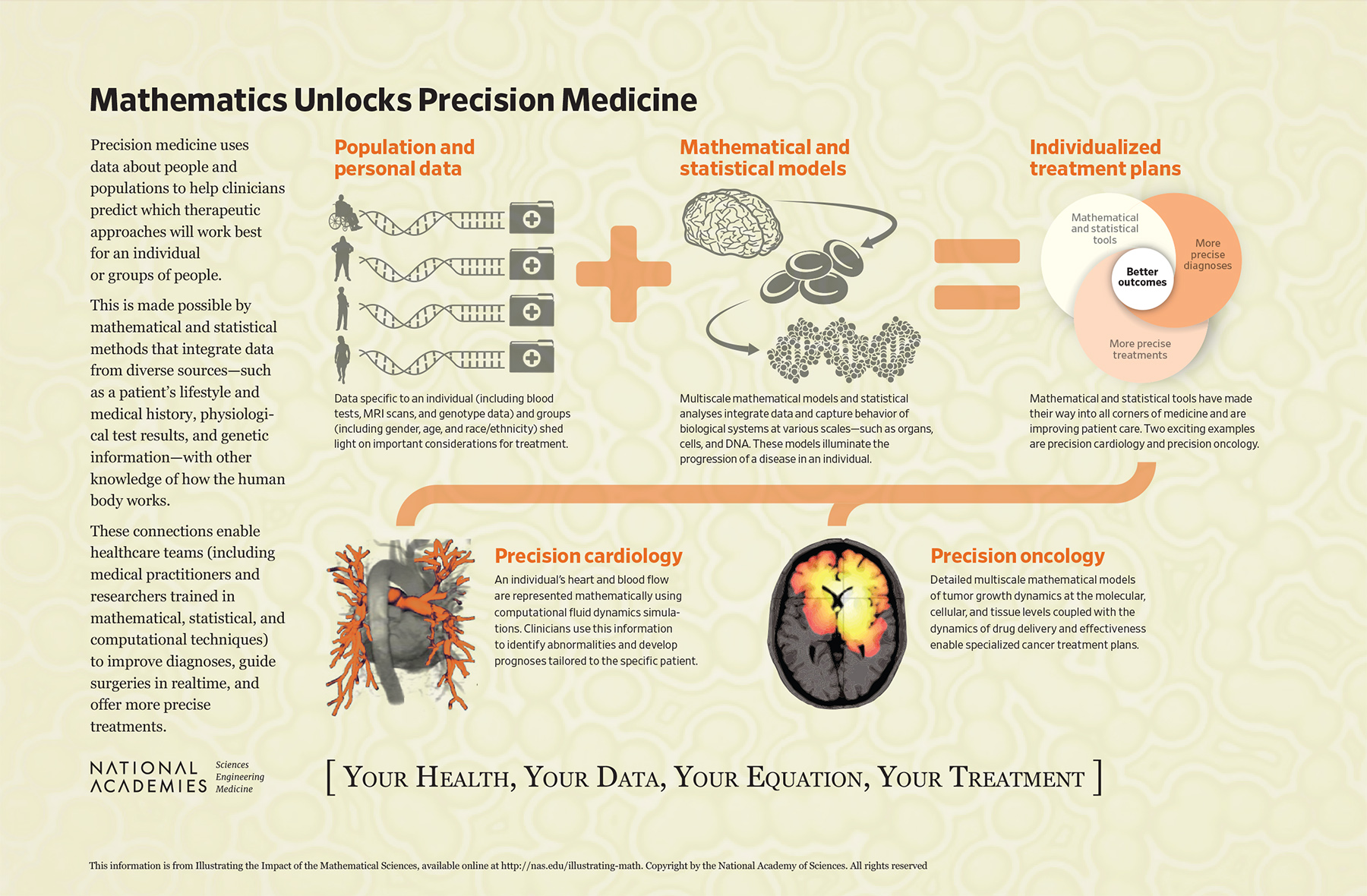
Mathematics Unlocks Precision Medicine
Human diseases are complex and can vary significantly from one person to the next. Despite this uniqueness, an individual’s treatment is often determined by what worked best on average for a large group of patients. Precision medicine aims to reshape medical care away from what worked best for an “average patient” to a customized approach that better takes into account the individual. To make this vision a reality, researchers and clinicians are using mathematical and statistical tools to make sense of increasing amounts of medical data and are working toward tailoring medical treatments to better serve individual patients.
Using Population and Personal Data to Provide Insights
Advances in the collection and availability of diverse data about individuals and large groups of people pave the way for personalized medical treatments. But first, these data have to come together to tell a more complete story.
Lots of data are collected on an individual in the course of modern medical care. For example, an individual’s electronic health records will likely include results from blood tests over time, diagnostic tests (such as magnetic resonance imaging [MRI] or other imaging tests), family histories, genetic screening, and other personal information (such as age and occupation). On their own, these data can give a good indication of an individual’s current health, but more information is needed to predict what the future may hold.
Data on larger groups of people can hold insights into, say, the typical course of an illness or the general effectiveness of a drug or other treatment. These data are collected in many ways, including clinical trials that test a treatment hypothesis, observational studies that identify trends in collections of individual records, and other public health data available to local, state, and national policy makers.
Using Mathematical and Statistical Models to Connect the Pieces
Mathematical and statistical models can pull available information together in several ways. The first approach is to use statistical models to integrate a patient’s diagnostic data with available public health data. This can help to determine how well an individual fits within the broader population, and therefore how generalizable the “average” treatments and prognoses might be. For example, if the patient is part of a demographic group that is not well represented in clinical trial data, the results from that trial might not be meaningful for the patient.
The second approach is to use mathematical models to capture existing knowledge of an underlying disease. This can include the biological behavior of, say, an organ, a particular type of cancer, or physical mechanisms of drug delivery.
The third approach is to bring what is known about the individual (through the combined personal and population data) and underlying behavior of a disease and use a mathematical model to help guide more personalized treatment. Today, this is typically done on sub-populations or groups of patients with similar characteristics. But the goal is to be able to model these treatments for individuals quickly to provide the best possible care.
Modeling in Action
Mathematical and statistical modeling have had remarkable success across medical fields, and this is particularly true in cardiology and oncology.
In cardiology, mathematical models of the heart can abstract the essential features of the geometry, tissues, electrical impulses, and chemistry. When this information is paired with an individual’s data, clinicians and researchers can better understand how the heart is operating, identify abnormalities, and personalize therapies, without the need for invasive tests or procedures.
In oncology, detailed mathematical models give insights into how a cancer-fighting drug works within the body and how a tumor evolves over time. These models capture physical and biological behavior across multiple physical scales.
Modeling approaches such as these can help inform diagnoses, assess interventions, select treatments for individual patients and, ultimately, improve patients’ health and well-being.