
Algebraic Representation of Storage and Retrieval Languages
R.A.FAIRTHORNE
The fundamental elements of any system for storage and retrieval are the entries, bookings, or postings which ultimately connect specifications of requirements with the stored items. At any moment the system may be regarded as a double-entry table with components of specification naming the rows, say, and component of stored items naming the columns. Existence of a posting at the intersection of a row and a column denotes that the corresponding component of specification should invoke the corresponding component of stored item. Thus, given the terms in which requests must be specified and those in which items must be marked and the existence and non-existence of postings, this table describes completely the classificatory or taxonomic structure and properties of the system as it stands at the moment. That is, it shows what you should get when you ask for what; not the way in which you get it.
If, additionally, the double-entry table gives numbers representing such things as frequencies of requests using various terms, it will then describe completely the statistical “informational” behaviour of the system, regarded from outside as a data-processing “black box.” From this point of view any further information is irrelevant. Either it is about the particular means by which the retrieval system achieves the current input-output behaviour or it is about the rules by which new postings are assigned when new items enter the system. The former is beyond the scope of black-box theory; the latter is at the moment beyond its powers.
Even when black-box theory becomes strong enough to cope with growing systems, that is, with intensional or “semantic” information as well as with extensional or “selective” information, it will concern itself only with the assignment and distribution of postings. It cannot concern itself with various ways in which they can be written down, partitioned, and manipulated.
In this sense, the retrieval system is a set of rules for assigning postings that connect textual content with descriptive terms, both terms and content being
R.A.FAIRTHORNE Royal Aircraft Establishment, Farnborough, England.
assumed determined or determinate. The system can be realized in practice in as many ways as ingenuity suggests or means allow. However, if one is concerned both with what one gets when one asks for what, and how to get it, the way in which postings are written and manipulated is of the same stature as the way in which they are assigned. A system without means of retrieval is as useless as means of retrieval without a system. Retrieval devices can act only on marked material objects in ways depending on the marks, the material objects being partitions of the double-entry table of postings, the marks being the postings written in some form acceptable to the device. If, for instance, the available clerical devices are suited to finding the common membership of given lists, we partition the double-entry table along the rows (e.g., as “aspect” or “feature” cards) and write the postings in a way congenial to the comparing and recording organs (e.g., as an aperture or a microprint in a “dedicated position”). If the system demands both common membership of given lists and lists of total membership, partitioning along both rows and columns should be possible, and the postings must be written in some at least ternary (three letter alphabet) script. At all times the way in which postings are written, or into which they may have to be translated, must reconcile the clerical means of retrieval and the fundamental semantic structure of the system. Subject classification by itself can retrieve nothing.
Characteristics of a working system therefore reflect the way in which the postings are spelt and manipulated as well as the structure of what they refer to and how they refer to it. For example, the marked physical differences between predominantly “analogue” and predominantly “digital” calculating devices are due entirely to the ways in which they represent numbers. Also the difficulty of classifying some devices either as “digital” or as “analogue” reflects the fact that there are as many methods of naming numbers, intermediate between “analogue” (repetitive) and “digital” (combinatorial), as one cares to think up.
A clear-cut example of the way in which one talks about things dominating the characteristics of the things talked about is the “law of logarithmic distribution of initial digits.” Examine almost any extensive collection of numerical data, such as tables of statistics, that are written in variable-word-length decimal radix form; that is, with the usual convention that 0 is never used initially and therefore, of necessity, using an eleventh character, the “space,” to mark the end (or beginning) of a number word. About a third of the entries will be found to begin with a 1; about a sixth to begin with a 2. In general, the fraction of entries that begin with a d is approximately log10 [(d+1)/d]. This has been, and sometimes still is, interpreted as a law of nature governing the distribution of magnitudes in the physical world. If so,
the law must be awkward to enforce, because the distribution changes if the observer chooses to write down the magnitudes in duodecimal, say, instead of decimal radix notation. If he chooses to use binary radix variable-word-length notation every word begins with a 1. In general, if you use radix r, the fraction of entries that begin with a d is approximately logr [d+1)/d].
This is not just a manifestation of the known fact that a straight-line law connecting any empirical data always can be achieved with the aid of suitably scaled logarithmic paper and a robust conscience. A little consideration shows that in a run of consecutive integers from one to some power of ten, initial digits are distributed uniformly over 1, 2,· · ·, 9. If the run does not stop at a power often, the lower initial digits must predominate. Deeper analysis shows that with reasonably large samples, repetitions being allowed, from a large enough initial segment of the integers, the logarithmic relation quoted above is a good approximation (3, 4). The approximation is remarkably insensitive to bias in the sample, the sensitivity vanishing as the radix of representation decreases to two.
In short, this logarithmic law is a direct consequence of our spelling rules for number names. Not obedience, but disobedience, is evidence for particular extensional characteristics of the set of numbers named or the method of selecting them. Similar relations would be expected, and are found, with any vocabularies built up combinatorially from alphabets, phrases built up from vocabularies, or any structurally equivalent naming system; e.g., bibliographies built up from references. The best known and studied is the Zipf-Mandelbrot relation, e.g., Brillouin (2), between word-rank and word-frequency in ethnic languages. Since phrases in ethnic languages are effectively number words of low radix, this relation is significantly affected only by such pathological characteristics of language as restricted vocabulary and elaborate syntax (Hebrew, Basic English, children’s talk) and unrestrained word-order (as in some mental disorders and many of the mathematical models used to derive the law theoretically). The proportions of very common and very rare words do, however, cause local but significant deviations from the general relation. (The latter needs only the hypotheses that, on the average, less costly signals are used oftener than more costly; and that signals of equal cost are used equally often.)
Important to retrieval are the Bradford law of scattering of bibliographic references and its implications (1, 5). It deserves attention and extension, for it may apply to greater or lesser extent to, for instance, the distribution of postings over “aspect” or “feature” cards and, conversely, the incidence of “aspect,” “features,” or to some extent even the more fundamental types of descriptors attributed to items. If the last are used as an index of subject matter,
possibly only their deviations from some Bradford-Zipf-Mandelbrot relation are significant.
Many other clerical activities are affected as much by spelling rules of the names as by properties of the nominata. For instance, sorting and, a fortiori, marshalling. Sorting is essentially segregation of all items that are homonymous with respect to certain varieties of names. Unless the radix or size of alphabet of the names is not less than the number of varieties into which the items are to be segregated, sorting must be iterated according to partial marks, usually the characters of successive digits. Clearly the efficiency of the process, in terms of number of passes or of loading of pockets, is as vulnerable to the vocabulary of marks as it is to the composition of the collection to be sorted. The latter is outside one’s control and, usually, one’s knowledge. The former is not.
Marshalling, which entails assembly as well as segregation, is even more at the mercy of the vocabularies of marks. One has only to compare the (hypothetical) task of marshalling decimally marked wagons on a trident with the same task with the wagons marked in ternary radix notation. The marks, operations, and facilities then have a common structure. Marshalling may be regarded as a particular case of transcription from a vocabulary in which the words represent initial rank to another in which the same words represent the final rank.
Some of the quoted examples deal with combinations of symbols and operations, some with permutations, some with both. Structurally there is no fundamental difference; permutations and combinations are reciprocally related according to interpretation. For instance, the apertures in a Taylorstencil “aspect” card can be usefully interpreted as either a particular combination of items, or as the binary radix representation of the serial number of that combination in a certain enumeration, unpunched sites being interpreted as 0’s and punched sites as 1’s. The enumeration is made by associating unity with citation of the first item, two with citation of the second, four with citation of the third and, in general, 2n-1 with citation of the nth item. The serial number of a particular combination of items is found by adding the numbers associated with the components. The entire enumeration is obtained from the expression
(1)
where ar denotes citation of the rth item.
On multiplication we get terms of the type ![]() in which the coefficient represents the combination of items and the exponent its serial number. Proof that each of the 2n combinations has a unique serial number is elementary.
in which the coefficient represents the combination of items and the exponent its serial number. Proof that each of the 2n combinations has a unique serial number is elementary.
But expression (1) is not essentially different if we write it as
(2)
order being preserved in multiplication so that, for instance, 1 in the third term denotes occurrence of a 1 in the third binary place. On multiplication we get terms such as 00· · ·01101 x13, the coefficients being the name of the exponent in binary radix constant-word-length notation.
Suppose the aspect cards were only just large enough to accommodate the particular combinations written on them; e.g., lengths of perforated tape trimmed after the last entry. They then could be interpreted as the serial numbers of the combinations expressed in variable-word-length binary radix notation. Either interpretation has the structure represented by
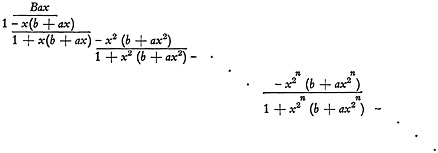
(3)
B denotes either the beginning of a new combination or a space, that is, a special character or characters indicating the beginning (or end) of a new word. Note that there is now no coefficient of x0 (i.e., of unity) in expression (3) for we can have neither an aspect card for an empty aspect on the one hand, or name for zero on the other. To deal with these the system would have to provide unsystematic treatment, represented by the addition to (3) of a constant term not deducible from the structure of the rest of the expression.
This is an unlikely form for a Taylor system, but as soon as such a system demands more than one aspect card for an aspect its structure has to reflect characteristics of both (1), or (2), and (3). The words now vary in length, but not by one letter at a time. Elaboration of this would merely complicate the present discussion.
Suppose now that the cards are able to display more than two states at a site. For instance, the references might not be to individual papers but to the number of papers by individual authors, or to whether they had written for or against a particular aspect, or not at all. In the last case, the card must be able to display three distinct states at each site; in general, it will be required to assume any one of r1 distinct states in the first site, r2 in the second, and so on. The structure is then represented by
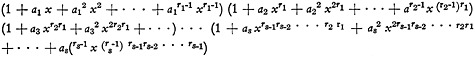
(4)
or
(5)
Both (4) and (5) are the same initial segment of the expansion in positive powers of x of
(6)
If we concern ourselves with a1, a2,…as, only (that is, if we put all at, t>s, equal to zero), the relevant segment will be the first rs rs-1 rs-2· · ·r2 r1 terms of the expansion, which will give all the selections as coefficients and their unique serial numbers as exponents of x. This is also the greatest number of distinct states the aspect card can display, so the coefficients of higher powers represent physically unrealizable states, because they involve factors of form apt, where t is greater than rp−1.
Expression (6) generates upon expansion the representation and enumeration of any set of selections allowing up to r1 things of the first kind, r2 of the second, and so on.
This may be interpreted, not as an extension, but as a degeneration of the one-or-none binary selection represented by (1). We may lack either the means or the need to distinguish between separate items of the same more general type; for instance, between individual papers by the same author or, when we are concerned only with the number of letters in a word, between the different sorts of letters (other than spaces or their equivalents).
Suppose that, in expression (1), a1, a2, a3, say, represent individual papers by the same author. Only four states now need to be enumerated, (no-paper through three-papers), instead of eight (the number of ways of making selections from three distinct objects). The only powers of x needed for the enumeration are, therefore, zero through three. So, in the first instance, we can write the appropriate terms of (1) as
(1+a1 x)(1+a2 x)(1+a3 x) (7)
On multiplication the coefficient of x2, say, is
(a1 a2+a1 a3+a2 a3) (8)
But we are not able to distinguish between a1, a2, a3, so this must become
(a2+a2+a2) (9)
where a2 represents the statement “There are two papers written by author a,” because we can no longer say which the two are. Making this statement
three times over is the same (in the sentential calculus) as making it only once. So, because of our reduced discrimination, (9) finally becomes
(a2 v a2 v a2)=a2 (10)
where v is to be read as the symbol for disjunction of statements.
When the a’s have suitable interpretations, such as patterns that can overlap or coincide, we would use ∪, the symbol of set addition, instead of v. Whatever the interpretation, or the symbol, it must formally reflect the type of blurring due to our coarsening the discrimination. The plus sign, +, used in these expressions denotes simply that the items separated by it are distinguishable somewhere within the system by means available to the system, but not necessarily that they are distinguished. For instance, we might be interested only in the number of papers by given authors, but be compelled to use Taylor cards that distinguished between individual papers. Then we would, as before, equalize appropriate exponents (serial numbers of component items) of x in the factorized expression (1) because their coefficients are not to be distinguished in the new enumeration. Nevertheless they remain distinct patterns on the card, and will be so read by the usual sensing devices. So we cannot simplify (8) to (9). Such bracketed terms are the synonyms of the corresponding serial numbers (exponents of x), and the sensing device must have some means for dealing with such synonyms, a complication reflected by the structure of (7) being more complicated than the structure of the expression using relations such as (10); to wit
(11)
If the sensing means detected a single, a pair, or a triplet of a’s without taking into account the identities of the individual items, (9) would have to be written
3a2 (12)
because the pair response would have to be given to three distinct patterns. The expression representing this part of the system is then
(1+ax)3 (13)
This is the least complicated expression possible if the original card, or system, distinguishes between each item and you must extract only the number of items of given sorts. That is, if the system contains synonyms with respect to the characteristics that interest you.
The coarsening of discrimination detailed above is compactly displayed by writing the relevant factors of (1) in the form
(14)
This becomes (7), which can be written
(15)
The next stage, (13), can be written
(16)
The final stage is
(11) bis
In general, confounding groups of items produces the factors of expression (5). Therefore the parent function is, as asserted above, a degenerate case of the denominator of (1) when written in the form of (14). From the latter can be produced, by coarsening of discrimination and truncation of the power expansion (i.e. reducing the range of the vocabulary), all radix type representations on the one hand or selections with repetition on the other.
The denominator is thus the basic generator of an indefinitely large family of finite vocabularies having some structural characteristic in common. We should note that the first n terms of such a vocabulary are given by an expression of the form
(17)
where the summation is over the roots, 1/as, of the denominator considered as a polynomial in x. The A’s are functions of the roots only, and are found by the usual Euclidean division algorithm.
This partial fraction representation is the basic representation of vocabularies and will be arrived at eventually however tortuous the route; e.g., by detour through finite difference equations representing the recurrence relations between coefficients of successive powers of x.
The word corresponding to the nth item of the vocabulary is thus the sum of the coefficients of xn in the expansions of the partial fractions. For arithmetical features of words, such as relative frequency or number of synonyms, or when the word can be regarded as coexistence of distinguishable parts, the summation can be represented by the plus sign. Other occasions may demand other forms of addition; ordinal, cardinal, set, lexicographic, etc.
The discussion has been illustrated in terms of Taylor cards. It is equally illustrated by the number representations on a pinwheel desk calculator, of which Taylor cards are irrevocable versions, structurally. Here a displayed configuration, 0282 say, is to an observer who can recognize the characters one of the permutations, with repetitions, of the ten numerals 0 through 9. nternally, it is a particular selection which has combined no teeth on the
thousands’ wheel with two teeth on the hundreds’ wheel, eight on the tens’, and two on the units’. To a certain degree the two vocabularies are structurally the same. We can substitute a38, say, for 8 in the coefficient of x80 and, in general, we can equate coefficients of like powers of x. We can do so only because the mechanism is a physical operator for physically equating coefficients. The vocabularies are structurally the same, but the alphabets are not. Users would resent having to count the number of teeth rather than to recognize the numerals; they would also resent having to pay for a character reader to recognize the numerals rather than for pinions to count the number of teeth. Words are composite (many-lettered) or irreducible (letters of an alphabet) relative to a particular means of observation; the properties are not absolute. Also they are relative to the spelling rules. So long as n+1 is represented by means of one more tooth, and one less blank, than the representation of n, the tooth-setting device is a ten-word vocabulary using a dyadic (two-letter) alphabet. If the assignment of teeth were arbitrary, so that the number of teeth representing n+1 could not be deduced from that for n, it becomes a ten-word vocabulary formed from single letters of a ten-letter alphabet. The mechanism for equating coefficients is correspondingly complex. More elderly computors may recall the weird cam-operated keyboard dials of the first motorized Mercedes Euklid calculaters.
The x’s themselves may be the names of some other nominata, instead of being purely the vehicles of some enumeration. Often they represent the input unit pulses. The mechanism described cannot distinguish between n and n+10000k, where k is any integer. Therefore the factor (1−x10000) must be inserted in the denominator in order to provide the appropriate homonyms. A negative power in the numerator will deal with whatever convention is used for negative numbers.
So far we have shown: first, that the properties of the way in which we talk about things can distort or obscure the properties of the things talked about. Second, by possibly tedious discussion of simple examples, that the various ways in which clerical systems use signals within a system are greatly simplified if the various notations and operations have structures easily derived from some common abstract structure.
Therefore, to separate, analyze, or synthesize clerical aspects of retrieval we need some model which will represent vocabularies (i.e., ordered or partially ordered sets of words) in structure as well as in extension, to any degree of approximation, discrimination, or range. Such models should cope with extensions of vocabulary by creating longer words through multiplication or repetition (exponentation of alphabets and vocabularies), the multiplications being cardinal, ordinal, or, in general, lexicographic. Also they should cope
with extensions of vocabulary by phrase-formation; that is, using the vocabulary as the alphabet of higher vocabularies by means of hierarchies of spaces, which are characters which, by rule or the nature of their representations, cannot occur adjacently (e.g., a duration greater than some given minimum and, perhaps, less than some maximum which is less than twice the minimum). The models should deal quantitatively with magnitudes that are additive over word or phrase, such as length in terms of number of digits or of physical length or duration. Also with magnitudes multiplicative over word or phrase, such as relative frequency when letters or words are independent. For retrieval notations partial or simple orderings and set operations on characters must be coped with. Finally, the overall algebraic manipulations of the representation should have clerical interpretations in terms of discrimination, matching, segregation, transfer, or retention.
This is a large order, and no model is likely to satisfy all of it all the time. It will be quite useful if it satisfies some of it some of the time. Such a model is best regarded as a process of generating either samples or the whole structure of the vocabulary with such detail as is necessary or possible. Communication theory favours the stochastic model, which generates samples, because the statistical features of its material are usually the only ones accessible to it. Retrieval systems deliberately use (or create) systematic features in their material and devise systematic notations and operations to reflect them. For this the best model is an expression that can generate the systematic vocabulary and in itself display the general structure. The more systematic the orthography and assignment of magnitudes, the closer an approximation such a model will be.
In the course of this discussion quite a promising type of model has emerged, taking into account only the orthography, not the numerical magnitudes that may be associated with the words. We will now look at these. Already we have seen that it is consistent to take, for instance, the 3 in (12) as indicating that the a2 can occur in three ways. In general, such coefficients indicate the number of times the word has occurred or the relative frequency of its occurrence in a particular population of words from this vocabulary. If the coefficient is the relative frequency, then the relative frequency of joint occurrence, or product, of two independent words is the product of their several frequencies.
If we list only the relative frequencies of the words of a vocabulary, without representing their spelling, we can write it as
(18)
pn being the relative frequency of the nth word.
The series can be represented by a continued fraction of form
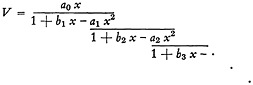
(19)
This is, with changed notation, the standard J-fraction expansion of the series. There are many algorithms for computing it, e.g., Wall (6). All basically are the Euclidean G.C.D. algorithm applied to polynomials, corresponding exactly to the algorithm for purely numerical continued fractions.
When (19) is evaluated by known means as far as the nth partial denominator, 1+bnx, we get a fraction whose numerator and denominator are polynomials of degree n in x. Expansion of this fraction by long division yields a power series that coincides with (18) through ![]() . We can therefore obtain a polynomial fraction that approximates the frequencies to as many terms as we like.
. We can therefore obtain a polynomial fraction that approximates the frequencies to as many terms as we like.
For this procedure to work, the p’s must satisfy certain broad conditions, besides being all non-negative. In general you cannot use it to obtain some special structure by systematically putting some p’s equal to zero.
Next, the fraction can be represented by n partial fractions as in (17), the roots, 1/a, of the denominator being now numbers. The entities taken as roots in (17) are letters in some generalized sense. Study is needed to show how and when they become clerically realizable.
Each partial fraction yields, on expansion by long division, a vocabulary whose rth word has relative frequency ar. V is the sum of such vocabularies so pr is the sum of the rth powers of the n roots for all r not greater than 2n. This is therefore the solution of the moment problem for any finite segment of V.
Formally, the same applies to the alphabetical roots of (17). If any of the a’s can be interpreted as an available character (sign-design), the denominator containing it generates the simple repetitive vocabulary whose nth word is ‘aaaa· · ·(n times) preceded, or followed, by a space character, which is here an unmarked area of paper of indefinite extent. Nevertheless, it is a character, because a definite choice is needed to produce it as an alternative to an a. All signalling systems must have alternative choices, from their nature, and an r character alphabet offers at most r−1 choices. Thus all alphabets must have at least two characters, one of which must be of space type (unless it is known that the alphabet is to be used once only for one one-word message).
Such repetitive synonym-free dyadic vocabularies are clearly the simplest of all types of vocabulary. They are, of course used explicitly by discrete (digital)
analogue systems, and implicitly by non-discrete (continuous in the sense of blurred) analogue systems.
Thus the individual words and associated quantities of an ordered vocabulary are formally equivalent to the moments, numerical and alphabetical, of some function of order, of which the partial fraction representation, as in (17), is the discrete Stieltjes’ transform. We will therefore refer to expressions of this type as “Stieltjes’ representations” or “Stieltjes’ transforms” of the vocabularies. They are closely allied to the discrete spectra, autocorrelation functions, and other representations used to analyze the physical aspects of signals.
The value of Stieltjes’ transforms of vocabularies is no less because the dyadic vocabularies are not directly realizable; e.g., a character may be negative, formally or numerically. The original denominator may be reducible to alphabetical roots that are real for some clerical devices, but not for others. How many, what kind, and by what means they are to be realized should be a profitable field of investigation.
Though these and other fractions have been said to generate vocabularies by long division, it must be recalled that this phrase is purely the mathematical interpretation of a clerical routine for making marks in a certain way (writing a string of n a’s as an is in this context merely an inessential abbreviation). Multiplication means only that one makes a list of all combinations of marks, one from each factor, and orders this list according to the rules for the particular type of multiplication. Differentiation is meaningless here in terms of an approach to a limit; in combinatorial analysis, as here, it is a discriminating operator as its name implies, e.g., a (dx3/dx) lists all ways of substituting an a for an x in xxx; to wit, axx+xax+xxa, which may sometimes be abbreviated legitimately to 3ax2. Similarly, the derivative of a polynomial cannot here be interpreted as the slope of a curve, but is the remainder after two successive divisions by a suitable divisor (i.e., the confluent divided difference). In short, mathematical algorithms, including computer programs, are clerical algorithms for making marks. Mathematical concepts are concepts, and therefore not accessible to clerical operations though applicable to them on occasion. Data processing systems, for instance, can handle neither numbers nor information, they can handle only signals, which are physical events. Numerical and informational concepts, however, can or should be handled by those who handle data processing systems. We are therefore entitled to use, for instance, clerically unrealizable repetitive vocabularies so long as they originate in and go to form consistent and useful clerical results.
So far the exponents of x in such expressions as (18) have denoted rank in general. Words often may have to be ranked by some property of words, such as the number of letters or, in general, the cost. This can be represented by an
extra coefficient uC, say, whose exponent is an integer representing the cost. The costs are assumed to be positive integral multiples of some common unit. With this representation, if the cost of a word is the sum of the costs of the letters of which it is the product, the exponent of u in the word will be the cost of the word. Other additive costs can, when necessary, be represented by the exponents of other extra coefficients.
For instance, the coefficient of uCvn in the expansion of
(20)
is the list of all N-letter words costing exactly C, together with their relative frequencies, that can be formed from an alphabet of r letters (including the space B and special initial characters). The number of such words is found by putting the p’s and a’s equal to unity. If we are not interested in the number of letters and the costs simultaneously, we can put v equal to unity. Then all N-letter words will be given as the coefficient of un after the letter costs, the c’s, have all been made equal to unity. The number of such words will be found by putting the a’s equal to unity also.
It is easy to see that the denominator of (20) will the have only one positive root, lying between 1/2 (for an infinite alphabet) and 1 (for a dyadic—one letter and one space—alphabet). The repetitive vocabulary generated by the corresponding partial fraction models the average relation between rank and cost; the vocabularies generated by the other roots correspond to oscillations about the average. This is true whatever the numerator, and therefore whatever the length of segment of V considered. The amplitudes and similar parameters do vary with the range of vocabulary considered, which manifests itself in the numerators of the partial fractions. In (20) the primes in the numerator denote frequencies and costs of initial letters or letters used initially. This gives a slightly better model, but does not affect the structure or roots of the basic representation.
In turn, we can use V as an alphabet from which phrases are generated, just as the alphabet of V is generated as a vocabulary of words formed of sub-alphabetic components, if we have a suitable facsimile device that accepts these components as an alphabet. If all such phrases are permissible, frequencies multiplicative, and costs additive, the phrase-generating expression is
(21)
where B2 is a second order space (e.g., a stop) of indefinite cost; P1, k1, the frequency and cost of the first order space B; V′ the vocabulary, with frequencies and costs, of initial words or words used initially.
This hierarchy can be extended upwards or downwards indefinitely. Always, however, it can be represented as the sum of dyadic repetitive alphabets (of the same hierarchic order).
This paper has outlined a possibly useful method of representation in which vocabularies and hierarchies of vocabularies are regarded as the sum, in any consistent sense, of repetitive dyadic vocabularies, not necessarily clerically realizable. It generalizes and unifies many special methods, such as various algebraic identities used traditionally to demonstrate number representations, and models used in investigating some properties of ordinary language. Here it can be used to discover the sympathetic magic principles (like-produces-like) characteristic of linguistic systems and to apply them usefully to more systematic vocabularies. We have seen that to some extent it can cope, though not simultaneously, with additive and, in general, modular properties such as cost and selective information, and with the partial orderings and looser generalized operations, synonymity and homonymity, that are essential to retrieval.
The next stage is to deal with the vocabularies of operations for transforming vocabularies. These are the vocabularies whose words, possibly partially ordered strings of letters, are routines for sorting, marshalling, transcribing, and so forth, vocabularies. In general they are the hierarchies of programming.
At most this paper is therefore only a programme, with a hint as to how the programme may be achieved. The applications exhibited have been very simple, though not trivial, and with results already known. The mathematics is commonplace and elementary. However, the paper is not intended as a contribution to mathematics, but as a contribution to documentation. Here, especially in retrieval areas, the principle of sympathetic magic, as well as of the unsympathetic variety, is peculiarly powerful. Systems founded on neat and economical theory are neat and economical in other ways.
REFERENCES
1. BRADFORD, S.C., Documentation, London; Crosby Lockwood, 1948.
2. BRILLOUIN, L., Science and Information Theory, Chap. 4, New York, Academic Press, 1956.
3. FURRY, W.H., and HURWITZ, H., Distribution of Numbers and Distribution of Significant Digits, Nature 155, 52/53 (1945).
4. GOUDSMIT, S.A., and FURRY, W.H., Significant Figures of Numbers in Statistical Tables, Nature 154, 800/801 (1944).
5. VICKERY, B.V., Bradford’s Law of Scattering, J. Document. 4, 198/203 (1948).
6. WALL, H.S., Analytic Theory of Continued Fractions, Chap. XI, New York, Van Nostrand, 1948.














