHNOLOGY DISRUPTIONS
The broad computing environment in which NNSA has acquired and deployed increasingly powerful computing systems as part of the ASC program is now in great flux. Not only are the underlying semiconductor ecosystem and computing hardware and computer system architectures shifting rapidly, so too is the software, along with rapid changes in computing business models and economics. All of these changes, together with shifting mission needs, have profound implications for how NNSA continues to co-design, configure, and deploy future computing systems.
Hardware and Architecture Disruptions
The use of commodity central processing units (CPUs), graphics processing units (GPUs), memory, and storage technologies dominates the computer system structures used today to support high-performance computing (HPC). Increasing the number of cores per chip, compute density, vector processing units, and memory capacity, as well as scaling through parallel processing, adding high-bandwidth memory (HBM), and widening interfaces to improve communications bandwidth—along with building larger systems—have been the primary mechanisms used to increase system performance over the past two to three generations of supercomputers.
Many of these traditional approaches are nearing either physical or practical economic limits. For example, energy dissipation limits on clock operating frequencies have led to only small increases in single-thread performance. As a result, ever larger chip core counts, along with data parallel accelerators (GPUs), have been needed to increase hardware performance, with associated pressure on application developers to increase parallelism and directly manage memory features. Likewise, continued increases in transistor density have become more technically challenging, and the rising cost of semiconductor fabrication facilities has shifted market economics.
Concurrently, the “hyperscalers”—the largest of the cloud service providers—have begun designing their own processors and accelerators, which are not available for purchase. And a growing market focus on improving the performance of machine learning is shifting the locus of hardware innovation. Taken together, the dominant economics of the x86-64 processor ecosystem are at risk, particularly with the rise of ARM, RISC-V, and other custom processor designs. ARM provides a large family of licensable hardware designs and RISC-V is an open architecture, the hardware analogy to open-source software; both support configuration of specialized chips from previously designed components. Last, system cooling capacity, power distribution, energy costs, and carbon impacts have become major considerations in the design and deployment of exascale-class computers. In the midst of these technical changes, the majority of state-of-the-art semiconductors
are now being fabricated offshore, with associated device provenance, national security, and economic competitiveness risks.
Looking forward, there are increasingly near and foreseeable limits on size, performance, and capacity for commonly used computer technologies, mediated by a combination of physical processes and feasible costs. The most significant of these is the slowing of Moore’s law (i.e., the previous doubling of transistor density every 2 years with associated reductions in cost) owing to the technical and economic challenges described below. The second has been the end of Dennard scaling, which showed that transistor shrinkage resulted in other scaling factors leading to faster single-processor performance. Dennard scaling ended in roughly 2004, when power density and leakage current became limiting factors, and the continued increase in transistors were instead used for on-chip parallelism in the form of multicore and manycore (e.g., GPU) designs.1 The following is a list of present technologies, and their associated constraints, that will limit the continued growth in performance and capacity of post-exascale supercomputers:
- Silicon processing limitations will start to limit the minimum practical size of a transistor, logic gate, wire, or device. Although there is still opportunity to continue shrinking semiconductor feature sizes from the 7-nm silicon process technology used in exascale systems—for example, Oak Ridge National Laboratory’s (ORNL’s) Frontier and Lawrence Livermore National Laboratory’s (LLNL’s) planned El Capitan—and the 4 nm in the future Los Alamos National Laboratory (LANL) Venado system, the limits on lithography technology, device isolation, and noise injection are increasingly near. The successful implementation of extreme ultraviolet (EUV) in manufacturing has removed a barrier in lithography resolution for logic and dynamic random access memory (DRAM), but noise, defects, overlay, and edge placement remain challenges. Another constraint for existing silicon processes is metal pitch feature scaling, presently 18 nm, which is projected to reach fundamental limits of around 7–8 nm by the end of this decade. The future will depend in part on a combination of technology advances and economic feasibility (i.e., when and where continued device shrinkage is made possible by markets that can amortize the associated fabrication costs).
- Semiconductor companies have primarily concentrated transistor design on reducing power consumption, rather than maximizing transistor speed, because integrated circuit (IC) power dissipation had become such a major design constraint. Along with the end of Dennard scaling, this
___________________
1 National Research Council, 2011, The Future of Computing Performance: Game Over or Next Level?, Washington, DC: The National Academies Press.
- constraint triggered the rise of multicore chips in the mid-2000s. However, further reductions in contacted gate pitch are essential to increasing transistor density.
- The combination of 3D scaling, both monolithically as a system-on-a-chip (SoC) and heterogeneously as a system-in-package (SiP) will enable compacting more and more devices in a well-defined area/volume, but physical limits of individual devices will eventually be reached owing to topological or electrically related limitations.2
- Heterogeneous multicore processors are being manufactured by major vendors, containing as many as 64 to 80 cores (so-called manycore) to support today’s exascale systems. Multisocket configurations place more cores within the same motherboard. But packaging and system cooling limits will start to constrain how much integration can be achieved.
- Lithographic reticle limits and the yield of working chips per semiconductor wafer place a practical ceiling on how large silicon dies can be manufactured. The emergence of chiplets—integrating multiple chips, often from different vendors and fabrication processes, on a shared substrate—is both a technical and an economic consequence of chip yields and reticle limits. In turn, these limits pushed Cray/Hewlett Packard Enterprise (HPE) to use chiplets in the construction of processing nodes for ORNL’s Frontier.
- A chiplet is an IC that provides a specific, unique, and/or optimized function to an integrated computer system. It is designed to be combined via an IC packaging technology with other chiplets, semiconductor components, and interconnect systems to produce a computing system.3 Chiplets are smaller-scale circuits manufactured separately from the rest of the device, and then integrated into a component or “chip” using an advance packaging and interconnect technology. This allows for each module to be optimized individually, which means that the integrated system can be scaled without affecting performance. By breaking a complex SoC into smaller, modular chiplets and connecting them together, it becomes possible to continue scaling up the number of transistors and other components without hitting the physical limits of a single monolithic chip. Chiplets provide several advantages over traditional SoC designs, including higher performance, improved operating efficiencies, heterogeneous integration, higher yields, and reduced development time, among others.
___________________
2 Institute for Electrical and Electronics Engineers, 2020, “International Roadmap for Devices and Systems,” 2020 Edition, https://irds.ieee.org/images/files/pdf/2020/2020IRDS_ES.pdf.
3 G. Kenyon, 2021, “Heterogeneous Integration and the Evolution of IC Packaging,” EE Times Europe, April 6, https://www.eetimes.eu/heterogeneous-integration-and-the-evolution-of-ic-packaging.
- The use of chiplets, die stacking, and other advanced packaging technologies, versus monolithic SoCs increases the length of the interconnect among computing elements, increasing signal delays, and associated nonuniform memory access (NUMA) effects.
- The use of wider interfaces to increase communications bandwidth between computing components has increased the number of signals and the component pin count required to support these interfaces. Component packaging limits increasingly constrain the performance of chip-to-chip and board-to-board interfaces.
- Many of today’s HPC applications depend on traditional CPUs and GPUs connected to coherent memory hierarchies using very wide interfaces (e.g., thousands of signals), location-specific signal delays (e.g., NUMA effects), and constrained signaling speed (e.g., chip-to-chip). These and other factors limit system memory bandwidth and latency. The increasing disparity between processing speeds and memory access times now challenges von Neumann designs and traditional approaches to parallelism.4
- CPUs and GPUs today implement fixed sets of operations—that is, fixed Instruction Set Architectures that support a broad range of applications. For a sufficiently narrow class of applications, there are proven energy and performance advantages from building hardware that is simplified and specialized to a specific application. This specialization may be done by using either reconfigurable hardware, such as field-programmable gate arrays (FPGAs), or with more dramatic improvements by using application-specific integrated circuits (ASICs). For either case, the challenges of designing the hardware and providing a software stack that can run on such hardware are enormous.
- Solid-state storage devices have dramatically pushed the limits of storage systems performance and become a more integral part of the memory system hierarchy. NAND Flash (a nonvolatile memory technology named for its relationship to the NOT-AND logic gate) will continue to dominate this category. While the number of bits/cell will probably not change (e.g., 3 bits/cell), the continued increase in the number of layers in three-dimensional (3D) NAND technology will provide ongoing increases in capacity. But it is unlikely that performance (latency or bandwidth) will improve at the same rate as capacity (if at all).5
___________________
4 J. Dongarra, T. Sterling, H. Simon, and E. Strohmaier, 2005, “High-Performance Computing: Clusters, Constellations, MPPs, and Future Directions,” Computing in Science and Engineering 7(2):51–59, https://doi.org/10.1109/MCSE.2005.34.
5 C. Monzio Compagnoni, A. Goda, A.S. Spinelli, P. Feeley, A.L. Lacaita, and A. Visconti, 2017, “Reviewing the Evolution of the NAND Flash Technology,” Proceedings of the IEEE 105(9):1609–1633, https://doi.org/10.1109/JPROC.2017.2665781.
These are just a few of the convolved technology and economic challenges faced by the computing industry and especially for the development of future HPCs. These technology shifts are now challenged by the rising cost of semiconductor fabrication facilities and practical yield limits on very large chips. Although there are further opportunities for semiconductor feature size reductions, the future is increasingly determined by a combination of economic feasibility (i.e., what is technically possible is not always economically feasible) and market demands.
Scaling Challenges
Any examination of leading-edge HPC systems over the past decade shows that system scale (i.e., the number of compute nodes) is growing rapidly. This growth is in part owing to a slower growth of individual node performance because of challenges associated with Dennard scaling and the slowing of Moore’s law. Put another way, to increase performance, vendors have found it necessary to increase the absolute size of the systems while also integrating new technology. In turn, these developments have increased pressure on application developers to achieve higher performance by executing applications at larger scale. As noted below, this focus on weak scaling (Box 2-2) brings an additional set of challenges, given the nature of ASC workloads.
Beyond the challenges of weak application scaling, increasing system scale brings other challenges, notably energy and cooling issues associated with the computing system’s physical plant. In addition, the largest computing system installations, whether at DOE laboratories or at cloud computing vendors, have surfaced another, pernicious issue: the presence of silent errors. Given the rising complexity of chips, vendors have found it increasingly difficult to test new chips fully before shipment. The result is infrequent manifestations of bit errors, ones that occur due only to a rare combination of data and instructions. Although uncommon on a single computation node, when assembled in large numbers, as is the case in leading-edge HPC systems, the overall frequency of bit errors can rise to levels that lead to computational errors in the underlying computations.
Last, as the size and complexity of chips has continued to rise, so have their costs and the challenges of ensuring sufficient yield (i.e., the fraction of chips on each wafer that meet performance and correctness specifications). These challenges, plus the desire to integrate features from multiple sources, have driven the adoption of chiplets. The chiplet model brings both new design challenges and opportunities for integration of NNSA-specific workload accelerators.
Impact of Hardware and Architecture Disruptions on ASC Code Performance
Given the challenges enumerated above, Figure 2-1 shows the evolution of key performance indicators for leading HPC systems. This graph reflects hardware disruptions that have emerged over the years. First, peak compute node floating-point performance continues to increase as multicore architectures and other chip-level parallelization lead to increased floating-point capability. However, unless a calculation is completely local to a specific core of a processor, to make optimal use of this increased floating-point capability, other aspects of performance must also increase. Unfortunately, interconnect node bandwidth has increased, but not at a rate commensurate with the increase of floating-point capability. This disparity translates into a steep decrease in the byte per floating-point operation (FLOP) ratio for the overall interconnect. More serious is the decrease of the byte-per-FLOP ratios for overall memory and memory bandwidth. This decrease implies that a growing class of problems are dominated by memory access, and the actual achievable rate of such calculations has decreased over time.
Instructions for loading of data from memory, branching, and array indexing can easily dominate instructions associated with floating-point operations, especially for codes that have a linear amount of work on each data value. The use of optimized data structures and algorithms that have hierarchy or sparsity typically lead to irregular data access patterns and additional indexing data to compactly represent the structure. It may
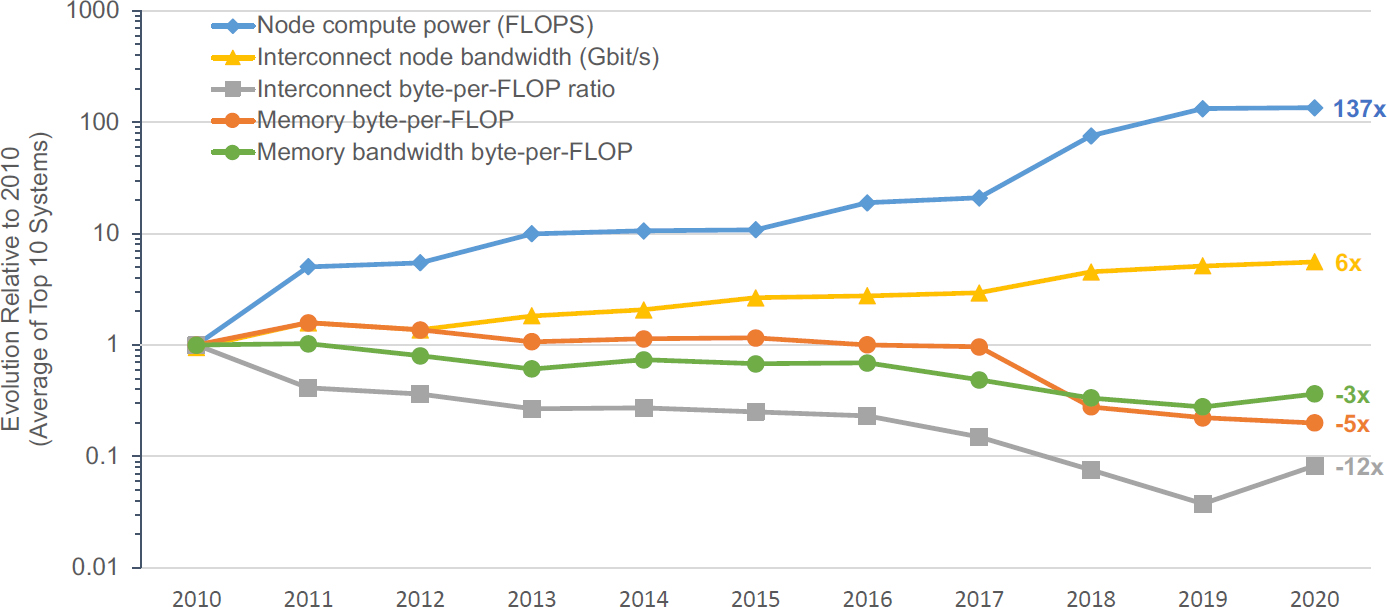
SOURCE: Provided to the committee by LANL. Created by LANL, which built on work by Keren Bergman (Columbia University).
also require significant amounts of data to update a computational cell because of the frequent need to track a large number of dynamic variables in each computational cell.
The overall impact is that the memory system, both the latency for irregular accesses and bandwidth for regular ones, becomes a bottleneck to achieving a substantial fraction of the peak floating-point capability. Various ingenious approaches such as multilevel caches, prefetching, and cache-friendly algorithms have been introduced to alleviate the issue, but cache or high-speed memory capacity also becomes a limiting factor at each level. This issue has been understood for quite some time, but growing memory capacity and bandwidth is often more expensive than growing arithmetic performance, both in terms of cost and energy consumption, so it has been increasingly challenging to keep machines balanced. Even for well-optimized ASC applications, current HPC systems have become increasingly unbalanced in terms of the overall byte-to-FLOP ratio.
Table 2-1 lists some of the common computational motifs used in LANL’s ASC codes. For each motif, the type of parallelism, memory access patterns, and communication patterns, as well as observed bottlenecks are listed. What emerges is that memory bandwidth bottlenecks are apparent for many of the motifs especially if the data structures are dynamic. The yellow- and orange-shaded boxes emphasize that the use of sparse arrays or the need to branch will typically lead to memory bottlenecks. Of course, some of these issues can be addressed via the choice of algorithm, and there is significant ongoing work in reorganizing the data patterns for the various motifs so that they take maximum advantage of the capabilities of emerging HPC architectures such as the availability of GPU accelerators. This has also been a focus of research and development (R&D) with vendor partners.
TABLE 2-1 Common Computational Motifs and Bottlenecks in Los Alamos National Laboratory (LANL) Advanced Simulation and Computing Codes
| Motif | Parallelism | Memory Access | Communications | Synchronization | Bottlenecks | Dynamic (Changing) Data Structures |
|---|---|---|---|---|---|---|
| Stencil operations on structured grids | Data parallel | Regular/dense | Neighboring boundary exchange | Point-to-point messages | Memory bandwidth bound | AMR |
| Stencil operations on unstructured grids | Data parallel | Irregular/dense | Neighboring boundary exchange | Point-to-point messages | Memory bandwidth bound | Sometimes, AMR |
| Particle methods | Data or thread parallel (divergent) | Irregular/sparse | Neighboring boundary exchange Global or subset collectives |
Point-to-point messages Global or subset barriers |
Memory latency, network latency | Yes |
| Sparse linear algebra and nonlinear solvers | Data parallel | Irregular/sparse | Global or subset collectives | Global or subset barriers | Communication bound | Sometimes, AMR |
| Dense linear algebra | Data parallel | Regular/dense | Local operations | N/A | FLOPS, cache | No, static |
| Monte Carlo methods | Data or thread parallel (divergent) | Irregular/sparse | Neighboring boundary exchange Global or subset collectives |
Point-to-point messages Global or subset barriers |
Memory latency, network latency | Generally static |
| Discrete ordinate methods | Data parallel | Irregular/dense | Neighboring boundary exchange | Point-to-point messages | Messaging rate (sweeps), FLOPS, cache | Generally static |
| Machine learning | Data parallel | Regular/dense | Local ops/neighbor coms | Global broadcast | FLOPS, memory bandwidth | No |
NOTE: AMR, adaptive mesh refinement; FLOPS, floating-point operations per second; N/A, not applicable.
SOURCE: From briefing provided to the committee by LANL.
Nevertheless, the discussion above illustrates that for many ASC applications, performance is strongly tied to emerging hardware trends and that post-exascale strategies must be developed with these in mind. While this analysis is specific to the LANL ASC codes, many of the motifs are common across the laboratories, albeit with different emphases as regards their usage.
This issue is further reinforced in examining the percentage of floating points achieved in various applications that make use of the motifs listed in Table 2-1. Table 2-2 was provided to the committee as part of the presentations by the laboratories on code performance. The table lists several LANL codes that utilize important computational patterns relevant to weapons science. The Flag code is used to simulate hydrodynamic phenomena and uses an unstructured mesh in either a Lagrangian mode or in an Arbitrary Lagrangian-Eulerian (ALE) mode. In a fully Lagrangian mode, the mesh moves with the material velocity. In ALE mode, material can flow through the mesh. xRAGE is a 3D radiation hydrodynamics code that uses adaptive mesh refinement to refine important features such as shock waves while also solving for radiation transport. PartiSN computes radiation transport using a discrete ordinates Sn formulation. Last, Jayenne refers to the use of the Discrete Diffusion Monte Carlo method used to speed up radiation transport computations in optically thick media. Table 2-2 shows how well the memory subsystem is performing for each of the applications. The shading indicates whether the specific subsystem is a bottleneck for the computation, with red indicating a serious bottleneck and green indicating lack of a bottleneck. Floating-point performance is rarely a bottleneck, with the exception perhaps of the PartiSN application. In contrast, cache size, memory size, and memory bandwidth play a more significant role. Similarly, Figure 2-2
TABLE 2-2 Architectural Bottlenecks of Applications of Interest Shows That the Memory Subsystem (Caches, Memory Transaction Rate, Bandwidth) Is Often a Bottleneck in Los Alamos National Laboratory Applications
| Memory Subsystem | Floating Point (FP) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| L1 | L2 | L3 | DRAM | DRAM BW | Memory Latency | DP FLOPS | Vectorization | Non-FP | |
| Flag 3D ALE AMR | 3.70% | 11.20% | 96.30% | ||||||
| Flag 3D ALE Static | 2.20% | 7.20% | 97.80% | ||||||
| xRAGE 3D AMR | 6.50% | 14.00% | 93.50% | ||||||
| PartiSN 42 Groups | 26.20% | 90.40% | 72.80% | ||||||
| Jayenne DDMC Holraum | 15.50% | 0.00% | 84.50% | ||||||
NOTES: Red indicates a hardware resource that is heavily utilized, orange indicates moderate utilization, and green indicates light utilization. 3D, three dimensional; ALE, Arbitrary Lagrangian-Eulerian; AMR, adaptive mesh refinement; BW, bandwidth; DDMC, Discrete Diffusion Monte Carlo; DP, double precision; DRAM, dynamic random access memory; FLOPS, floating-point operations per second.
SOURCE: From summary of computational requirements provided to the committee by LANL, LLNL, and SNL ASC teams.
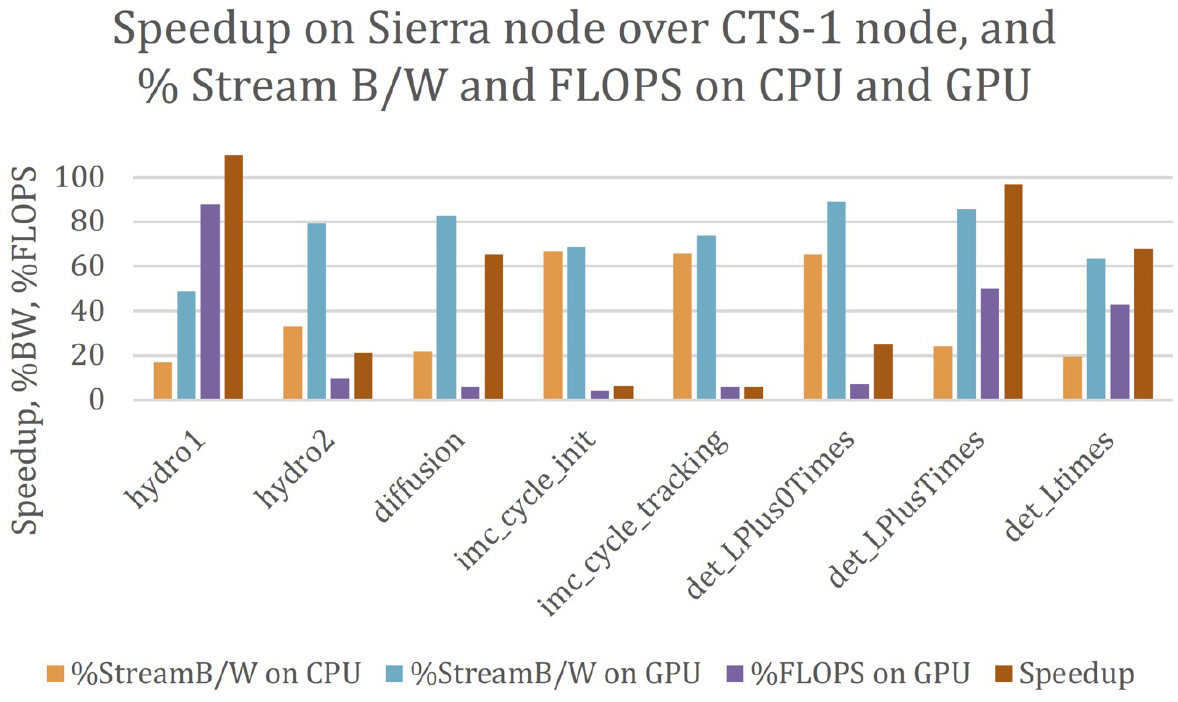
NOTE: CPU, central processing unit; GPU, graphics processing unit.
SOURCE: From summary of computational requirements provided to the committee by LANL, LLNL, and SNL ASC teams.
shows for LLNL codes that, while a number of codes get impressive speedup from using GPU systems, even those are more often limited by memory limits than by floating point.
Recently, LANL has investigated the use of HBM coupled with fourth-generation Intel processors (formerly codenamed Sapphire Rapids). These new processors feature a multidie interconnect chiplet technology and are currently being deployed on the Crossroads ASC platform. In a recent paper,6 LANL demonstrated that the use of these processors with HBM led to roughly an 8× decrease in time to solution on the xRAGE and Flag applications with no change to the codes themselves. This implies that there remain opportunities to further optimize future hardware for workloads relevant to ASC and NNSA.
Software Infrastructure Disruptions
For the past three decades, the global HPC community, including the NNSA and Office of Science laboratories, has leveraged a software and algorithm framework based on machines built as large collections of processing nodes connected via a message passing model called the Message Passing Interface (MPI). The laboratories have invested
___________________
6 G. Shipman, G. Grider, J. Lujan, and R.J. Zerr, 2022, “Early Performance Results on 4th Gen Intel® Xeon® Scalable Processors with DDR and Intel® Xeon® Processors, Codenamed Sapphire Rapids with HBM,” Arkiv:2211.05712v1 [cs.DC].
substantial effort in maintaining and extending MPI as a community standard, adapting to the needs of increasingly complex applications and computer systems while maintaining backward compatibility needed for portable software. They have also built reusable libraries, scientific software frameworks, and applications on this model and have leveraged international community efforts in open-source software for scientific computing and general-purpose software.
During that same period, as noted earlier, processing nodes have gone through multiple transformations, from single processors to multicore, manycore, and accelerators, with the introduction of complex nonuniform shared memory systems and software-managed memory. Thus, while the internode programming model has been relatively stable, the node-level algorithm and software model has gone through multiple disruptions, the most recent being the GPU-accelerated nodes in U.S. exascale systems. The laboratories have also developed new programming abstractions, influenced community standards such as OpenMP and C++, and worked with vendors to ensure that their applications would be well-supported on each platform generation. In addition, they created an environment for software development, curation, and distribution of exascale tools and applications.
The exascale software challenges offer a foreshadowing of the future, as each GPU vendor uses a different native programming language, and different hardware features are exposed to software even across generations of GPUs by the same vendor. This requires rewriting code and sometimes different fine-grained parallel algorithms. The DOE ECP (Box 2-3) addressed these challenges with R&D investments at all levels of the software stack, but without an established plan to sustain the DOE Office of Science investments even for software maintenance, much less for improvements required for future applications and systems. Moreover, these challenges pale in comparison to the software challenges associated with emerging specialized processors, which require tools to design and test the hardware and their own implementation of standard programming languages or their own language. Although large commercial entities have the resources and expertise to design and implement such programming systems for large markets, the resulting programming systems are sometimes not well-suited to the NNSA workloads. NNSA should attempt to team with these vendors and seek adaptation where needed.
The growth of infrastructure as a service (IaaS) and platform as a service (PaaS) over the past 20 years has enabled a large number of enterprises to develop large applications using new techniques for marshaling large amounts of computing resources and allowing significant communication between those resources. Starting with the goal of making systems easy to program and from the premise that hardware components fail, PaaS models provide a high-level programming interface similar to a small subset of collective operations in MPI, but with much more complex implementations to hide hardware failures, variable hardware speeds, and other system artifacts from
the programmer. PaaS programming systems such as MapReduce, Hadoop, and Spark are significantly more resilient to hardware and software faults than MPI, but also incur substantial runtime overheads. Over time, the PaaS models have evolved to be more efficient, and some of the latest models used for compute-intensive problems such as training deep neural networks have used MPI or similar message passing models that relax resilience requirements. There is both a significantly broader economic base of support for these PaaS models and a growing workforce that can be tapped when applying it. Therefore, while the value of these PaaS models for NNSA HPC application workloads is unclear, they may be useful for some mission applications, and in any case represent a growing disruptive force that will need to be either exploited or be in competition with by post-exascale computing programs of NNSA.
Last, tied in part to the commercial IaaS and PaaS ecosystems, there are entirely open-source software efforts to build higher-level programming models, such as Julia and Python, as well as new tools for collaborative science. This rich software ecosystem is evolving quickly and expansively, and it is largely, although not entirely, disjoint from that used by NNSA.
MARKET ECOSYSTEM DISRUPTIONS
When DOE’s Accelerated Strategic Computing Initiative (ASCI)7 and Advanced Scientific Computing Research (ASCR)8 programs began, they were focused on leveraging the commodity computing ecosystem, itself driven by the market economics of complementary metal-oxide semiconductor (CMOS) microprocessors. At that time, several vendors developed and marketed high-end computing systems for both DOE needs and the broader scientific and engineering technical computing market.
The Sandia National Laboratories (SNL) ASCI Red system, built by Intel in late 1996, exemplified this approach by combining large numbers of x86-64 processors via a message passing network to become the first terascale computing system. Other ASC computing platforms from IBM (e.g., ASCI White, Purple, Roadrunner, and Sequoia) leveraged a combination of commercial microprocessors (IBM POWER) or custom, low-power processors (Cell and BlueGene), increasingly with GPU accelerators.
Although the ASCI and ASCR programs benefited immensely from leveraging the economically dominant computing ecosystem of the 1990s and early 2000s, that ecosystem has shifted markedly since the programs began. In the United States, HPE remains as the only U.S. high-end HPC integrator, with HPE having recently acquired Cray. In turn, IBM has largely exited the high-end HPC market, choosing to focus on more profitable market niches. As reflected in recent TOP500 lists, the leading-edge HPC market is now largely a monoculture, dominated by x86-64 processors and primarily by NVIDIA GPU accelerators.
Concurrent with vendor consolidation at the leading edge, extant and new hardware vendors have shifted their focus to IaaS cloud computing and AI. By market capitalization and annual infrastructure investments, Amazon Web Services, Microsoft (Azure), and Google (Cloud Platform), now have much greater economic influence on future computing system design (i.e., microprocessors, accelerators, network interfaces, and
___________________
7 Department of Energy Defense Programs, 2000, “Accelerated Strategic Computing Initiative (ASCI) Program Plan,” Office of Scientific and Technical Information (OSTI), https://dx.doi.org/10.2172/768266.
8 Department of Energy, 2023, “Advanced Scientific Computing Research,” Office of Science, https://www.energy.gov/science/ascr/advanced-scientific-computing-research.
storage) than do either the traditional HPC vendors or DOE. Equally important, these companies focus on selling value-added services, not hardware, although all of them develop custom hardware to support their software services.
Similarly, machine learning hardware and software are now a major focus of venture investments (e.g., Cerebras, GraphCore, Groq, Hailo, and SambaNova). Put another way, the locus of financial investment has shifted from traditional CPU vendors to that of cloud service providers and innovative machine learning hardware startup companies.
Simply put, the scale, scope, and rapidity of these cloud and AI investments now dwarf that of the DOE ASCR and ASC programs, including ECP. Tellingly, the market capitalization of a leading cloud services company now exceeds the sum of market capitalizations for traditional computing vendors. Collectively, this combination of ecosystem shifts increasingly suggests that NNSA’s historical approach to system procurement and deployment—specifying and purchasing a leading-edge system roughly every 5–6 years—is unlikely to be successful in the future.
Looking forward, it is possible that no vendor will be willing to assume the financial risk, relative to other market opportunities, needed to develop and deploy a future system suitable for NNSA needs. Second, the hardware ecosystem evolution is accelerating, with billions of dollars being spent on cloud and AI hardware each year. NNSA’s influence is limited by its relatively slow procurement cycles and, compared to the financial scale of other computing opportunities, is also limited in its financial leverage. Third, and even more importantly, the hardware ecosystem is increasingly focused on cloud services and machine learning, which overlap only in part with NNSA computing application requirements.
The implications are rather clear, especially when considering the mandates of the newly passed Creating Helpful Incentives to Produce Semiconductors (CHIPS) and Science Act (discussed below). NNSA and other federal agencies seeking to deploy next-generation HPC systems will need to develop new approaches to shaping the underlying technologies and partnering with vendors, other agencies, and academia. Potential examples include much deeper, earlier, and more robust co-design than has occurred to date, new partnerships with cloud vendors to jointly develop and build new computing technologies, and interagency collaborations and strategic government investment in promising technology areas and vendors.
Supply Chains, National Security, and the CHIPS and Science Act
Recent chip shortages have highlighted U.S. dependence on the global semiconductor ecosystem for critical semiconductor components, both for consumer products and for mission-critical national security interests. This shortage was triggered in part by the pandemic but also by technology shifts as U.S. semiconductor vendors focused on chip
design and relied on offshore vendors for fabrication. Concurrently, many of these semiconductor foundries moved to EUV fabrication processes to continue increasing transistor density.
Intel’s lag in adopting EUV has been cited as one of the underlying reasons for the current fabrication advantages of TSMC. Meanwhile, both NVIDIA and AMD, as fabless designers, depend on TSMC and GlobalFoundries for chip fabrication. Recognizing the severity of the chip shortage, DOE invoked national security priorities to ensure parts availability for its exascale systems.
As a result of these trends, the United States now finds itself significantly dependent on global supply chains for advanced semiconductors, with only roughly 10 percent of the global supply of chips and a limited fraction of the most advanced chips produced domestically.9 To satisfy its need for the advanced semiconductors so critical for HPC, the U.S. government must ensure the viability of domestic suppliers—semiconductor design, chip fabrication, system design, and system integration.
Recognizing both these economic and national security risks, exacerbated by pandemic-related supply chain delays, the U.S. government responded by passing the 2022 CHIPS and Science Act.10,11 Among its many provisions to strengthen U.S. competitiveness, the CHIPS and Science Act appropriates about $39 billion for semiconductor manufacturing facility incentives, about $2 billion for legacy chips used in automobiles and defense systems, and about $13.2 billion for R&D and workforce development. In response, Intel, Micron, Qualcomm, and GlobalFoundries, among others, have announced new plans for domestic semiconductor fabrication facilities.
The CHIPS and Science Act also requires recipients of U.S. financial assistance to join an agreement prohibiting certain material expansions of semiconductor manufacturing in China. In addition, the Department of Commerce recently imposed restrictions on exports to China, targeting chips key to deep learning and HPC.12
International Supercomputing Landscape
While there is general agreement that the LINPACK benchmark13 is not the metric to use to determine appropriate computer system capabilities for NNSA, the TOP500 list based on LINPACK has been a useful tool to track trends globally and to gauge international
___________________
9 Semiconductor Industry Association, 2021, “State of the U.S. Semiconductor Industry,” https://www.semiconductors.org/wp-content/uploads/2021/09/2021-SIA-State-of-the-Industry-Report.pdf.
10 CHIPS and Science Act, P.L. 117-167.
11 “White House Fact Sheet on CHIPS and Science,” 2022, https://www.whitehouse.gov/briefing-room/statements-releases/2022/08/09/fact-sheet-chips-and-science-act-will-lower-costs-create-jobs-strengthen-supply-chains-and-counter-china.
12 Department of Commerce, 2022, “Commerce Implements New Export Controls on Advanced Computing and Semiconductor Manufacturing Items to the People’s Republic of China (PRC),” Press Release, October 7, Bureau of Industry and Society, https://www.bis.doc.gov/index.php/documents/about-bis/newsroom.
13 “The LINPACK Benchmark,” 2022, TOP500, https://www.top500.org/project/linpack.
supercomputing progress starting in 1993. In June 2002, when the Japanese Earth-Simulator leapfrogged the previous fastest machine—a U.S. machine at LLNL, ASCI White—by 5× to become number one on the TOP500 list, the United States took notice, as did the world. Beyond the benchmark results, the machine was very well-suited to complex modeling and simulation problems and, for example, was sought after by the global climate modeling community. By November 2004, the United States had retaken the lead with a machine twice as fast, BlueGene/L at LLNL, which proved to be capable of solving several groundbreaking science and NNSA problems. The United States remained number one with that LLNL system, followed by Roadrunner at LANL and Jaguar at ORNL, until China took the number one spot in November 2010. Each of these major systems was an enormous research and engineering accomplishment, reflecting both a national commitment to scientific computing and the ability to assemble the team and technologies necessary for such a deployment.
China had been telegraphing its intent to enter the supercomputing race for a number of years, but even when it reached the number one spot in 2010 there was skepticism that China could compete more broadly with well-established HPC investments in the United States, Japan, and Europe. Since that time, it is apparent that China has been investing toward world leadership in supercomputing by building a substantial HPC infrastructure in terms of workforce and companies, developing indigenous hardware, software, and system capabilities and focusing on key applications. As a reflection of that broader program, in June 2022, China had 35 percent of the machines on the list, mostly displacing U.S. machines, which had only 25 percent of the systems but historically has averaged 50 percent. China continues its progress, published under the National High-Tech R&D Program also known as the 863 Program, which is implemented in successive 5-year plans. It is now widely rumored that China has two exascale computing platforms that have not been “officially” reported or entered into the TOP500 competition, and several AMC Gordon Bell Prize submissions (used to measure performance on applications) were run on one of those systems, OceanLight, with impressive results. Although there is limited information on how China is using its supercomputers, HPC could facilitate many of China’s military modernization objectives, including upgrading and maintaining nuclear and conventional weapons.14
Japan focuses on a tiered computing infrastructure: one flagship computing system, 13 general-purpose HPC centers, and a number of other centers dedicated to specific user communities, all accessible to the science community. In 2002, the flagship computer was the Earth Simulator. Nine years later, in June 2011, the K computer
___________________
14 U.S. House of Representatives, 1999, “High Performance Computers,” Chapter 3 in Report of the Select Committee on U.S. National Security and Military/Commercial Concerns with the People’s Republic of China, H. Rept. 105-851, January 2, https://www.govinfo.gov/content/pkg/GPO-CRPT-105hrpt851/html/ch3bod.html.
was number one on the TOP500 list and another 9 years later Fugaku was number one. Fugaku was developed by extensive co-design of custom processor hardware and system architecture, driven by development of target applications in several priority areas of benefit for society. As of June 2022, Fugaku continues to rank number one on the High Performance Conjugate Gradients benchmark list, a benchmark more reflective of memory bandwidth than the TOP500.
Europe is the other major player in supercomputing. There have been several projects to organize supercomputing applications within Europe. The Partnership for Advanced Computing in Europe provides coordinated HPC infrastructure for large-scale scientific and engineering applications, particularly for industry, across three tiers. The European High-Performance Computing Joint Undertaking is a joint initiative between the European Union, European countries, and private partners to further develop a supercomputing ecosystem that supports development and use of demand-oriented and user-driven applications across a large number of public and private users. In terms of hardware, Europe is pursuing a hybrid strategy, developing some custom hardware but also leveraging U.S. semiconductor designs.
Given restrictions related to U.S. technology, which have increased even as this report was being prepared, China has had little choice but to strengthen its independent research and technical innovation, striving to develop domestic replacements for all the necessary hardware, system software, and application codes for advanced computing. Hence, China’s recent exascale systems (OceanLight and Tianhe-3) have been based on domestically designed chips. The chips in these systems, like those in the U.S. exascale systems, depend on fabrication facilities in Taiwan.
Given the international interest and developments, maintaining U.S. computing leadership for national priorities in a globalized world will require increasing investments and attention.
RETHINKING INNOVATIONS, ACQUISITION, AND DEPLOYMENT
Given the dramatic changes in hardware—driven by a combination of semiconductor constraints, the cloud service provider market, and deep-learning workload demands; new software models arising from the explosive growth of infrastructure and platform services and deep learning; and computing ecosystem economics accruing from these hardware and software forces—it seems likely that NNSA will need new approaches. Among these is the need for better metrics, ones that emphasize reducing time to solution for real applications (e.g., moving the time to solution for important hero calculations from months to days). Today, NNSA applications are most often constrained by
memory access bandwidth, not simply by floating-point speeds. An overemphasis on the latter is counterproductive. Instead, NNSA should emphasize time-to-solution and identify the memory access motifs core to key applications as part of an end-to-end, hardware-software, co-design strategy.
Hardware and Architectural Innovation and Diversity
It is possible that the next generation of HPC systems can be built using evolutionary variants of system architectures, component technologies, interfaces, and memory hierarchies, albeit likely with high acquisition costs and limits on the fraction of peak hardware performance delivered to applications. Given current technology challenges and market uncertainties, several alternative approaches are the subject of active research.
Unlike the transition from custom vector processing to commodity, CMOS-based massively parallel systems, there is less consensus about the most effective approaches for future computing systems. It is difficult to predict where the promise lies, whether it is in sustaining CMOS scaling, disruptive computing models (quantum, neuromorphic, or resistive computing), materials (graphene, nanotubes, or diamond transistors), or new structures (3D die stacking, photonics, or spintronics). Evolutionary technology advances will likely include incremental CMOS device scaling, a transition from fin-shaped field-effect transistors (FinFETs) to gate-all-around transistors, chip stacking and 3D chip technologies, targeted wafer-scale devices, and increased use of silicon photonics. As CMOS device scales approach one nanometer, the manufacturing challenges of existing CMOS scaling will continue to mount.
Concurrently, industry standards around packaged chiplets (e.g., via the Universal Chiplet Interconnect express [UCIe]) offer the opportunity for packaging heterogeneous components, including custom-designed accelerators that target elements of NNSA computational workloads. In this spirit, continued exploration of architectures specialized to common computational motifs as well as low-precision arithmetic and its interplay with algorithms and applications opens additional possibilities.
Last, more speculative approaches include alternative semiconductor device designs based on graphene or carbon nanotubes, coupled with novel computing structures and architectures. Other challenges lie in chip-to-chip signal delays, manufacturing yields, process control, and system cooling. As the emergence of chiplets shows, the ability to integrate different processes (e.g., memory, processors, and accelerators) as if they were on a single chip, while maintaining high capacities and density, opens new opportunities for architectural specialization and performance optimization, targeting key workloads.
Similarly, the increased use of HBM, a high-speed interface for 3D-stacked synchronous dynamic random-access memory, can and has reduced memory access
latencies, increased data throughput, and reduced energy requirements for selected applications. Further exploration of new memory technologies, both DRAM and resilient, high-performance, nonvolatile memory will be key to ameliorating the large disparity between processor cycle times and memory access times.
Increasingly, processor and system architectures can no longer be developed independently. Software constructs like programming languages, tools, communications protocols, and operating environments will need to be developed in conjunction with new processor and system architectures. For example, the integration of FPGAs into processing units (CPUs, GPUs, etc.) could allow algorithm optimization using on-demand, integrated hardware/software compilation. The ability to compile hardware and software in on-demand or in real-time could significantly change the way future systems are constructed and operated. In any case, co-development of components to support post-exascale systems will be necessary to realize the operational efficiencies and performance needed for future applications of interest.
Software Innovation
The NNSA laboratories, as well as partners in the Office of Science, have been innovators in software development (Box 2-4), especially in the ECP. This project includes a large applications development effort focused on developing mission-critical applications that could effectively use exascale hardware and take advantage of state-of-the-art algorithms and software techniques. The software technologies and co-design elements of the project were valued based on their adoption by applications, yielding a vertically integrated software stack focused on meeting application requirements in which interoperability of the different components was a key feature. ECP also led to wider adoption of good software engineering practices such as regular regression testing and continuous integration development workflows within the HPC community. It is important that in the post-exascale era these innovations be continued and expanded.
Despite these important advances, there is an urgent need embrace state-of-the art industrial practices and toolchains, as well as higher-level abstractions and toolkits, to improve developer productivity, while also improving product quality, reducing development time and staffing resources, increasing software sustainability, and reducing the cost of maintaining, sustaining, and evolving software capabilities.15 With the prospect of increasing hardware specialization to meet performance objectives and mission needs, abstractions that enable performance optimization while isolating hardware details and maximizing developer productivity are increasingly critical. In addition, the divergence of
___________________
15 M.A. Heroux, L. McInnes, D.E. Bernholdt, A. Dubey, E. Gonsiorowski, O. Marques, J.D. Moulton, et al., 2020, “Advancing Scientific Productivity Through Better Scientific Software: Developer Productivity and Software Sustainability Report,” Office of Scientific and Technical Information, https://dx.doi.org/10.2172/1606662.
NNSA programming environments and tools from the mainstream creates both sustainability risks and workforce recruiting and retention challenges. While NNSA prioritizes performance and performance transparency with languages such as C++ and parallel extensions, much of industry and university education now focuses on languages like Java, Python, or Rust with their managed runtime systems, as well as machine learning frameworks that hide parallelism. Scientific productivity has been identified as one of the top 10 exascale research challenges,16 and software productivity (the effort, time, and cost for software development, maintenance, and support) is a critical aspect of scientific productivity. A significant challenge is the need for high-quality, high-performance, reusable, sustainable scientific software, and programmer productivity tools so that scientists can collaborate more effectively across teams. Thus, although general and actionable metrics have proven difficult to define, an overarching focus on productivity and sustainability is essential to making clear decisions in the face of both highly disruptive architectural changes and demands for greater interaction across distinct teams and reliability of results.
In the post–Moore’s law era, it will be increasingly important to use architectural innovations as well as software that can take advantage of that hardware, as parallelism at different levels and in new forms will only increase, leading to rapid changes in software and algorithms. Absent high-level, flexible toolkits and abstractions, the software burden for optimized applications, libraries, and programming tools will also grow as if hardware becomes more specialized to different workloads.17
___________________
16 Department of Energy, 2014, DOE Advanced Scientific Computing Advisory Subcommittee (ASCAC) Report: Top Ten Exascale Research Challenges, February 10, https://www.osti.gov/servlets/purl/1222713.
17 C.E. Leiserson, N.C. Thompson, J.S. Emer, B.C. Kuszmaul, B.W. Lampson, D. Sanchez, and T.B. Schardl, 2020, “There’s Plenty of Room at the Top: What Will Drive Computer Performance After Moore’s Law?” Science 368(6495):9744, https://www.science.org/doi/abs/10.1126/science.aam9744.
System Acquisition Innovation
As noted above, when describing ecosystem disruptions, it seems likely that NNSA will need to innovate in the mechanisms it uses to acquire systems in the post-exascale era. There are at least four potentially viable paths to consider:
- Adapt the current model of procuring every few years a leading-edge system from the commercial HPC market. This will require even tighter cooperation with the limited pool of potential vendors and, if government restrictions on the use of non-U.S. vendors continue, will likely result in very few competent bidders, perhaps zero or one. This will almost certainly result in increased acquisition cost and increased risk to timely delivery.
- Become a self-integrator of systems. The laboratories have already taken over a significant portion of the software stack in producing leading-edge systems. That trend could be increased to the point where an external integrator only integrated the hardware components of the systems. Carrying this further, it would be possible to have the laboratories shoulder the entire burden (potentially including the use of custom hardware), but that would require significant (and very difficult to achieve) increases in laboratory staff expertise. Arguably, the design and deployment of SNL Red Storm followed some elements of this path.
- Cultivate a new relationship with the cloud vendors, each of which do custom hardware design and significant self-integration. The benefit here is that one could attempt to leverage their workforce. For security reasons, NNSA will need to use private cloud deployments rather than a public cloud. Risks include vendors’ potential lack of interest in the more niche HPC market.
- Use the defense industrial base. Generally, this would result in contractual arrangements based more on cost-plus models than fixed deliverables at a price, much as is done for military equipment. There are many companies that integrate very complex systems who could take on work of this sort, but the final net costs would be significantly higher than today. This is owing to both the lack of competitive contracting mechanisms and the lack of a commercial market over which to amortize the development costs.
Cloud Computing as an Alternative
For many organizations, cloud computing is a viable and cost-effective alternative to acquiring and operating computing systems, especially when compared to operating small clusters or individual servers at many sites across an organization, when workload varies
widely over time—for example, owing to seasonal sales demand or when “burst demand” exceeds local capacity. NNSA’s HPC computing is centralized at a small number of sites, operates in a classified environment, and requires highly integrated computing systems configured to extreme scale and other NNSA requirements—with a nearly unlimited set of computational problems, even their largest systems run at high utilization. Traditional pay-as-you-go cloud computing in public clouds is not an effective alternative. However, NNSA can consider private-cloud options,18 consider various partnering opportunities with cloud providers, and examine opportunities to adopt ideas from cloud computing, which will be a powerful market force going forward, both in talent and in computing technology.
The cloud ecosystem offers the potential for significant innovation in NNSA’s use of software, both because of the rate of innovation occurring in the cloud sector and also because of the models of resilience and management they offer. Commercial cloud data centers exceed the scale of DOE’s facilities, and there is growing technical convergence in the need for high-speed networking and integration for large machine-learning workloads. Second, as previously described, the hyperscaler cloud providers are engaged in custom hardware development and will be more influential on the computing supply chain, including the semiconductor market, than NNSA alone or in partnership with the Office of Science. Moreover, as an increasing fraction of the workforce is being trained to use cloud services, there is also the potential to attract and leverage this experience, or conversely the inability to draw such talent if NNSA’s environment is viewed as outdated or less productive than tools and systems used in the cloud.
ADAPTING TO A CHANGING COMMERCIAL ENVIRONMENT
The current NNSA procurement model for advanced computing systems is predicated on a vibrant commercial computing market whose interests and products align with the national laboratories’ scientific computing needs. This is increasingly not the case.
The burgeoning PC market, which originally birthed the “attack of the killer micros,” is increasingly stagnant, in counterpoint to the rapid growth in the smartphone, embedded devices, and data center markets. The former two trade off performance for low power and size, while the latter is increasingly dominated by the hardware demands of the cloud hyperscalers and targeted accelerators for deep learning, of which GPUs are but one instance. NNSA does not have sufficient market influence on processor and
___________________
18 Department of Defense, 2022, “Department of Defense Announces Joint Warfighting Cloud Capability Procurement,” December 7, https://www.defense.gov/News/Releases/Release/Article/3239378/department-of-defense-announces-joint-warfighting-cloud-capability-procurement.
memory vendors to compete with hyperscalers, and the reduction in the number of HPC system integrators raises other risks.
Reflecting the technical and financial challenges of a post–Moore’s law environment, where it has become impractical to build ever-larger, higher-performance, monolithic chips, the semiconductor market is shifting rapidly to multiple chip packaging—chiplets that integrate multiple, heterogeneous chips via a high-bandwidth interconnect and package. Simply put, chiplets are a technical solution to a minimax problem—minimizing overall costs while maximizing chip yields and delivered performance. In turn, this has created innovation opportunities to develop targeted, ASICs that integrate with the extant ecosystem.
This is in marked contrast to the earlier “killer micro” world, where developers of custom processors faced daunting technical and economic challenges, needing to develop a complete software and hardware environment and keep pace with the relentless performance increases of the mainstream microprocessor market. In the past, many custom designs were tried and failed. Today, with slowing microprocessor performance increases and the chiplet disaggregation, it is both economically and technically viable to design and integrate such custom accelerators, and many startups are doing so, targeting the AI/deep learning market.
In this greatly changed marketspace, HPC customers and the HPC industry can no longer dictate product specifications. The leading-edge HPC market is too small, the procurements are too infrequent, and the financial risk to vendors is too high when compared to the size and scale of the hyperscaler and deep-learning markets. The message is clear. DOE must pursue several strategies directions concurrently: “join them,” “beat them,” and pursue a new procurement model.
First, NNSA must embrace the existing AI and hyperscaler hardware market, not as a risk-mitigation strategy, but as a mainstream approach to its next-generation hardware. This almost certainly means new types of vendor partnerships, where NNSA is the collaborative partner rather than the procurement driver. In so doing, NNSA may need to reconsider which mission problems can benefit from advanced computing and develop mathematical methods, algorithms, and software that match emerging commercial AI hardware attributes. This could be for components of simulation or data analysis problems by deploying AI methods. With a deeper bench of in-house AI methods and hardware experts, they may also find opportunities to influence commercial designs in ways that would benefit both commercial and NNSA workloads. This “join them” strategy leverages the economic trajectory of the current market, just as NNSA did during prior hardware ecosystem transitions. Without such engagement, NNSA may be missing the next computer revolution.
Second, NNSA must expand (and create where necessary) integrated teams that identify the key algorithmic and data access motifs in its applications and begin collaborative ab initio hardware development of supporting chiplet accelerators, working in concert with both startups and larger vendors. More than incremental code refactoring, this must be a first principles approach that considers alternative mathematical models to account for the limitations of weak scaling. This “beat them” strategy acknowledges that targeted, custom hardware specialization is required to meet NNSA’s future HPC performance needs, something the mainstream market alone is increasingly unlikely to provide.
Last, the NNSA procurement model must change. Fixed-price contracts for future, not-yet-developed products have created undue technical and financial risks for NNSA and vendors alike, as the technical and delivery challenges surround early exascale systems illustrate. A better model embraces current market and technical realities, building on true, collaborative co-design involving algorithms, software, and architecture experts that harvests products and systems when the results warrant. However, the committee emphasizes that these vendor partnerships must be much deeper, more collaborative, more flexible, and more financially rewarding for vendors than past vendor R&D programs. This will require a cultural shift in DOE’s business and procurement models.
OVERARCHING FINDING: The combination of increasing demands for computing with the technology and market challenges in HPC requires an intentional and thorough evaluation of ASC’s approach to algorithms, software development, system design, computing platform acquisition, and workforce development. Business-as-usual will not be adequate.
FINDING 2: The computing technology and commercial landscapes are shifting rapidly, requiring a change in NNSA’s computing system procurement and deployment models.
FINDING 2.1: Semiconductor manufacturing is now largely in the hands of offshore vendors who may experience supply-chain risk; U.S. sources are lagging.
FINDING 2.2: All U.S. exascale systems are being produced by a single integrator, which introduces both technical and economic risks.
FINDING 2.3: The joint ECP created a software stack for moving systems software and applications to exascale platforms, but although DOE has issued an initial call for proposals in 2023, there is not yet a plan to sustain it.
FINDING 2.4: Cloud providers are making significant investments in hardware and software innovation that are not aligned with NNSA requirements. The scale of these investments means that they have a much greater market influence than NNSA in terms of both technology and talent.
Given the changing ecosystem and hardware markets, it is critical that NNSA rethink its approach to hardware and software acquisition; its market influence, already small, is declining rapidly. All of these shifts are convolved with global concerns about economic, political, and national security dependence on offshore semiconductor fabrication facilities and the slowing or end of Moore’s law. As device feature sizes approach 1 nanometer, vendors have increasingly shifted to chiplet designs—mixing and matching multiple chips on a single substrate—to minimize costs and maximize yields. This creates both opportunities to integrate a custom chiplet suited for NNSA workloads and the consequent challenges of system heterogeneity and software support.
It would be a mistake to claim that NNSA’s stockpile stewardship computational models require completely sui generis components, but neither are they fully compatible with the economic mainstream. Substantial customization, with the concomitant nonrecurring engineering costs, will be essential if NNSA is to raise application efficiency and elevate sustained performance. Much as NNSA once worked collaboratively with vendors such as IBM and Cray to design and develop custom computing systems matched to NNSA needs, NNSA must again embrace collaborative ab initio system design, rather than specification development and product procurement.
Such a model is likely to require more internal expertise in computer architecture, greater embrace of cloud software models, specification of novel and semi-custom architectures, end-to-end hardware prototyping at substantial scale for evaluation and testing, and partnership with nontraditional hardware and software vendors, notably AI and other hardware startups and cloud vendors. Most importantly, this new approach will almost certainly require (1) a new mix of laboratory staff skills, (2) continuous prototyping, and (3) substantially more investment than has been true in the past.
RECOMMENDATION 1: NNSA should develop and pursue new and aggressive comprehensive design, acquisition, and deployment strategies to yield computing systems matched to future mission needs. NNSA should document these strategies in a computing roadmap and have the roadmap reviewed by a blue-ribbon panel within a year after publication of this report and updated periodically thereafter.
RECOMMENDATION 1.1: The roadmap should lay out the case for future mission needs and associated computing requirements for both open and classified problems.
RECOMMENDATION 1.2: The roadmap should include any upfront research activities and how outcomes might affect later parts of the roadmap—for example, go/no-go decisions.
RECOMMENDATION 1.3: The roadmap should be explicit about traditional and nontraditional partnerships, including with commercial computing and cloud providers, and academia and government laboratories, and broader cross-government coordination, to ensure that NNSA has the influence and resources to develop and deploy the infrastructure needed to achieve mission success.
RECOMMENDATION 1.4: The roadmap should identify key government and laboratory leadership to develop and execute a unified organizational strategy.




























